V8, the JS runtime underneath Chrome, Edge, Node, Deno, and Electron, got some useful improvements for developers.
One is a new simple (single-pass SSA, CFG, IR builder) JIT for short-lived programs like command-line tools or serverless functions. Called Maglev.
I’m very interested how it will stack up against AWS’s low-latency runtime (LLRT) that will be compatible with “some of” Node, also optimized for start-up time instead of long-running applications which benefit more from a more complex and rigorous optimizing JIT.
Another bonus from v8 12.4 is new JS language features:
– Array.fromAsync() takes an iterable of promises and returns an array of awaited items in serial fashion. It can be used with async generator functions too.
– New Set methods like intersection, union, etc. I assumed these would have to get added at some point because it’s so obvious to have them and they’re a great DX in langs like Python and Kotlin.
– Iterable helper methods. These let you do some more functional-style things with iterators like .filter(), .map() and all sorts of things you can do on arrays. But an iterable can be an infinite generator so these methods get applied as you grab more values from the iterator (with .next()) instead of all at once as on an array.
Based Jensen Huang, CEO of Nvidia, which is one of the largest companies in the world by market cap now, said this February that people should stop learning to code. He was making the point that people will soon be able to instruct computers with natural human language to get what they want out of them. If you’re a younger person or a parent, it’s worth asking now, is there still value in learning to program a computer or get a computer science education?
I respect Jensen enormously and believe he is worth taking seriously, even if he used to slang 3D-Sexy-Elf boxes to gamers. Also to recognize his bias as the manufacturer of the picks and shovels for the current venture gold rush and his incentives to pump up the future perceived value of his company’s stock, if such a thing is even possible at a P/E of 73.
My perspective is as a software practitioner, having been a professional software “engineer” for two decades now, consulted and built companies on software of my design, and writing code every day, something I do not believe Mr. Huang is doing. Let’s start with a little historical perspective.
Past Promises To Eliminate Programmers
Programming real physical computers in the beginning was a laborious process taking weeks to rewire circuitry with plugboards and switches in the early ENIAC and UNIVAC days.
As stored-program machines became more sophisticated and flexible, they could be fed programs in various computer-friendly formats, often via punched cards. These programs were very specific to the architecture of the computer system they were controlling and required specialized knowledge about the computer to make it do what you wanted.
As the utility of computers grew and businesses and government began seeing a need to automate operations, in the 1950’s the U.S. Department of Defense along with industry and academia set up a committee to design a COmmon Business-Oriented Language (COBOL) as a temporary “short-range” solution “good for a year or two” to make the design of business automation software accessible to non-computer-specialists, across a range of industries and fields to promote standards and reusability. The idea was:
Representatives enthusiastically described a language that could work in a wide variety of environments, from banking and insurance to utilities and inventory control. They agreed unanimously that more people should be able to program and that the new language should not be restricted by the limitations of contemporary technology. A majority agreed that the language should make maximal use of English, be capable of change, be machine-independent and be easy to use, even at the expense of power.
The general idea was that now that computers could be instructed in the English language instead of talking to them at their beep-boop level, and programming could be made widely accessible. High-level business requirements could be spelled out in precise business-y language rather than fussing about with operands and memory locations and instruction pointers.
In one sense this certainly was a huge leap forward and did achieve this aim, although to what degree depends on your idea of “widely accessible.” COBOL for business and FORTRAN for science and many many other languages did make programming comparably widely available in contrast to before, although the explosion of personal computers and even more simplified languages like BASIC helped speed things along immensely.
Statistically, the number of people engaged in programming and related computer science fields grew substantially during this period from the 1960s to the year 2000. In the early 1980s, there were approximately 500,000 professional computer programmers in the United States. By the end of the 20th century, this number had grown to approximately 2.3 million programmers due to the tech boom and the widespread adoption of personal computers. The percentage of households owning a computer in the United States increased from 8% in 1984 to 51% in 2000, according to the U.S. Census Bureau. This increase in computer ownership correlates with a greater exposure to programming for the general population.
Every advancement in programming has made the operation of computers more abstract and accessible, which in my opinion is a good thing. It allows programmers to focus on problems closer to providing some value to someone rather than doing undifferentiated mucking about with technical bits and bobs.
As software continues to become more deeply integrated into every aspect of human life, from medicine to agriculture, to entertainment, the military, art, education, transportation, manufacturing, and everything else besides, there has been a need for people to create this software. How many specialists will be needed in the future though?
The U.S. Bureau of Labor Statistics projects the demand for computer programmer jobs in the U.S. to decline 11% from 2022-2032, although notes that 6,700 jobs on average will be created each year due to the need to replace other programmers who may retire (incidentally, COBOL programmers frequently) or exit the market.
So how will AI change this?
Current AI Tooling For Software Development
I’ve been using AI assistants for my daily work, including GitHub’s Copilot for two and a half years, and ChatGPT for the better part of a year. I happily pay for them because they make my life easier and serve valuable functions in helping me to perform some tasks more rapidly. Here’s some of the benefits I get from them:
Finishing what I was going to write anyway.
It’s often the case that I know what code needs to be added to perform some small feature I’m building. Sometimes function by function or line by line, what I’m going to write is mostly obvious based on the surrounding code. There is frequently a natural progression of events, since I’m giving the computer instructions to perform some relatively common task that has been done thousands of times before me by other programmers. Perhaps it’s updating a database record to mark an email as being sent, or updating a customer’s billing status based on the payment of an invoice, or disabling a button while an operation is proceeding. Most of what I’m doing is not groundbreaking never-before-seen stuff, so the next steps in what I’m doing can be anticipated. Giving descriptive names to my files, functions, and variables, and adding descriptive comments is already a great practice for anyone writing maintainable code but also really helps to push Copilot in the right direction. The greatest value here is simply saving me time. Like when you’re writing a reply to an email in Gmail, and it knows how you were going to finish your sentence, so you just tell it to autocomplete what you were going to write anyway, like adding “a great weekend!” to “Have” as a sign-off. Lazy programmers are the most productive programmers and this is a great aid in this pursuit.
Saving me a trip to the documentation.
Most of modern programming is really just gluing other libraries and services together. All of these components you must interface with have their own semantics and vocabulary. If you want to accomplish a task, whether it’s resizing an image or sending a notification to Slack, you typically need to do a quick google search then dig through the documentation of whatever you’re using, which is also often in a multitude of formats and page structures and of highly varying quality. Another time saver is having your AI assistant already aware of how to interface with this particular library or service you’re using, saving you a trip to the documentation.
Writing tests and verifying logic.
It should be mentioned that writing code is actually not all that hard. The real challenge in building software comes in making sure the code you wrote actually does what you expected it to do and doesn’t have bugs. One way we solve this is by writing automated tests that verify the behavior of our code. It doesn’t solve all of our problems but it does add a useful safety net and helps later when you need to modify the code without breaking it. Copilot is useful for automating some of the tedium of this process.
Also sometimes if I have some piece of code with a number of conditions and not very straightforward logic, I will just paste it into ChatGPT and ask me if the logic looks correct. Sometimes it points out potential issues I hadn’t considered or suggests how to rewrite the code to be simpler or more readable.
Finding the appropriate algorithm or formula.
This is less common but sometimes I have some need to perform an operation on data and I don’t know the appropriate algorithm. Suppose I want to get a rough distance between two points on the globe, and I’m more interested in speed rather than accuracy. I don’t know the appropriate formula off the top of my head but I can at least get one suggested to me and it’s ready to convert between the data structures I have available and my desired output format. AIs are great at this.
Problems With “AI” Tooling For Building Software
While the term artificial intelligence is all the buzz right now, there is no intelligence to speak of in any of these commercial tools. They are large language models, which are good at predicting what comes next in a sequence of words, code, etc. I could probably ask one to finish this article for me and maybe it would do a decent job, but I’m not going to.
Fancy autocomplete is powerful and helps with completing something you at least have some idea of how to begin. This sort of tool has fundamental limitations though especially when it comes to software. For one thing, these tools are trained with a finite context window size, meaning they have very small limits in terms of how much information they can work with at any time, can’t really do recursion, and can’t “understand” (using the term very loosely) larger structures of a project.
There are nifty demos of new software being created by AI, which is not such a terribly difficult task. I’ve started hundreds of software projects, there’s no challenge in that. I admit it is very neat to see a napkin drawing of a simple web app turned into code, and this may very well one day in the medium term allow non-technical people to build simple, limited, applications. However, modifying an existing project is a problem that gets drastically harder as the project grows and evolves. Precisely because of the limited context window, an AI agent can’t understand the larger structures that develop in your program. A software program ends up with its own internal representations of data, nomenclatures, interfaces, in essence its own domain-specific programming language for solving its functional requirements. The complexity explodes as each project turns into its own deviation from whatever the LLM has been previously trained on.
Speaking of training, another glaring issue is that computer programmers (I mean, computers that program) only know about what they’ve seen before. Much of that training input is out of date for one thing. Often when I do use a LLM to help me use an API, it will give me commands for an older version of that API which are no longer correct or relevant. New technologies it has particular trouble with, for example giving me all kinds of nonsense about the AWS CDK. But worse than that, anything created after about 2022 or 2023 which be very hard for LLMs to train on because of the “closed loop” problem. This occurs when LLMs begin to learn from their own outputs, a scenario that becomes increasingly likely as they are used to generate more content, including code and documentation. The risk here is twofold: first, there’s the potential for perpetuating inaccuracies. An LLM might generate an incorrect or suboptimal piece of code or explanation, and if this output is ingested back into the training set, the error becomes part of the learning material, potentially leading to a feedback loop of misinformation. Second, this closed loop can lead to a stagnation of knowledge, where the model becomes increasingly confident in its outputs, regardless of their accuracy, because it keeps “seeing” similar examples that it itself generated. This self-reinforcement makes it particularly challenging for LLMs to learn about new libraries, languages, or technologies introduced after their last training cut-off. As a result, the utility of LLMs in programming could be significantly hampered by their inability to stay current with the latest developments, compounded by the risk of circulating and reinforcing their own misconceptions.
If we get rid of most of the programmer specialists as Mr. Huang foresees, then more code generated in the future will be the product of computery-type programmers. They learn by example, but will not always produce the best solution to a given problem, or maybe a great solution but for a slightly different problem. Sure, this can be said about human-style programmers as well, but we’re capable of abstract reasoning and symbolic manipulation in a way that LLMs will never be capable of, meaning we can interrogate the fundamental assumptions being made about how things are done, rather than parroting variations on what’s been seen before and assuming our training data is probably correct because that’s how it was done in the past. Their responses are generated based on patterns in the data they’ve been trained on, not from a process of logical deduction or understanding of a computational problem in the way a human or even a conventional program does. This means that while a LLM can produce code that looks correct, it may not actually function as intended when put into practice, because the model doesn’t truly “understand” the code it’s writing, it’s essentially making educated guesses based on the data it’s seen. While LLMs can replicate patterns and follow templates, they fall short when it comes to genuine innovation or creative problem-solving. The essence of programming often involves thinking outside the box, something that’s inherently difficult for a model that operates by mimicking existing boxes. Even more, programming at its core often involves understanding and manipulating complex systems in ways that are fundamentally abstract and symbolic. This level of abstraction and symbolic manipulation is something that LLMs, as they currently stand, are fundamentally incapable of achieving in a meaningful way.
If these programmer agents do become capable of reasoning and symbolicmanipulation, and if they can reason about large amounts of data, then we will be truly living in a different world. People with money and brains are actively working on these projects and there are financial and reputational incentives now motivating this work in a major way, so I absolutely expect advancements one day. How far that day is off, I dare not speculate on.
The Users Of Computer-Aided Programming Tools
One of the coolest features and biggest footguns about programming is that you can give a computer instructions that it will follow perfectly and without fail exactly as you specify them. I think it’s amazingly neat to have a robot that will do whatever you ask it, never get tired, never need oiling, can be shared and tinkered with, worked on in maximum comfort from anywhere. That’s partly what I love about programming, I enjoy bossing a machine around and imposing my will on it, and it almost never complains. But the problem anyone learns almost immediately when they start writing code is that computers will do exactly what you tell them to do without any idea of what you want them to do. When people communicate with each other there is a huge background of shared context, not to mention gestures, facial expressions, tones, and other verbal and non-verbal channels to help get the message across more accurately. ChatGPT does not seem to get the hint even when I get so frustrated I start swearing at it. Colleagues that work together on a shared task in the context of a larger organization have a shared understanding of purpose, risks, culture, legal environment, etc. that they are operating inside of. Even with all of this, human programmers still err constantly in translating things like business requirements into computer programs. A LLM with none of this out-of-band information will have a much harder time and make many more assumptions than a colleague performing the same task. The LLM may however be better suited for narrowly-defined, well-scoped tasks which are not doing anything new. I hope and believe LLMs will reduce drudgery, boilerplate, and wheel reinventing. But I wouldn’t count on them excelling at building anything new, partly because of how non-specialists will try to communicate with them.
In most professions a sort of jargon develops. Practitioners learn the special meanings of words in their fields, for example in medicine or law or baseball. In the world of software we love applying 10-dollar words like “polymorphism” or “atomicity” to justify our inflated paychecks, but there is another benefit to this jargon, which is it can help us describe common concepts and ideas more precisely. If you say to a coder to “add up all the stuff we sold yesterday”, you may or may not get the answer to the question you think you’re asking. If you say “sum the invoice totals for all transactions from 2024-04-01 at 00:00 UTC up to 2024-04-02 00:00 UTC for accounts in the USA” you are a lot more likely to get the answer you want and be more confident that you got a reliable number. Less precise instructions leave huge mists of ambiguity which programming computers will happily fill in with assumptions. This is where much of the value of specialists comes in, namely the facility in some dialect which enables a greater precision of expression and intent than the verbiage someone in the Sales or HR department will reliably deploy. In plenty of situations, say if you’re building a social media network for parakeets, maybe it’s okay. But when real money is on the line, or health and safety, or decisions with liability ramifications are introduced, I predict companies will still want to keep one or two specialists around to make sure they aren’t now playing a game of telephone with a coworker talking to a LLM on the other end and who knows what logic emerging out of the other end.
Introducing AI agents into your software development flow may create more problems than it solves, at least with what is likely to be around in the near term. On the terrific JS Party podcast they recently took a look at “Devin”, a brand new tool which claims the ability to go off by itself and complete tickets like a software engineer in your team might do. It received heaps of breathless press. But until these agents are actually reliable, other engineers still will have to debug the work done by the agent, which could end up wasting more time than is saved.
But the number they published, I think, was 13.86% of issues unresolved. So that’s about one in seven. So you pointed out a list of issues, and it can independently go and solve one in seven. And first off, to me, I’m like “That is not an independent software developer.” And furthermore, I find myself asking “If its success rate is one in seven, how do you know which one?” Are the other six those “It just got stuck”? Or has it submitted something broken? Because if it sets up something broken, that doesn’t actually solve the issue, not only do you have it only actually solving one in seven, but you’ve added load, because you have to go and debug and figure out which things are broken. So I think the marketing stance there is little over the top relative to what’s being delivered.
The software YouTuber Internet of Bugs went on to accuse the creators of Devin of misleading the public about its capabilities in a detailed takedown.
And in practice, a lot of code a LLM gives me is just wrong. A couple weeks ago I think I ended up trying to write a script for around four hours with ChatGPT when probably should have just looked up the relevant documentation myself. It kept going in circles and giving me code that just didn’t do what it said it did, even with me feeding it back output and error messages.
What’s The Future?
While there are many reasons for skepticism about AI-assisted programming, I am guardedly optimistic. I do get value out of the tools I use today which I believe will improve rapidly. I know there are very smart people out there working on them, assisted by computers making the tools even smarter, perhaps not unlike how computers started to be used to design better processors in a powerful feedback loop. I have limited expectations for LLMs but they are certainly not the only tool in the AI toolbox and there are vast amounts of money flowing into research and development, some of which will undoubtedly produce results. Computers will be able to drop some of the arbitrary strictness that made programming so tedious in the past and present (perhaps a smarter IDE will not bother you ever again about forgetting a ; or about an obviously mistyped variable name). I have high hopes for better static analysis tools or automated code reviews. Long-term I do believe how most people interact with computers will fundamentally change. AI agents will be trusted with more and more real-world tasks in the way that more and more vital societal functions have been allowed to be conducted over the internet. But someone will still have to create those agents and the systems they interact with and it won’t be only AI agents talking to themselves. At least I sure hope not.
So I’m not too concerned for my job security just yet. Software continues to eat the world and I’m not convinced the current state of the art can do the job of programmers without specialist intermediaries. As in the past, new development tools and paradigms will make programmers more productive and able to spend more time focusing on the problems that need solving rather than on mundane tasks. Maybe we will be able to let computers automate their automation of our lives but it will be on the less-mission-critical margins for quite some time.
If you’re using AWS CDK and Cognito, probably you want to have a test user account. I use one mainly for testing GraphQL queries and mutations in the AppSync console which requires you to provide a userpool username and password.
As a result of Russia’s invasion of Ukraine there have been a few lexical, orthographic, and semantic changes of note taking place in the Ukrainian language. They propagate alongside the flood of information, memes, and propaganda flowing over Ukrainian social media, primarily on telegram and Meta platforms. Some are more widespread than others, some may not last, but it’s curious to look at how war can change the perception of one’s neighbor in such a short period of time, with the language following along in changes in attitude.
To summarize information reported by the Ukrainian telegram channel “Gramota”:
Синонімічний ряд росія – московія тепер доповнили кацапстан, оркостан, мордор.
New synonyms for “russia”/”moscovia” (sic) are: “katsapstan”, “orcostan”, “mordor”. The latter synonyms are derived from the widespread Tolkeinian references to the invading army as a horde of orcs due to the poorly coordinated human wave attacks, slaughtering of civilians, and general disorder characteristic of the russian army. The army is also frequently referred to as “орда”, the Mongol horde which caused a great deal of destruction in the region in the past.
In addition the authors note the now somewhat commonplace writing of “russia”, “moscow”, “rf”, and “putin” in lowercase, even in some official media. (“Щоб продемонструвати свою зневагу, слова росія, москва, рф, путін ми стали писати з малої літери.”)
Not to be outdone, the Ukrainian Armed Forces suggested writing “russia” with an extra small “r” (“ₚосія”):
A new widely-used term to refer to russians of the putinist persuasion is “rashism” (рашизм) – a novel portmanteau of “russian” and “fascism”.
“The War in Ukraine Has Unleashed a New Word” – Timothy Snyder in New York Times Magazine
Змінили й правила граматики. Тепер принципово кажемо “на росії” у відповідь на їхнє “на Україні”.
This one is a little hard to explain but there are different prepositions that have been used to refer to being “in Ukraine” – during the Ukrainian SSR days when Ukraine was officially as a state inside the USSR the prefix “on” (на) was used with the locative or prepositional case with respect to Ukraine. After independence the appropriate prefix “in” (в) has been used to signify a distinct country instead of a region. Apparently some in russia still say “on Ukraine” to be disrespectful, so: “now we say ‘on russia’ in response to their ‘on Ukraine'”.
Нового значення з негативним забарвленням набуло дієслово спасати.
“A new meaning with a negative connotation was acquired by the verb ‘to save'”. As putin’s army came “to save” Ukraine from whatever it was supposedly saving them from, the word now has a sinister association.
Лягаючи спати, ми почали бажати спокійної ночі або тихої ночі. 🌙 Але тут ми не скалькували фразу “Спокойной ночи”. Це просто збіг. Ми вклали в неї свій зміст, переосмисливши значення спокою.
Going to bed, we began to wish each other a peaceful night or a quiet night. 🌙 But here we did not copy the (russian) phrase “Good night” (lit. “peaceful night”). It’s just a coincidence. We put our meaning into it, rethinking the meaning of peace.
Molotov cocktail recast as a Bandera smoothie (with a discussion on the gender of smoothie)
Three weeks of the unprovoked invasion of Ukraine by Russia has demonstrated the essential cruelty and homicidal nature of the Russian military and civilian leadership. Having discovered that their political goal of occupying the country and installing a puppet leader friendly to Moscow was going to be harder than anticipated, they have settled for wholesale slaughter of civilians with no particular goal other than that of terror and enlarging Russia’s territory.
As a genocide scholar I am an empiricist, I usually dismiss rhetoric. I also take genocide claims with a truckload of salt because activists apply it almost everywhere now.
Not now. There are actions, there is intent. It's as genocide as it gets. Pure, simple and for all to see
This is not the first or second time that the Muscovite government has attempted to erase the Ukrainian culture and people for the crime of being born on lands that Russia considers theirs to control. Much of the Russian-speaking populace of Eastern Ukraine are Russians that were moved into the region from Russia, while native Ukrainian families in the area were killed or forcibly relocated to Russia. This region with a higher density of Russian speakers is what Putin has used as a pretext to “protect” ethnic Russians from the violence in the region resulting from the Russian-backed separatists who revolted against the government in 2014. The banning of the Ukrainian culture in the Russian Empire and the deliberate death by starvation of millions of Ukrainians by Stalin were historical attempts at erasure still fresh in the Ukrainian cultural memory, along with recent injustices like Chernobyl and the annexation of Crimea and the Donbas, not to mention the twenty or so wars previously fought between Russia and Ukraine. Considering this it should have not been a surprise to the Kremlin when their invasion force was not welcomed with open arms as liberators.
Since the invasion failed to quickly occupy and control Kyiv, the parade uniforms brought with the soldiers were shelved and the standoff weaponry was hauled out as in previous Russian military campaigns against unwilling citizenry like in Syria and Chechnya. Due to their fear of entering hostile cities, the Russian military has been targeting critical civilian infrastructure for bombardment. Artillery, ballistic missiles, precision guided missiles, multiple-launch rocket systems, dumb bombs, smart bombs, and everything else that explodes has been lobbed into Ukrainian cities and towns that the Russian Horde comes upon. Hospitals, water treatment facilities, nuclear power plans, internet providers, mobile phone and TV towers, schools, government buildings of every sort, and residential buildings have all been targeted and blown to pieces.
This is a city on the Sea of #Azov and its name is Mariupol. It is named after the Virgin Mary, mother of Jesus Christ. 350 thousand residents of #Mariupol 18 days without water, food and electricity. Hundreds of air bombs hit the hero city. #Ukrainepic.twitter.com/FAl4vhfLks
Entire cities are now without electricity, internet, heat, or water. The strategy appears to be the same as in Aleppo and Grozny: murder and terrorize citizens until the city is no longer a point of resistance, due to surrender or complete razing, whichever comes first.
Bombed maternity hospital.
There are additional domains that the Kremlin is waging warn in: the cyber and information spaces. At the time of the invasion a new piece of malware was activated in Ukraine which was designed to permanently destroy all data stored on a computer. Not simply overwriting all files with garbage data but leveraging a signed disk driver to overwrite the master boot record and corrupting filesystem structures to make recovery impossible. A highly destructive and targeted attack launched right before the invasion.
Breaking. #ESETResearch discovered a new data wiper malware used in Ukraine today. ESET telemetry shows that it was installed on hundreds of machines in the country. This follows the DDoS attacks against several Ukrainian websites earlier today 1/n
And in a modus operandi that everyone should be familiar with now, the Russian government has been using every avenue of communication to get its false messages out regarding Ukraine. That the country is run by a “neo-Nazi junta” who seized power illegitimately, despite the free and fair democratic elections which elected a Jewish president.
When we say Kyiv is winning the information war, far too often we only mean information spaces we inhabit.
Pulling apart the most obvious RU info op to date (as we did using semantic modelling), very clear it is targeting BRICS, Africa, Asia. Not the West really at all. pic.twitter.com/GA5KUQo77S
Russia’s permanent representative to the United Nations Security Council called an emergency meeting to warn of the dangers posed by biological laboratories in Ukraine. In the meeting, Russia’s top UN ambassador claimed without evidence that Ukraine in conjunction with America was gathering DNA samples from Slavic peoples to create an avian delivery system for targeting Slavs with a biological weapon. I’m not making this up, you can watch the meeting yourself.
And in recent days Russian state media has been warning that Ukraine will use chemical weapons: “Ukrainian neo-Nazis are preparing provocations with the use of chemical substances to accuse Russia, the Ministry of Defense said.”
These are just a couple examples of a massive disinformation campaign coming out of the Kremlin. The claims are easily debunked. Ukraine is in compliance with biological safety inspections and only maintains facilities working with low-danger pathogens (BSL-1 and BSL-2) which are of no threat to anyone. Ukraine maintains no chemical or biological weapons research or weaponry, in contrast to Russia which operated the largest biological weapon program in world history and is infamous for using nerve agents to assassinate people in modern times, the only other country besides North Korea.
While the Russian government tries to convince the world of the aggressive and deadly nature of the Ukrainian threat, it is Russia that has invaded Ukraine and continues to deport and murder civilians and torture journalists in an effort to terrorize the country into submission. As of March 18th, the UN reported that about ten million civilians have fled their homes as a result of the war, with 6.5 million internally displaced and 3.2 million refugees fleeing to other countries. The UN High Commissioner for Human Rights recorded 1,900 civilian confirmed casualties in three weeks, with official Ukrainian estimates much higher.
In the House of Commons, MPs have unanimously adopted a motion to recognize that the Russian Federation is committing acts of genocide against the Ukrainian people. The motion was proposed by Heather McPherson, the NDP critic for foreign affairs.#cdnpolipic.twitter.com/z4WC44z9N5
In occupied Kherson, an illustrative example, it has been hard to get news out lately because the Russian military destroyed all means of telecommunications, confiscated cell phones, disabled the internet, and only allows citizens to watch Russian propaganda on TV. There are reports of Russian plans to stage a referendum in Kherson to annex the city by Russia, as was done in Crimea. The Crimean referendum only gave voters two choices: become an independent state or become part of Russia.
Many cities with millions of residents in Ukraine are being destroyed, as can be seen on this interactive map. Endless footage of civilian casualties can be seen on cell phone recordings taken on the ground by Ukrainians. The stories from cities under siege, like Mariupol, Kharkiv, Sumy, Mykolaiv, are the same. Indiscriminate bombardment of military and non-military targets alike, mostly the latter. Attacks on critical civilian infrastructure. Attempts to block electricity, internet access, food, water, and information from reaching the city. Rounding up and arresting Ukrainians critical of Russia.
The Russian plan appears to be to seize territory that it can, and erase territory that it cannot. The new political objective remains unclear.
Russia's deliberate destruction of Ukraine's food stores and grocery shops is painfully evident from @planet satellite imagery, with large grocery stores destroyed and deliberately targeted.
Last night, Russia struck the Retroville Mall near Kyiv, destroying most of it (including this smaller building but not only). At least four people died in this attack. pic.twitter.com/v7aIGMQmUQ
One of the silver linings of this terrible, unnecessary catastrophe is the fact that this ill-conceived invasion is the best documented in history. The dissemination of information about combat, forces, movements, official and unofficial statements, largely via Ukrainian telegram channels, is swift and unprecedented. Countries use their official twitter accounts to troll and mock belligerents. Soldiers and civilians on the ground post videos of them dressing down Russian conscript teenagers and borrowing occupying army hardware.
Huge caveat: the vast majority of what I see is from pro-Ukraine Telegram/Discord/Twitter, it’s only a few days into a massive operation, with major fog of war. This is absolutely not an accurate or complete picture of the war. But it is a darkly amusing one.
Here are a few choice quotes from professional analysts, military, and war nerds:
wait, how did you listen in to russian radio comms lol. Aren’t they supposed to be encrypted, not to mention off the internet..? Right?
It almost looked more as if they were trying to get as far they could down a road until they encountered a road block and were completely unworried about all the amazing angles people with cameras (which could just as easily be rifles) had on them. I’m kinda confused about wtf the idea behind that was too, maybe its just how things worked in syria…?
There are so many videos of russian troops within the cities in light armour and on foot its crazy. I havent seen this much yet. Could it be a sign that shelling is slowing down and they are entering next stage of their plan?
Its absolutely one of the most ill-executed military operations I have ever seen, they’ll use this war in military textbooks for generations to come as an instance of what not to do in strategic/tactical planning and execution.
What’s amazing is that this is fractally stupid – no matter what level you analyze the operation, from tactical to grand strategic, it’s mind-bogglingly stupid.
They’re definitely getting chewed if they enter actual urban combat. What the hell is this formation, military analysts are going to really be scratching their heads what is up with the military and it’s organisation.
Im listening to their comms, very chaotic. They get confused between each others. Also it seems that they are trying to fight ww2 style. Driving in between houses like some peasant with no radio to report while its 2022 and everyone is connected getting intel almost quicker then their radios and coordinating UA forces. And as someone said above their mistake make us think there hould be a logical yet bizarre explanation like “its a plan to outs putin and so on” but i think its their military doctrine not suited for 2022 I do not understand why they are running radios and maps instead of google maps or a chinese knock off. Like it is not like the americans aren’t watching you via satelite
Wow, rare video of the moment of engagement. They’re driving / walking right into ambushes across the city. What, are they trying to lose at this point? Literally feels like they have no control or awareness of the situation. What’s going on. They’re standing there to get shot… They are not very ready for urban fighting judging by that video.
https://twitter.com/RALee85/status/1497809352979361798 Does look like a recon group, not sure why a fuel tanker is driving with them though. That’s a city they’ve bypassed. They need fuel further up the line? That strikes me as a very… aggressive manuver to solve that problem. I have never seen a freaking patrol have a fueler attached Yeah, doesn’t seem like a patrol. I’m so confused honestly. Not sure why they seemed like they were stopping in a couple of different locations as well? An attempt at refueling that just got lost and accidentally drove straight through lines???
“We’re out of gas.”? The logistical problems are bad enough that they’ve… demechanized?
Let’s get into the best Ukrainian and NATO memes four days into this thing.
Latest from Telegram channels: In Ukraine, some local gopniks managed to find a lone Russian APC with the crew, so they beat them up, took the APC and the Russians and gave them to the Ukrainian army. That's one good Cheeki-Breeki right there. pic.twitter.com/2qoZY36hdX
Oh my… an Ukrainian villager again decided to bring back home an abandoned Russian military hardware but this time a 9K33 OSA surface-to-air missile system by tying it to his tractor. pic.twitter.com/9EeR1PA6V2
New (to me) dimension of crowdwork platforms: Russian military uses Premise microtasking platform to aim and calibrate fire during their invasion of Ukraine. Example tasks are to locate ports, medical facilities, bridges, explosion craters. Paying ¢0.25 to $3.25 a task. pic.twitter.com/kHTO2tSCUH
For some strange reason Russia offered to host negotiations at Gomel, in Belarus. Belarus is a belligerent in this war against Ukraine so it was an odd choice of location. Russian negotiating team was left to negotiate with themselves.
Zelensky press-secretary: we are aware that Russian delegation arrived in Homiel, we've indeed discussed talks there, but then Russia issued ultimatum that Ukrainian military should lay down the weapons, so there will be no Ukrainian delegation there https://t.co/WrlFGYBJTv
Zelensky is the number one target for the entire Russian military, spetznaz,FSB, GRU, Rosgvardia all out trying to get his ass, and he’s still making videos on the streets of Kyiv saying they are all here and not going anywhere. Imagine any American politician doing this. https://t.co/0j5fzovsWL
The sign is an obvious photoshop but one actually posted by the interior ministry to make the point.
!!! Ukraine's Interior ministry asked residents to take down street signs in order to confuse oncoming Russian troops. The state road-signs agency went one step further. (Roughly: all directions are to "go fuck yourselves") pic.twitter.com/8xVjceqRfx
Electronic roadsigns on the road from Boryspil airport – “russian ship – fuck off.”
Electrocar chargers in Moscow/St. Petersburg not working – "how can this be?" Reading "Glory to Ukraine"… "glory to heros"… "Putin fuck off"… "death to … er whatnow?" (Ukrainian word – "enemies") pic.twitter.com/8o4Pcl60wD
Putin reportedly has a $97 million luxury yacht called "Graceful". A group of Anonymous hackers on Saturday figured out a way to mess with maritime traffic data & made it look like the yacht had crashed into Ukraine's Snake Island, then changed its destination to "hell": pic.twitter.com/Ch53lcG7D6
A snapshot of the Russian economy: an investment expert goes live on air and says his current career trajectory is to work as "Santa Claus" and then drinks to the death of the stock market. With subtitles. pic.twitter.com/XiPVTSUuks
Some trolling from Ukraine: Head of Anti-corruption agency of Ukraine sent a letter to Russian defense minister Shoigu thanking him for embezzlement of Russian army pic.twitter.com/nIGQtSYnGz
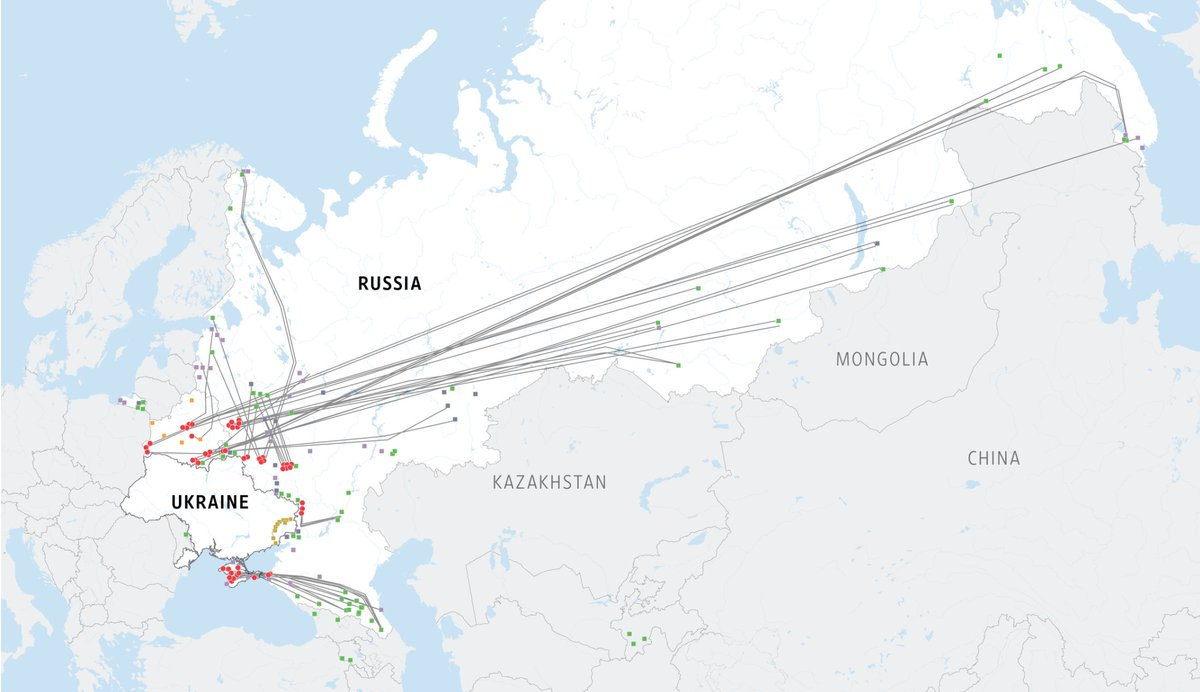
Unlike many in the media and in the chattering classes, I have an acute need to keep up accurately with the “situation” going on between Russia and Ukraine, as my home is in Ukraine. I need to know if it’s safe to stay there or not, so I have been following developments closely. By which I do not mean watching CNN or spending much time reading the mainstream press, I mean following the events on the ground alongside statements, press, and propaganda from Russia, NATO members, the so-called DNR/LNR, Belarus (the most comical), Ukraine, and other interested parties. I’m able to do this thanks to a terrific OSINT discord in which there are of course randos like myself but also experienced intelligence analysts, military personnel, journalists, and people on the ground all around the region. Looking at satellite imagery, Tiktoks (there are dozens of videos posted every day in Russia and Belarus of troop and hardware movements), flights, news reports, press statements, diplomatic evacuations, and more.
So what’s going on? The TL;DR is that the situation is dangerous and the tension has only been building with no sign of de-escalation. While the media and politicians in the West have apparently been going bugfuck non-stop, some have suggested to distract from domestic issues, there are extremely valid reasons to be concerned that something up to and including a military invasion will happen. Many hybrid war elements including large-scale cyberattacks and misleading news have been ongoing and directed at Ukraine in recent days. Whether or not a full-scale military invasion will happen is only known by Putin at this point, but the alarm bells are being rung for good reasons.
Let me attempt to summarize why, starting with some publicly available military movements first:
While Russia and Belarus have announced the military exercises taking place, these exercises only represent a very small fraction of the forces that have been deployed. The forces deployed are mostly not in the regions the exercises have taken place, the scale of the build-up vastly exceeds the scope of the exercises.
The Russian Federation Baltic fleet has moved amphibious landing ships and submarines to the Black Sea, which was not scheduled.
Great numbers of units from the Eastern and Southern Military Districts have been relocated to the border.
Approximately 60% of Russia’s vast combined arms have moved to the Ukrainian border. The current estimates range from 140,000 troops to 180,000 troops split into 83 battalion tactical groups.
The U.S. intelligence community upgraded its warnings because of significant quantities of blood being moved to the field, where it has a shelf life of about three weeks. A precious resource, especially during covid, not normally used in exercises.
A large number of military hospital tents have been set up. Maybe for exercises but unlikely.
Recently Russian tanks have begun moving under their own power towards the border on city streets, tearing them up. Typically one does not destroy one’s own infrastructure during exercises.
Russia’s national guard Rosgvardia has been seen moving to the border. They would be expected to follow an incursion and secure newly-controlled territory.
Ramzan Kadyrov’s personal troops (“Sever” company) have been seen moving from Chechnya to the border. I would not want to meet them under any circumstances. Troops have been filmed boarding trains in Dagestan.
A massive array of S-300s, S-400s, with transloaders and missiles have amassed at the border with enough range to guarantee complete air supremacy.
A complement of Iskander ballistic systems accompany the troops. These would be used in any initial attack to neutralize airfields and for SEAD.
The 1st Guard Tanks Army has been forward deployed to Voronezh, on the border. These are the most elite ground troops Russia has, earmarked for general staff, and would comprise the tip of the spear of any invasion.
Russian troops and hardware is not only in training grounds but have been moved to forward operating bases, and actively deployed in the field. Given the snow, mud, and shitty conditions, it’s very unlikely that this posture can be kept up indefinitely.
Russia has stated that troops are moving away from the border and returning to bases after the completion of exercises. This is demonstrably false, as they have moved closer to the border and at least 7,000 additional troops have appeared in the last couple of days.
In the last couple days there has been a significant increase in artillery fire in the Donbass, reportedly mostly coming from the Russian side, likely attempting to provoke a reaction that can be used as a pretext for invasion.
In short, all of these elements do not necessarily mean there will be an invasion of Ukraine in the near term, but if one was about to take place this is precisely what one would expect to see preceding a large-scale invasion. If it’s a ruse it’s an extremely convincing one.
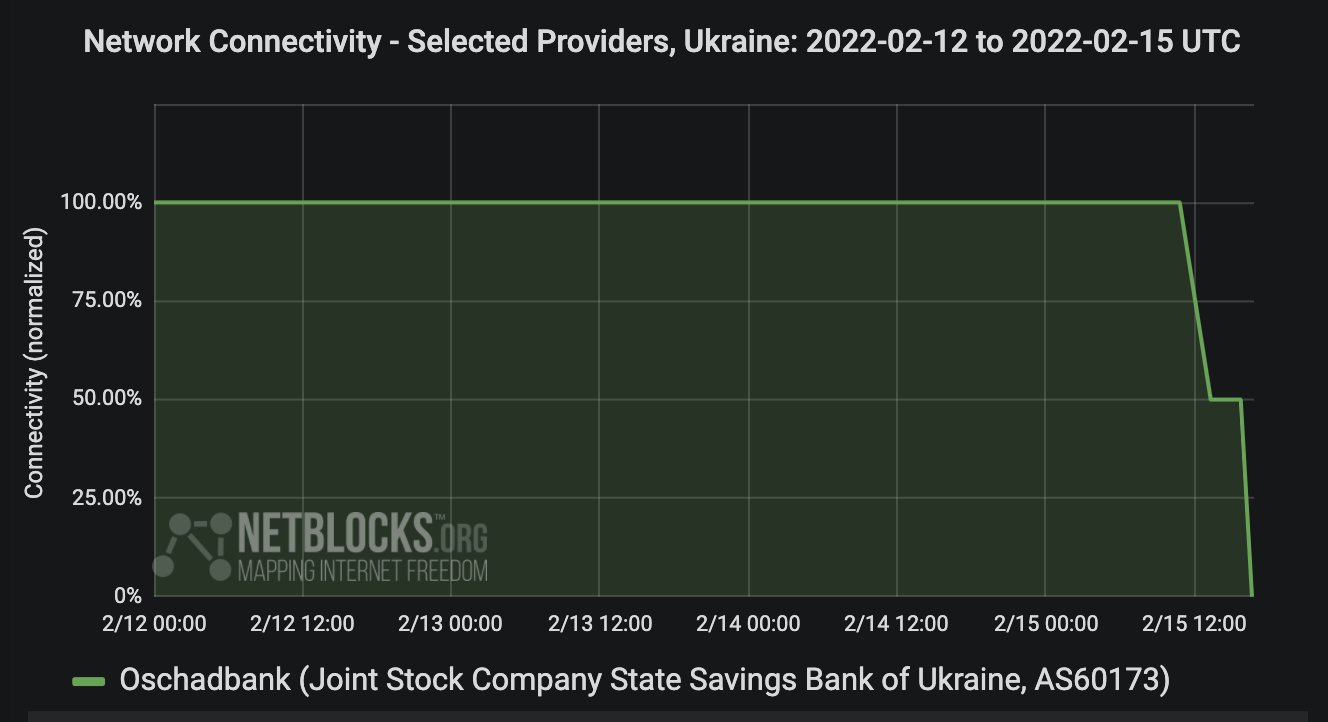
But the military posture is not the only cause for concern. The buildup of troops and hardware is one precondition, but it would be expected to be preceded by hybrid information war and cyber attacks. These have been dramatically scaled up since the 15th of February:
Multiple banks were taken offline at the same time. I was unable to log into my bank because the authentication server was offline.
The ministries of the interior and defense and the president’s website were taken offline. The A record for mil.gov.ua vanished and was unresolvable by CloudFlare.
The gov.ua DNS service sustained a 60GBps+ DDoS attack.
Many Ukrainians were sent SMS messages advising them to withdraw money from ATMs as soon as possible.
Russian news has been pumping out false or greatly exaggerated stories of mass graves, Nazi death squads, active genocides, and preparations for invasion of Donbass by Ukrainians. Any and every possible pretext for a Russian invasion has been floated in the media by official sources, LNR/DNR media, Belarussian sources.
In addition, in the past couple months:
The main general-purpose citizen mobile app (Дія) which is used for tax records, ID, Covid certification and other functions was hacked and the personal records of most Ukrainian citizens and residents was posted for sale on the darkweb.
Car insurance records on finances and addresses of many Ukrainians were stolen.
Around a terabyte of emails and documents from various ministries was reportedly stolen and published.
These are just a few selected observations out of many that I’ve seen go by. This is all based on open-source intelligence. The most urgent warnings have been coming from the U.S., U.K., Canada, and Australia. This is notable because they are four of the five eyes, countries with access to the most advanced and exceptional signals intelligence. More recently, Israel has been loudly sounding the alarm and increasing El Al flights trying to evacuate Israelis from Ukraine. Many have pointed out that when Israel is concerned, it’s worth taking notice.
People in the media with less, let’s say, granular accounts, have been quoting unnamed intelligence officials about specific dates and times of an invasion. I would not put too much stock in such reports because such reports are often of a more propagandistic nature. But I would very much look at the facts on the ground in conjunction with more official warnings. These official warnings have not predicted a specific date of invasion, only about the date upon which an invasion would be completely ready to go. It’s reasonable to be skeptical of these reports, but I believe they are not just pure fabrication or without basis in intelligence, publicly available or otherwise. There is a hypothetical argument to be made that by the leaking of intercepts and intelligence assessments, the U.S. has caused Putin to reconsider plans for invasion. This is a possibility, one of many, but one we cannot know today. Maybe in 15 or 20 years we’ll be able to look back and see what really happened in these times and know. Perhaps it is all merely military exercises, perhaps it is a move to permanently station Russian forces in Belarus, perhaps it was an attempt at diplomacy that failed(?), perhaps it was to intimidate Ukraine into accepting the Minsk agreements. It is clear that these maneuvers were many months or years in planning, executed at great expense, and not merely ordinary troop movements. There was a deliberate effort here to achieve something, opaque as that something may be at this moment.
What could the goal of these efforts be? Some say it is a bluff by Putin, to secure concessions from NATO and the U.S. by scaring everyone into thinking they will launch an attack on Ukraine in case their demands are not met. It’s no secret that the Russian Federation feels existentially concerned about the expansion of NATO, an explicitly anti-Russian alliance. They feel that the U.S.’s claims of upholding a rules-based international order and the sanctity of internationally recognized borders are laughably false. Sadly it must be admitted that they have a point. From the NATO bombing of Serbia and recognition of Kosovo, to the illegal wars of aggression in Iraq and Afghanistan, and more recently the covert and overt military interventions in places like Libya and Syria by the U.S. obviously run counter to the stated values and norms that are supposed to be so inviolable and non-negotiable. As an American I truly wish my government had more credibility and moral high ground here. Anyone who doesn’t have amnesia can see how hypocritical much of the moral posturing is, and Russia will play this up to the greatest extent possible.
However I am skeptical that this massive, expensive, extraordinary military buildup and active hybrid warfare aimed at Ukraine is purely about securing agreement from the U.S. and NATO. This is because their demands, given in writing, were clearly impossible to meet and Putin doubtlessly knew this. There is zero reason to believe Russia seriously expected NATO to kick out all of the members who joined since 1997. They also know that Ukraine is not going to be joining NATO anytime soon because of the active conflict in Donbass, among other reasons. The negotiations have been an obvious farce, so what would be the point of a bluff? If it is a bluff of an imminent attack, it certainly may be the most elaborate and convincing in all of modern history. No one hopes more than me that an invasion will not take place, and I think it unlikely that bombs will start falling on Kyiv, but I need to assess the situation rationally. Even if the risk is small, is it worth staying in Ukraine right now as all this is happening? Would you?
As to why former USSR countries desperately want to be a part of NATO, this is left as an exercise for the reader. In my personal opinion the only peaceful and lasting solution to this larger conflict would be for NATO to offer a path to Russia to join, with preconditions on a more democratic political system. This would take all of the wind out of Putin’s sails, prove that NATO is not purely an anti-Russia military alliance, and provide an avenue for political pressure to push the country in a positive direction as offering NATO and EU membership to other countries has done.
On at least one point, Russia has been consistent and persistent: that Ukraine must implement the Minsk agreements, which were signed as a ceasefire in 2015, under extreme duress. Russia’s interpretation of the agreements would effectively give Russian-backed separatists in the Donbass seats in parliament and political control and vetos on Ukraine’s foreign policy. Such an agreement, essentially signed at the time with a gun to their heads, is unimplementable in Kyiv today. Any government implementing Russia’s interpretation would be gone within a week, probably violently. Too many Ukrainians have fought and died to give power of their country over to Russia. Russia knows this and continues to push for it because they can say they are just trying to address the situation diplomatically. It is dreadfully cynical.
Another relevant agreement which Russia is not quick to bring up is the Budapest Memorandum, which was an agreement signed in 1994 by the U.S., U.K., Russia, Ukraine and others guaranteeing freedom from aggression and violations of borders in exchange for Ukraine giving up its nuclear weapons. To quote Wikipedia:
On 4 March 2014, the Russian president Vladimir Putin replied to a question on the violation of the Budapest Memorandum, describing the current Ukrainian situation as a revolution: “a new state arises, but with this state and in respect to this state, we have not signed any obligatory documents.” Russia stated that it had never been under obligation to “force any part of Ukraine’s civilian population to stay in Ukraine against its will.” Russia tried to suggest that the US was in violation of the Budapest Memorandum and described the Euromaidan as a US-instigated coup.
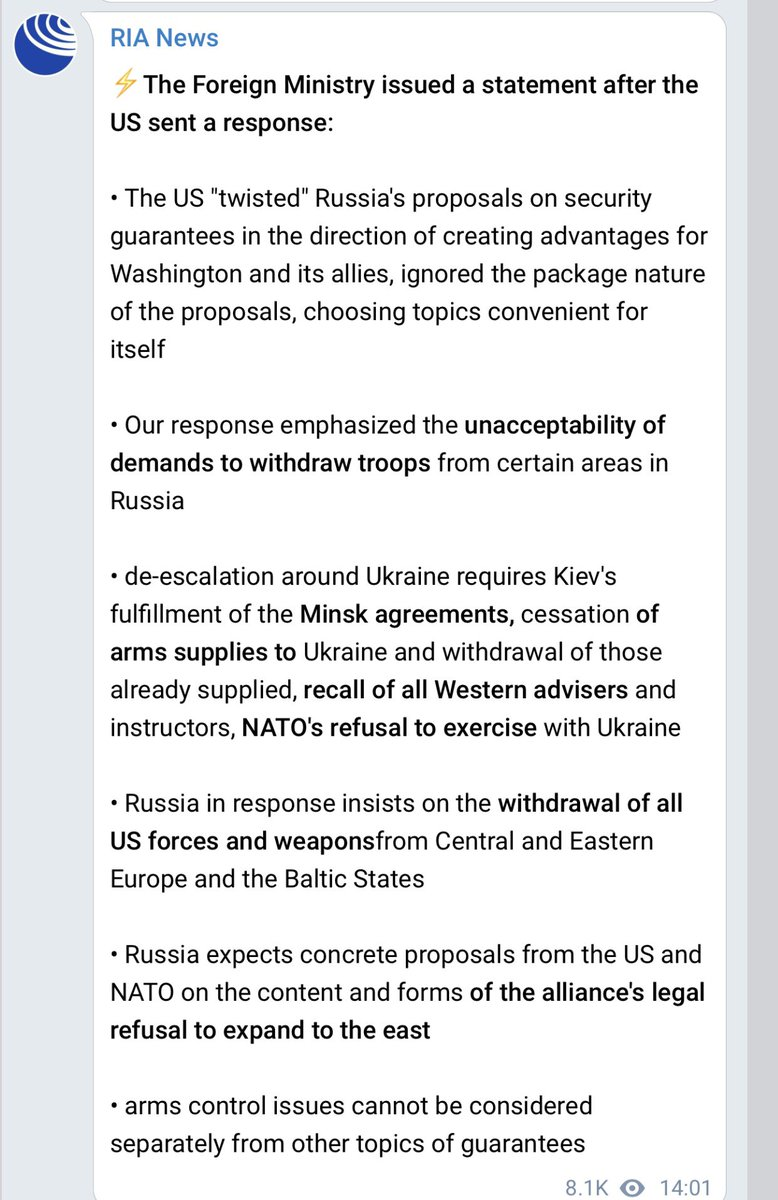
At the UN Security Council meeting in January on the Russian military buildup, the Russian ambassador blasted a shotgun of non-sequiturs ranging from Colin Powell’s evidence of WMDs in Iraq, the “CIA-backed color revolution installing Nazis in power” in the Maidan revolution (please don’t let me catch you repeating this profoundly inaccurate propaganda, even if you heard it repeated on your lefty podcasts), and “Ukrainian aggression” against Russian-speaking peoples. Following this verbal assault he regretfully excused himself because of an unmovable prior commitment, as the Ukrainian ambassador was about to begin his remarks. Since this, Russian ministers have been asserting the need to intervene in the event of attacks on Russian speakers in Ukraine in the event of genocide, this propaganda being pushed by state news agencies such as RIA Novosti in the past few days. The false narratives being constantly put out by state-owned media in Russia about the atrocities being committed in Ukraine have been reaching a fever pitch. If you think the media in the West is hysterical, you should see what they’re saying on Russian TV.
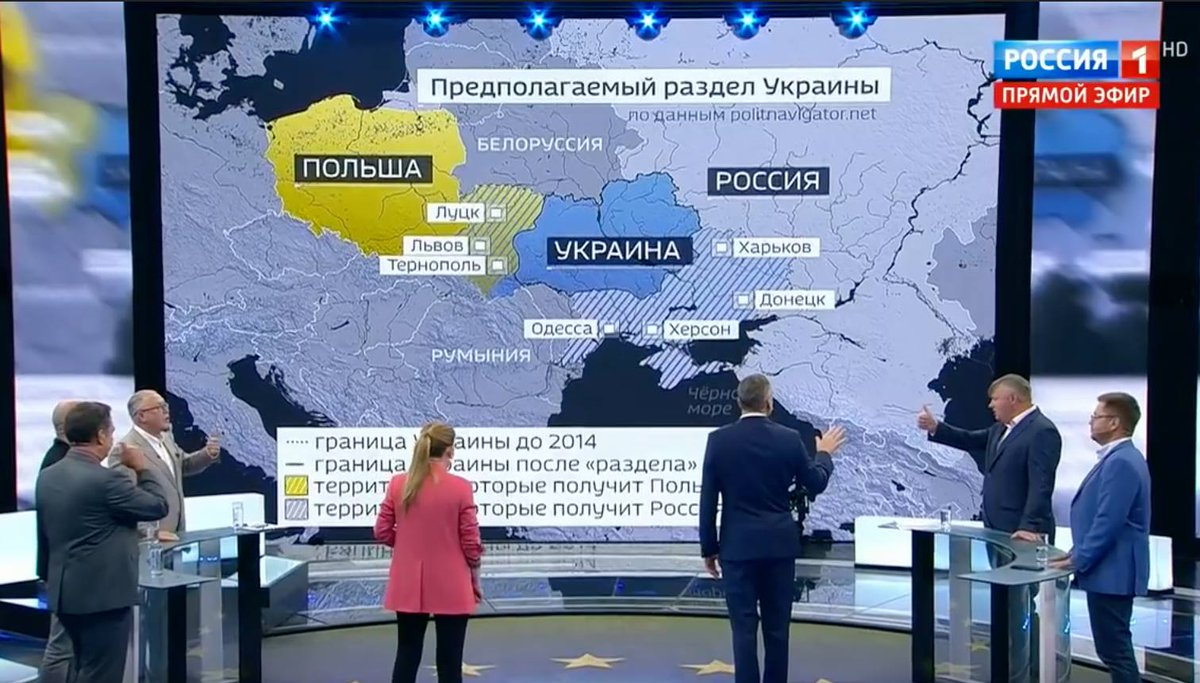
How to invade and split up Ukraine, on Russia 1.
Some say that Russia has done considerable damage against Ukraine without an invasion, and this is indeed true. The economic and human costs since 2014 but particularly in recent weeks has been enormous. Over 14,000 lives have been lost in the conflict, many flights over Ukrainian airspace have been canceled because insurance companies refuse to insure flights to and over Ukraine, remembering the MH-17 tragedy early in the war when a civilian airline was shot down with Russian weaponry. Billions of dollars in economic damage is being done to the Ukrainian economy, tourism is basically canceled.
Foreign ministries from the U.S., U.K., Australia, Sweden, Finland, Israel, Germany, Italy, UAE, Kuwait, Japan, Lithuania, and many other countries have told their citizens to leave immediately in no uncertain terms.
The U.S. embassy in Kyiv has been deactivated, the computers destroyed, and the staff evacuated to Lviv or outside the country. The Russian embassy was seen burning something today, most of its members evacuated as well. Some extremely VIP personnel were seen driving in black SUVs to the Polish border, running to a black hawk helicopter with a medevac callsign, and then quickly whisked away.
Difficult to understand how heavy the fighting has been in eastern Ukraine today until you compare it to the rest of the year so far.
The Ukrainian MoD reported more ceasefire violations today than they did for all of January. pic.twitter.com/JBVOobNcX9
The people who have it the worst are the poor residents of the Donbass. This morning a pre-school was shelled, with three staff injured. Ukraine isn’t even the real concern of Russia, NATO is. But here we are, caught in the middle as usual. Ukrainians don’t want to be pawns in some madman’s game, just to live in peace.
The defi revolution is in full swing if you know where to look. Seriousefforts to build out and improve the underlying infrastructure for smart contracts as well as applications, art, and financial systems are popping up almost every week it seems. They use their own native tokens to power their networks, games, communities, transactions, NFTs and things that haven’t been thought up yet. As more decentralizated autonomous organizations (DAOs) track their assets, voting rights, and ownership stakes on-chain the market capitalization of tokens will only increase.
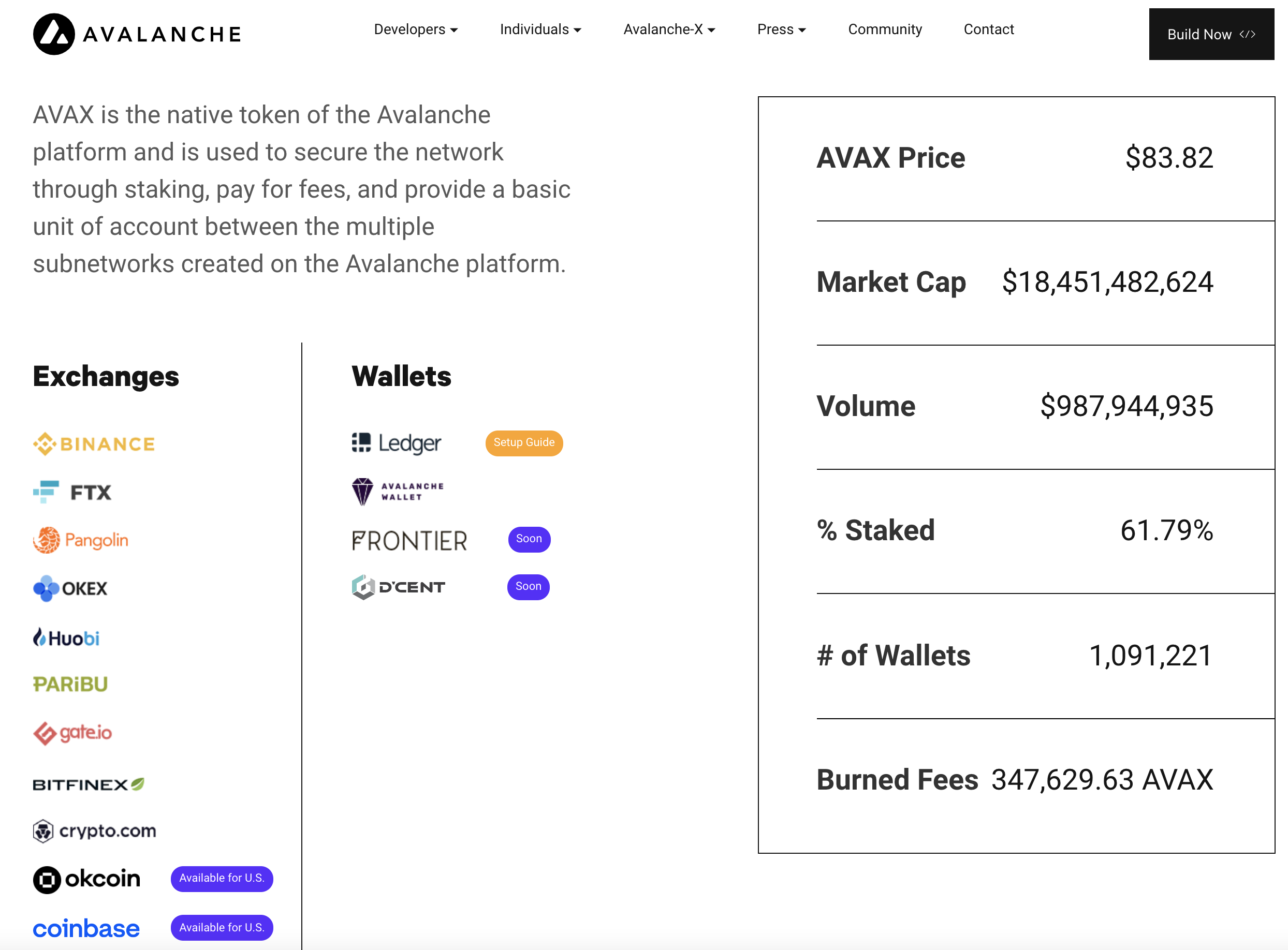
Avalanche is one new token of many that is an example of how new tokens can garner substantial support and funding if the community deems the project worthy.
There are as many potential uses for crypto tokens as there are for fiat money, except tokens in a sense “belong” to these projects and shared endeavours. If enough hype is built up, masses of people may speculate to the tune of hundreds of billions of dollars that the value of the tokens will increase. While many may consider their token purchases to be long-term investments in reputable projects with real utility, sometimes coming with rights or dividend payments, I believe a vast majority of people are looking to strike it rich quick. And some certainly have. The idea that you can get in early on the right coin and buy at a low price, and then sell it to someone not as savvy later on for way more money is a tempting one. Who doesn’t want to make money without doing any real work? I sure do.
Quickstart
If you want to skip all of the explanations and look at code you can run, you can download the JupyerLab Notebook that contains all of the code for creating and optimizing a strategy.
Now for some background.
Trading and Volatility
These tokens trade on hundreds of exchanges around the world from publicly-held and highly regulated Coinbase to fly-by-night shops registered in places like the Seychelles and Cayman. Traders buy and sell the tokens themselves as well as futures and leveraged tokens to bet on price movement up and down, lending tokens for other speculators to make leveraged bets, and sometimes actively coordinating pump and dump campaigns on disreputable discords. Prices swing wildly for everything from the most established and institutionally supported Bitcoin to my own MishCoin. This volatility is an opportunity to make money.
With enough patience anyone can try to grab some of these many billions of dollars flowing through the system by buying low and selling higher. You can do it on the timeframe of seconds or years, depending on your style. While many of the more mainstream coins have a definite upwards trend, all of them vacillate in price on some time scale. If you want to try your hand at this game what you need to do is define your strategy: decide what price movement conditions should trigger a buy or a sell.
Since it’s impossible to predict exactly how any coin will move in price in the future this is of course based on luck. It’s gambling. But you do have full control over your strategy and some people do quite well for themselves, making gobs of money betting on some of the stupidest things you can imagine. Some may spend months researching companies behind a new platform, digging into the qualifications of everyone on the team, the problems they’re trying to solve, the expected return, the competitive landscape, technical pitfalls and the track record of the founders. Others invest their life savings into an altcoin based on chatting to a pilled memelord at a party.
Automating Trading
Anyone can open an account at an exchange and start clicking Buy and Sell. If you have the time to watch the market carefully and look for opportunities this can potentially make some money, but it can demand a great deal of attention. And you have to sleep sometime. Of course we can write a program to perform this simple task for us, as long as we define the necessary parameters.
I decided to build myself a crypto trading bot using python and share what I learned. It was not so much a project for making real money (right now I’m up about $4 if I consider my time worth nothing) as a learning experience to tech myself more about automated trading and scientific python libraries and tools. Let’s get into it.
To create a bot to trade crypto for yourself you need to do the following steps:
Get an API key for a crypto exchange you want to trade on
Define, in code, the trading strategy you wish to use and its parameters
Test your strategy on historical data to see if it would have hypothetically made money had your bot been actively trading during that time (called “backtesting”)
Set your bot loose with some real money to trade
Let’s look at how to implement these steps.
Interfacing With an Exchange
To connect your bot to an exchange to read crypto prices, both historical and real-time, you will need an API key for the exchange you’ve selected.
Fortunately you don’t need to use a specialized library for your exchange because there is a terrific project called CCXT (Crypto Currency eXchange Trading library) which provides an abstraction layer to most exchanges (111 at the the time of this writing) in multiple programming languages.
It means our bot can use a standard interface to buy and sell and fetch the price ticker data (this is called “OHLCV” in the jargon – open/high/low/close/volume data) in an exchange-agnostic way.
Now, the even better news it that we don’t really even have to use CCXT directly and can use a further abstraction layer to perform most of the grunt work of trading for us. There are a few such trading frameworks out there, I chose to build my bot using one called PyJuque but feel free to try others and let me know if you like them. What this framework does for you is provide the nuts and bolts of keeping track of open orders, buying and selling when certain triggers are met. It also provides backtesting and test-mode features so you can test out your strategy without using real money. You still need to connect to your exchange though in order to fetch the OHLCV data.
How much money to start with (in terms of the quote, so if you’re trading BTC/USD then this value will be in USD)
What fraction of the starting balance to commit in each trade
How far below the current price to place a buy order when a “buy” signal is triggered by your strategy
How much you want the price to go up before selling (aka “take profit” aka “when to sell”)
When to sell your position if the price drops (“stop loss”)
What strategy to use to determine when buy signals get triggered
Selecting a Strategy
Here we also have good news for the lazy programmers such as myself: there is a venerable library called ta-lib that contains implementations of 200 different technical analysis routines. It’s a C library so you will need to install it (macOS: brew install ta-lib). There is a python wrapper called pandas-ta.
All you have to do is pick a strategy that you wish to use and input parameters for it. For my simple strategy I used the classic “bollinger bands” in conjunction with a relative strength index (RSI). You can pick and choose your strategies or implement your own as you see fit, but ta-lib gives us a very easy starting point. A future project could be to automate trying all 200 strategies available in ta-lib to see which work best.
Tuning Strategy Parameters
The final step before letting your bot loose is to configure the bot and strategy parameters. For the bollinger bands/RSI strategy we need to provide at least the slow and fast moving average windows. For the general bot parameters noted above we need to decide the optimal buy signal distance, stop loss price, and take profit percentage. What numbers do you plug in? What work best for the coin you want to trade?
Again we can make our computer do all the work of figuring this out for us with the aid of an optimizer. An optimizer lets us find the optimum inputs for a given fitness function, testing different inputs in multiple dimensions in an intelligent fashion. For this we can use scikit-optimize.
To use the optimizer we need to provide two things:
The domain of the inputs, which will be reasonable ranges of values for the aforementioned parameters.
A function which returns a “loss” value between 0 and 1. The lower the value the more optimal the solution.
from skopt.space import Real, Integer
from skopt.utils import use_named_args
# here we define the input ranges for our strategy
fast_ma_len = Integer(name='fast_ma_len', low=1.0, high=12.0)
slow_ma_len = Integer(name='slow_ma_len', low=12.0, high=40.0)
# number between 0 and 100 - 1% means that when we get a buy signal,
# we place buy order 1% below current price. if 0, we place a market
# order immediately upon receiving signal
signal_distance = Real(name='signal_distance', low=0.0, high=1.5)
# take profit value between 0 and infinity, 3% means we place our sell
# orders 3% above the prices that our buy orders filled at
take_profit = Real(name='take_profit', low=0.01, high=0.9)
# if our value dips by this much then sell so we don't lose everything
stop_loss_value = Real(name='stop_loss_value', low=0.01, high=4.0)
dimensions = [fast_ma_len, slow_ma_len, signal_distance, take_profit, stop_loss_value]
def calc_strat_loss(backtest_res) -> float:
"""Given backtest results, calculate loss.
Loss is a measure of how badly we're doing.
"""
score = 0
for symbol, symbol_res in backtest_res.items():
symbol_bt_res = symbol_res['results']
profit_realised = symbol_bt_res['profit_realised']
profit_after_fees = symbol_bt_res['profit_after_fees']
winrate = symbol_bt_res['winrate']
if profit_after_fees <= 0:
# failed to make any money.
# bad.
return 1
# how well we're doing (positive)
# money made * how many of our trades made money
score += profit_after_fees * winrate
if score <= 0:
# not doing so good
return 1
# return loss; lower number is better
return math.pow(0.99, score) # clamp 1-0
@use_named_args(dimensions=dimensions)
def objective(**params):
"""This is our fitness function.
It takes a set of parameters and returns the "loss" - an objective single scalar to minimize.
"""
# take optimizer input and construct bot with config - see notebook
bot_config = params_to_bot_config(params)
backtest_res = backtest(bot_config)
return calc_strat_loss(backtest_res)
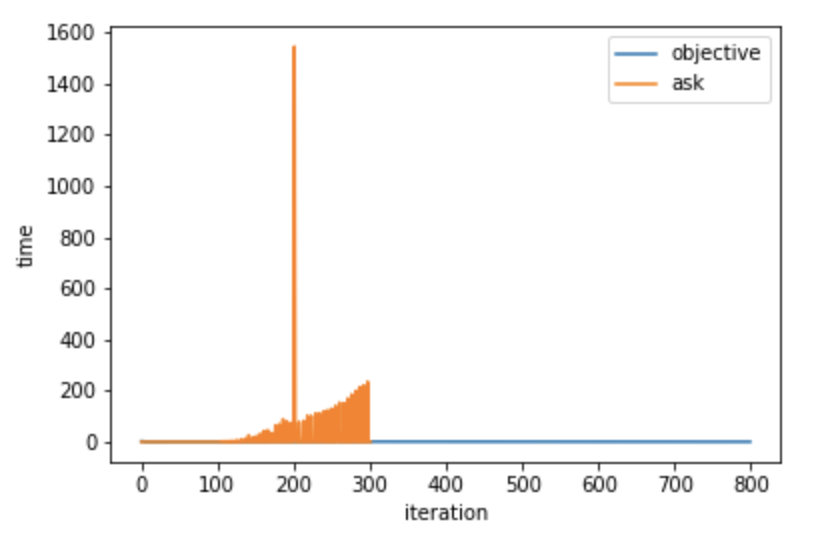
Once you have your inputs and objective function you can run the optimizer in a number of ways. The more iterations it runs for, the better an answer you will get. Unfortunately in my limited experiments it appears to take longer to decide on what inputs to pick next with each iteration, so there may be something wrong with my implementation or diminishing returns with the optimizer.
Asking for new points to test gets slower as time goes on. I don’t understand why and it would be nice to fix this.
The package contains various strategies for selecting points to test, depending on how expensive your function should be. If the optimizer is doing a good job exploring the input space you should hopefully see loss trending downwards over time. This represents more profitable strategies being found as time goes on.
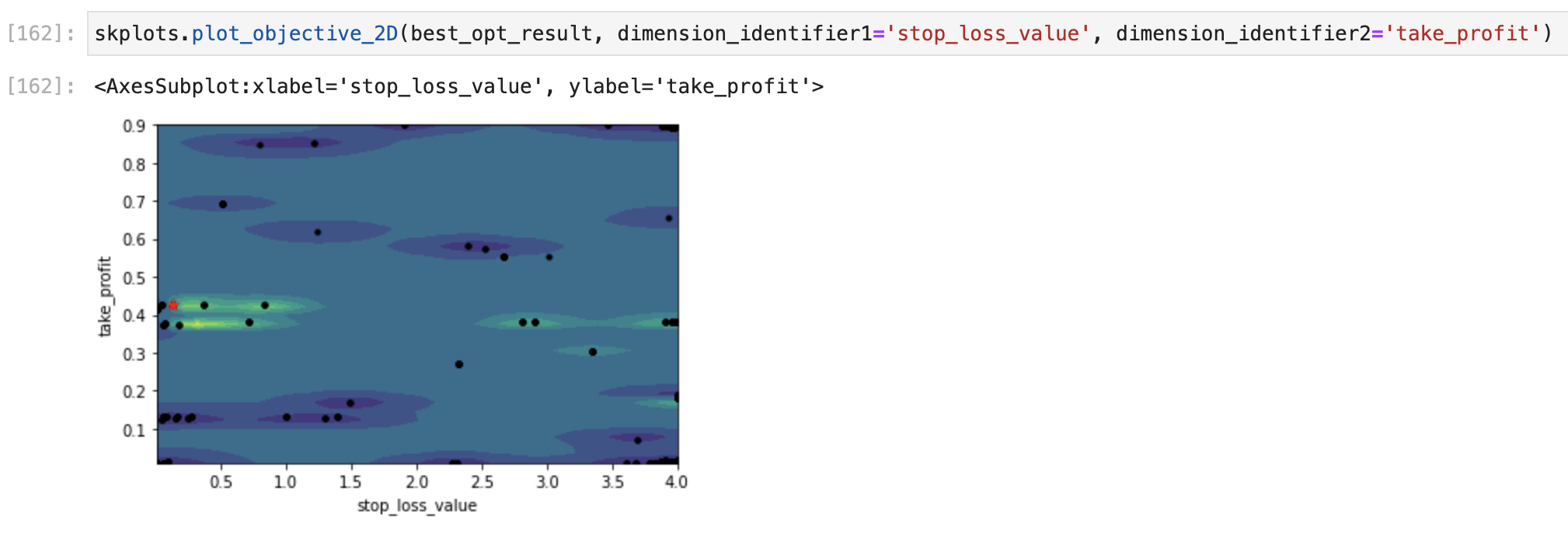
After you’ve run the optimizer for some time you can visualize the search space. A very useful visualization is to take a pair of parameters to see in two dimensions the best values, looking for ranges of values which are worth exploring more or obviously devoid of profitable inputs. You can use this information to adjust the ranges on the input domains.
The green/yellow islands represent local maxima and the red dot is the global maximum. The blue/purple islands are local minima.
You can also visualize all combinations of pairs of inputs and their resulting loss at different points:
Note that the integer inputs slow_ma_len and fast_ma_len have distinct steps in their inputs vs. the more “messy” real number inputs.
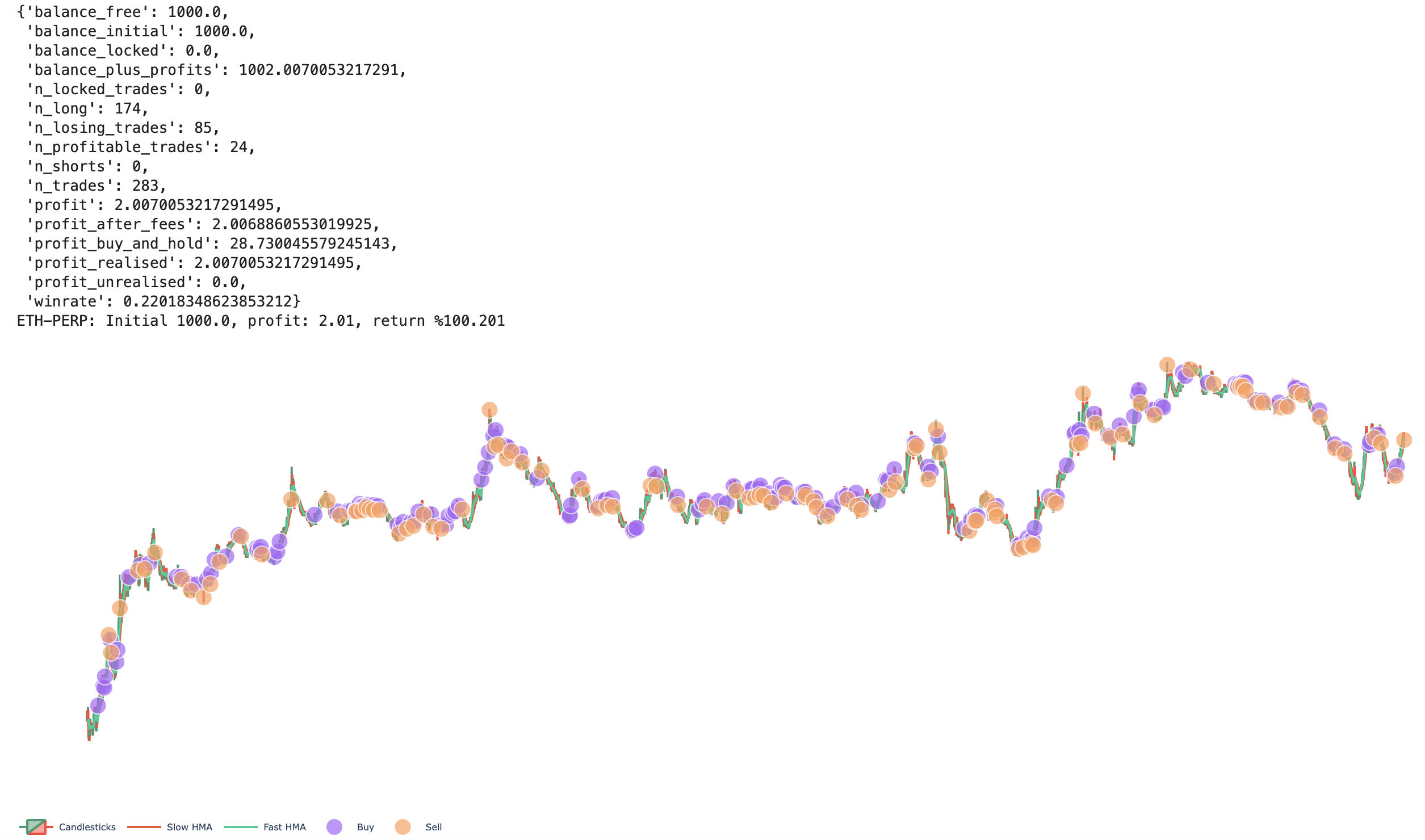
After running the optimizer for a few hundred or thousand iterations it spits out the best inputs. You can then visualize the buying and selling the bot performed during backtesting. This is a good time to sanity-check the strategy and see if it appears to be buying low and selling high.
Run the Bot
Armed with the parameters the optimizer gave us we can now run our bot. You can see a full script example here. Set SIMULATION = False to begin trading real coinz.
Trades placed by the bot.
All of the code to run a functioning bot and a JupyterLab Notebook to perform backtesting and optimization can be found in my GitHub repo.
I want to emphasize that this system does not comprise any meaningfully intelligent way to automatically trade crypto. It’s basically my attempt at a trader “hello world” type of application. A good first step but nothing more than the absolute basic minimum. There is vast room for improvement, things like creating one model for volatility data and another for price spikes, trying to overcome overfitting, hyperparameter optimization, and lots more. Also be aware you will need a service such as CoinTracker to keep track of your trades so you can report them on your taxes.
What kind of language should Facebook forbid? What kind of regulations should the U.S. government promogulate regarding whom Twitter can ban?
☞ Who cares?? ☜ Not me.
A depressing amount of energy and ink is wasted on these questions which shouldn’t even be issues in the first place. We don’t have to base our public discourse on platforms that corporations or even governments control.
The great news is that there does exist an alternative to the model of having all social media content go through a couple of companies. There is certainly no technical reason it should work that way, and there is a solution to the problem that has a foundation in technology, though there is naturally a social component as well.
What is this problem that needs a solution? I think it’s fantastically illustrated by all of these articles and experts and laws being passed to try to nudge Facebook, Youtube, Twitter to control what people are allowed to say and post. Busybodies, Concerned Citizens, corrupt politicians, think tanks, your parents, all want to petition these platforms to decide what you should be able to read or write. I view this as a problem, because I don’t think anyone should decide for me what information I should be able to share or consume. Not Mark Zuckerberg, not Donald Trump, not Jack Dorsey, not my congressional representatives, not the People’s Republic of China.
Government and private corporations in control of censorship are not the only problem here. As everyone knows these services are free, and as everyone also knows if the product is free then you are the product. Facebook and Google make almost all of their money from extracting and mining as much personal data about you as possible to sell to advertisers, PR agencies, and politicians. There is a better way.
Federated Social Media
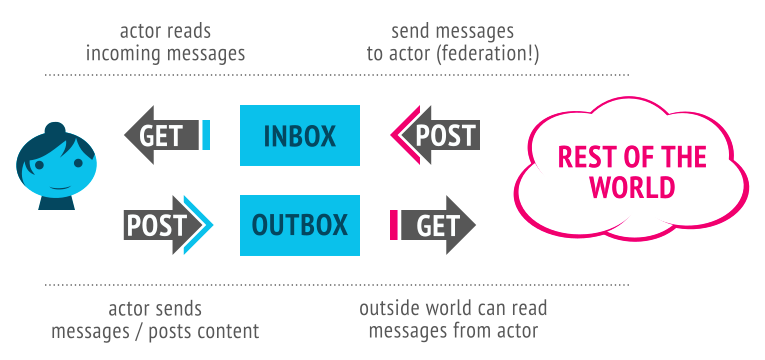
The answer is federation. Decentralization. Distributed systems. You’re already familiar with the concept, just think of email. You don’t have an email username, you have an address. Your email address is a username on a host – mspiegelmock@gmail.com specifies the user mspiegelmock on the system gmail.com. I can write an email to someone else like rms@gnu.org, even if they don’t use gmail. I ask my provider gmail.com to send a message to the gnu.org host which is responsible for delivering it to the user rms.
No company “runs” email, yet all email servers know how to pass messages to each other. There is a vast array of different email hosts, providers, server applications and client apps. You can choose to sign up with a free provider like Google or Microsoft, your employer may provide you an account, or you can run your own server. You can use any sort of app you like with email, such as gmail.com, Apple Mail, Superhuman, Outlook, mutt, or emacs. In the earlier days of web-based mail there were a few options to choose from, like Yahoo and Hotmail, and eventually the company which provided the best user experience ended up grabbing a significant slice of email users, thanks to the wonders of competition. There were and are some issues with spam and malicious content to be sure, though a great amount of progress has been made on systems to combat it (spam and virus filters, real-time blacklists, DKIM/SPF). This is what federation looks like.
To grasp the concept behind federated social media, think of email. You sign up for an account with an instance (“host”) that you feel comfortable with, or run your own if you’re so inclined.
Think Twitter, but as an email address. The address denotes the username (@wooster) and the host the user is registered on (social.coop).
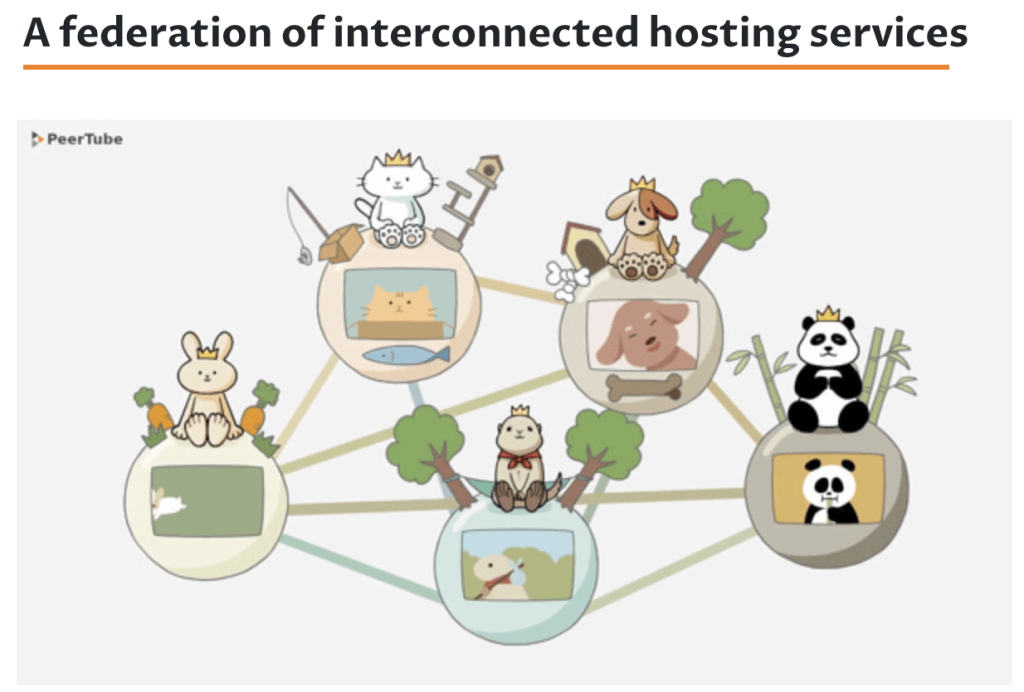
You have two timelines, in addition the people you follow. One timeline is the “local” timeline, which is everyone else on your instance. If you join an instance of people that share a particular hobby, language, interest, region or philosophy you get to start out with a feed that may have posts that may be relevant for you. Your instance can link, or “federate”, with other similar instances, connecting users on your instance with users on the other instances.
Moderation
Why not run a whitehouse.gov instance instead?
Just because there is no central authority for content moderation doesn’t mean that the system is full of abuse and Those Sorts Of People you would like to avoid. These things exist to be sure, as they do on any platform, but they are confined to their own instances. Moderation does exist, but unlike Facebook or Twitter you can choose your moderators. Most instances have policies about what external content they block, what types of instances they want to federate with, and what kinds of content they permit. If you disagree with their policies, you are free to join an instance that fits with your preferences, or start your own.
There are plenty of people I don’t want to hear from, there are plenty of posts our there that would decrease my quality of life, and I’m fine with outsourcing some moderation. I just don’t want this guy to be the final arbiter of all information.
Propaganda, trolls, abuse, and misinformation exist on every platform. You can find it on YouTube, LiveJournal, TikTok, Twitter, and no doubt on federated social media. Media literacy is an important skill that should be taught to help media consumers understand biases and distortions inherent in all media. A platform that helpfully provides fact-checking would be desirable to many users. But the fact remains that you cannot outsource critical thinking. There’s no getting around this.
The problem with top-down centralized structures that take it upon themselves to decide what information can or can not be spread should be plain. Corporations and politicians have bad incentives and the temptation to misuse such power to cover up misdeeds is too powerful for most to resist. We all know now what happened with Chernobyl and the misery caused by the suppression of information. Maybe if we had some supremely enlightened and benevolent information despot it would be okay to put them in charge, but I can’t really think of anyone I want to grant that authority over me.
The instance I belong to is social.coop, a social media cooperative. It’s a group of people who donate a small amount of money to pay for a server to host a Mastodon instance and volunteers who help maintain and administer it. There is an online forum for discussions and consensus-based decision-making, and a lot of smart people on it. This is just one example of the kind of self-organization that is possible in the fediverse.
Mastodon
Today the most popular software for plugging into the federated social media network is Mastodon. It’s free (AGPL) and open source naturally, and there are a number of apps you can use with it, including some slick paid apps. The Mastodon web interface looks something like this:
And the “Toot” app looks like this:
Toot for iOS
Many communities run Mastodon instances, some are public, some are cooperatives, some are private. You don’t have to use Mastodon to talk to people using Mastodon, if you use software that speaks ActivityPub then you can follow, share, post, like, comment, and communicate with anyone else in the fediverse. Just like if you use any email software, you can email anyone else using email software, which I think is pretty neat.
Mastodon is federated social media, federated social media is not Mastodon.
Technical Details (ActivityPub)
In the early days there were a number of attempts at creating social networking protocols with really obnoxious names like “pubsubhubbub.” After a bit of experimentation an official standard was published by the World Wide Web Consortium (W3C) in 2018, going by the name ActivityPub. You may know the W3C from their earlier hits like HTML, CSS, XML, and SVG.
As it’s an extremely recent standard, we’re still in the very early days of implementations. I expect there will be a number of libraries and clients popping up, along with not just standalone servers but server capabilities integrated into existing platforms and sites. Any site that lets you log in and post content could be modified to plug into the fediverse by implementing the relatively simple, JSON-based protocol. Your existing accounts could turn into ActivityPub Actor objects. New social networks can in effect bootstrap themselves by leveraging existing users, software, and federation networks, and we’ll see companies and open source projects compete to offer the best user experience.
Honestly the best way to learn about ActivityPub is to go read the standard doc. It’s in plain English with friendly cartoons and very straightforward.
The very brief gist of it is that there is a client ↔︎ server protocol and a server ↔︎ sever protocol, much like IRC. You can read notifications that arrive in your inbox and you can publish messages to the world via an outbox. All content and objects on the platform are simple JSON documents that live at a URL (an IRI to be precise). Technically you could make a compliant ActivityPub server with a static webserver (I think? Tell me if I’m wrong).
Social media isn’t just text and image posts. The site PeerTube is a decentralized version of YouTube:
PeerTube is a free and open-source, decentralized, federated video platform powered by ActivityPub and WebTorrent, that uses peer-to-peer technology to reduce load on individual servers when viewing videos.
User Base
The network effect is what makes a social network attractive. The more people on it, the more useful it is. Having celebrities is a big draw for many people. It’s the biggest challenge that any challenger to the status quo faces.
I believe there is nothing permanent about Facebook or Twitter. I remember when it was hard to imagine anything replacing MySpace, or when everyone on the Russian-speaking internet had a LiveJournal. Fads change and great masses of people move smoothly to new platforms with ever increasing rapidity.
The thing that is so powerful about a social media protocol is that it seems, at least to me, like the logical conclusion of social media. Once a growing critical mass of people move to it, either because they are sick of Facebook’s shit or some cool new company’s platform happens to be powered by ActivityPub, most of the innovation around communities, software, moderation, new forms of media, organization and technology can happen within the fediverse. Because of the open and extensible nature of the underlying foundation anyone can plug in a conformant piece of software and shape their piece of it how they want while still interoperating with the wider world. It’s a perfect vehicle in which one can imagine fictional visions of the future internet taking shape, like the Metaverse from Snowcrash or the VR Net from Otherland.
https://pawoo.net – Japanese Mastodon with 625,000 users and 45 million posts
The internet is a decentralized collection of autonomous systems held together by communities defining standards and protocols. Distributed social media maps very nicely onto the architecture of the internet and promotes freedom of expression and experimentation with new forms of media, social organization, and technology. Doubtlessly it will create new problems as well, like intensifying the internet hypernormalization effect. It will likely be some time before norms and robust community structures are figured out at scale. The ability for anyone to participate in the wider social community within bounds and parameters they set for themselves will be messier but ultimately more powerful and driven by more positive incentives than the current social media monopolists.
Links
If you want to give Mastodon a spin you can check out joinmastodon.org.
To learn more about ActivityPub read the spec (really, it’s not dry). More info about the types of Actors, Activities and Objects on ActivityPub can be found here.
“America will never be a socialist country!” some exclaim these days. For the first time in a hundred years a viable presidential candidate proudly boasts of their democratic socialistic ideals and is welcomed by many. In fact there is already a great deal of wealth redistribution and government aid programs in America, though much of it is directed to the most well-off and well-connected.
Where does socialism fit in America?
In the mainstream the fact that America is capitalist is axiomatic. America is by definition capitalist and therefore anything done by its government or people is capitalistic. This is a useful piece of propaganda both for its boosters and haters in exactly the same way calling the USSR “socialist” was.
The USSR, or Union of Soviet Socialist Republics (worker’s council) was axiomatically socialist, indicative by the name, as is Democratic Republic of North Korea. The ideal of socialism, the scientifically determined natural end state of economic development, was always just around the corner for the Soviets. Domestically it was a positive term and something the government worked hard to convince its citizens it was the system they were living under, or about to be living under. For America it was a great way to tarnish the name of socialism by pointing out how cruel and impoverished their conditions were. Calling the USSR “socialist” was instrumental in propaganda both internally and externally and so it was encouraged to become the unchallenged categorization of the economic system in the Union of Soviets, even though by any objective measure it was in no way socialist. It was a centrally controlled oligarchy with almost no discretion or devolution of government given to local workers and those in the Party or at the center got to accumulate wealth and power. Common workers had little voice in how the means of production or the fruits of their labors should be democratically distributed, and those that had any such ideas in public could face grave consequences.
America is not the USSR by any stretch, however this propaganda exercise of always explicitly describing it as capitalistic and definitely not socialistic is one aspect that it shares in common with the Soviets. It is a market economy, sort of, sometimes. It does certainly seem to have Capitalists, the sort who in earlier eras would probably sport monocles and top hats instead of Teslas and favorable capital gains tax rates. It’s my opinion however that the US federal government does engage in tremendous wealth redistribution efforts and socialized risk and capital disbursements that would have made a Soviet or Maoist central planner feel uneasy.
When American politicians or their media mouthpieces decry socialism, it’s a worthwhile exercise to ask for whom they mean. In the American context, the technical term “socialism” means “government giving money to the underserving,” i.e. the poors. More than almost any other country, the question of whether someone deserves government handouts is a central concern when considering what our hard-earned tax dollars should be spent on. In many parts of the world, the poor, disabled, young, elderly, disadvantaged and so on are considered deserving by default and the obscenely wealthy and powerful maybe not as much. Somehow, and I don’t claim to know exactly how (although I have some ideas), these determinants have been flipped in Capitalist America.
Again speaking in the media argot, “Socialism” in America is considered Bad because the money goes to the undeserving, like poor children. In our “market economy,” unimaginable quantities of money from taxpayers and future generations is hoovered up by the government and spat out at the inconceivably wealthy and well-connected. Even a moment’s reflection can easily illuminate this but you won’t find any mention of it as socialist in the press.
To give one current example of many, there is a bill far along in the U.S. Senate to modernize America’s nuclear arsenal. This is estimated to cost around $1 trillion over ten years, which likely means $3-4 trillion given the usual Pentagon overruns. Nowhere in the media will you find a discussion of the costs vs. benefits of the proposed spending. Citizens will not find themselves pondering the “how will we pay for it?” question, never mind asking whether America really needs all 4,000 nuclear warheads in the first place. This money will of course go directly into the pockets of the wealthiest corporations and individuals to be spent on gold-plated hardware that hopefully will never be used. When a politician makes the suggestion that we should have some money spent on food stamps or health care suddenly everyone’s breaking out the eye shades and Excel to carefully examine these socialist policies.
“Where will the money come from for the F-35 program?” has never been posed in a debate. Rarely is this wealth redistribution upwards considered socialist, much less challenged for its basic assumptions about needs. But when someone needs to eat food, they get a vastly more stringent auditing of their finances than the president does.
At the same time a bill is passed to dole out $867 billion to (mostly) giant farm conglomerates to farm, or not, the Trump administration takes action to increase work requirements for food stamps because we don’t want socialism. The people who want to eat might not be deserving, so why give them handouts? However while making food stamps less funded and harder to access, no such limitations or work requirements were imposed on the colossal agribusinesses receiving more free government money.
The now $1 trillion budget deficit under Trump is somehow growing, all while programs for basic needs are being cut. A decent new part of the deficit is the giant tax breaks given to the wealthiest Americans and even greater military spending. The tax cuts prompted some of the largest stock buybacks in history, helpfully boosting stock prices but likely damaging everyone else in the process.
However none of these issues are new or unique to the Trump administration. Federal intervention in the marketplace and socialization of risk was of comparable scope under Obama. Thanks to state aid, pressure, and financing, entities such as AIG, Caterpillar, foreign-owned banks, and General Motors were explicitly and directly supported by the state, not to mention the $800 billion bailout of some of his biggest campaign funders, namely Wall Street.
Whether or not this was good policy is subjective, but we can’t just call it pure capitalism when the Federal government owns shares in carmakers. But when China engages in state aid of its industrial champions (like nearly every modern rich economy did at some point) we threaten a trade war and incapacitate the WTO. Again to be clear, China’s interventions are on a much grander and explicit scale and the U.S. economy isn’t equivalent to China’s. Part of what I’m saying is maybe we shouldn’t think in such black and white terms of either/or Socialist or Capitalist, and most people dunking on China for unfair trade practices conveniently forget about similar U.S. practices. Except the Libertarians who are consistent at least.
Policies of China enacted on a grand scale are instructive by nature. Under Mao’s idiotic backyard blast furnace program and state-directed agriculture tens of millions of people died unnecessarily of hunger in one of the worst atrocities in history. After Deng Xiaoping introduced some market-based reforms, more people than ever before in history were lifted out of poverty in an incredibly short time. Hopefully we can learn something from this experience. Markets should be the default solution for economic organization because the vast complexity of interactions and incentives of billions of people is impossible for humans to comprehend or organize centrally, but this principle can be abused for propaganda purposes and intrude into realms where it is inappropriate. Most importantly, markets are not the solution to everything. Some problems do not have a market-based solution. Questions of basic education, law and justice, health care, and public infrastructure do not have market solutions.
In the most recent issue of the Economist, Bernie Sanders is called out for having a foolish plan to erase all student debt and the more “reasonable” plans of candidates Joe Biden and Mayo Pete are lauded for their more measured approach. Again, how could it possibly be paid for? Where would the money come from? Education isn’t free. The U.S. federal government has backed loans from private educational institutions that fail to teach while incurring sometimes hundreds of thousands of dollars in debt with atypically high drop-out rates. Once again, socialism is directed towards for-profit universities, fully subsidized and encouraged by the government. Again socialism for the rich, but the students get loaded with stupefying amounts of debt before they even begin working, putting a massive damper on earnings potential.
“This country has socialism for the rich, and rugged individualism for the poor.”
Martin Luther King, 1968
It doesn’t have to be like this. In Ukraine or Poland, a student can attend a five-year university for free. Those universities may not top world rankings but imagine what they could do if they had an economy the size of America’s. If people can get a master’s degree in a technical program for free in these countries, what’s stopping it from happening in America? As another comparison, when I had temporary residence in the Czech Republic, another poor post-soviet country, I was able to get fully covered health care for $100 per month. That covered absolutely any health-related procedure or visit that would ever need to be performed, and probably only cost that much because I was a foreigner. The quality of care may not be as good as in America but it’s a vastly poorer country. Why can’t we have these things in America? In any other country we would apply the term “corruption”, but in America we say it’s a “lack of political will.”
Sure America spends vast sums of money on health insurance and education, but the money doesn’t actually reach patients and students. It goes to vast corrupt institutions of well-connected plutocrats and middlemen who spend the money on bloated administrations and unnecessary layers of bureaucracy. Libertarian institutes like Cato argue that poor people have never had it better than today, because if you actually add in transfers, we spent tons of money on them! Well that is not factually incorrect as we do spend vast amounts of money on health insurance and educational loans and SNAP and all the rest, but the money isn’t benefiting the supposed recipients. A lot of it is eaten up by middlemen like health insurance companies and for-profit university shareholders. Again the money is funnelled to the donor classes in what we would call corruption in any other country, and the people on the bottom have to fight against constant introductions of means-testing, cuts and more and more soul-crushing bureaucracies.
Consider how much money is wasted on health insurance. Not health care, but the insurance part of it. Even small practices have specialist employees who deal with billing insurance companies, faxing paperwork and arguing over reimbursements. Students can now major in billing health insurance companies (it’scomplicated), a sign that maybe resources aren’t being spent in the best way here. The Mercatus Center, a Koch-backed libertarian outfit that is absolutely not supportive of Medicare For All released a report fretting about the price tag for the program. According to the report, government expenditures would be increased to pay all health-care expenses increasing the share of spending by the federal government, but overall expenditures for human beings would decrease, by about $2 trillion over ten years. Again the scale of graft and waste in the existing system is staggering, and I think this savings estimate is on the low side, considering the source of the research and support. This is of course just focusing on the economics and ignoring the large social costs and moral questions.
This isn’t to say that fiscal responsibility should be abandoned. We should have conversations about how to fund programs we as a society deem important. We should be cautious about borrowing against future generations to pay for our expenses today and we ought to be sure that our government is spending wisely with the money it does have. I believe that there are purely economic arguments to be made in favor of single-payer health care and universal free education, not to mention moral arguments, but that isn’t really the point I’m trying to drive home here. The point is that the media and politicians in this country have an endless supply of concern for fiscal rectitude when it comes to supplying Americans with basic amenities like food, shelter, and medical care but this intense scrutiny suddenly evaporates when we’re looking at splashing out trillions of dollars for tax cuts for wealthy individuals and corporations, or military hardware, or any other of the innumerable transfers of money from the taxpayers and future generations to elites.
Absolute cretins would have you believe that market forces would be a more efficient way of distributing health care, contrary to the experience in most parts of the developed world. The concept that people are informed consumers when it comes to health care is laughable. You don’t comparison shop MRIs, you aren’t going to check the reviews of hospitals while you’re having a heart attack, nobody makes a choice to get old or be born with health issues. Most people aren’t qualified to make rational choices about comparative cancer treatment costs and don’t want to spend time figuring out how to work in their overpriced insulin into their budgets. Only someone with a chronic case of Nudge-brain could possibly think healthcare should be treated as a marketplace. Even one of the most laissez-faire capitalistic governments on the planet, Hong Kong, has free at point of service universal hospital care and one of the highest life expectancy rates at 84 years versus the USA’s 78 years and dropping. And expanding insurance to be universal doesn’t make any sort of logical sense. As I wrote before, what’s the point of insurance if it’s subsidized by the government, you aren’t allowed to price risk (i.e. pre-existing conditions), and it’s universal? Why have the insurance layer there in the first place then? Corruption, or socialism for health insurance and pharmaceutical companies.
America is certainly fairly capitalist, but also fairly socialist in a big way already. Vast, unimaginable quantities of cash are borrowed and taxed and funnelled to the ultra-wealthy donor and plutocrat classes. If we’re going to ask hard questions about budgets and costs, maybe we should start with looking at the welfare programs for the rich instead of basic health care or education.