Adding video encoding support to your application is relatively straightforward with Amazon’s Video On Demand encoding pipeline infrastructure template.

This CloudFormation template provides you with:
- A S3 media source bucket where video files get uploaded, with an option to phase out media source files to long-term storage in Glacier.
- A DynamoDB table to track the status of the encoding and store all metadata about the source and output files.
- A series of Step Functions (Lambda state machines) to manage the stages of the pipeline.
- MediaConvert to do the actual video encoding work.
- An output S3 bucket for the encoded files and playlists, with a CloudFront CDN distribution in front.
- A SNS topic which publishes events to subscribers when media ingestion begins and when it completes, as well as if there is an error.
The one deficiency in the CloudFormation template provided by AWS is that it does not include the SNS topic as a stack output, which makes it harder to tie it into other applications. JetBridge hosts a version of the stack which includes the SNS topic output at https://ext.jetbridge.com.s3.amazonaws.com/vod/video-on-demand-on-aws.template.
You can deploy the stack here: 
Once the stack has finished launching, you can try uploading a video file into the source S3 bucket.
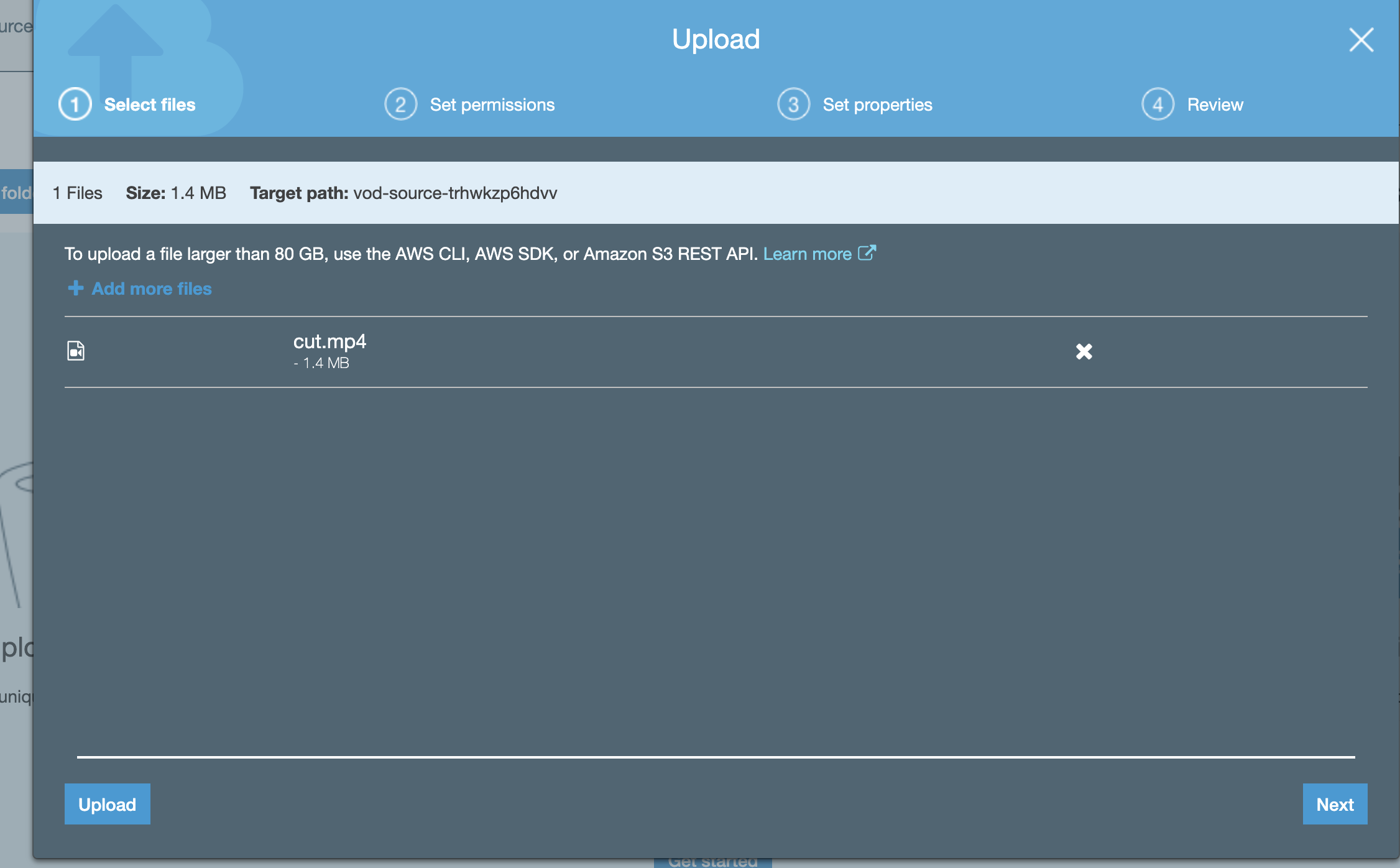
When files are added to the bucket a Lambda is automatically triggered that begins the ingestion and kicks it over to MediaConvert after generating a GUID to track the progress of the encoding.
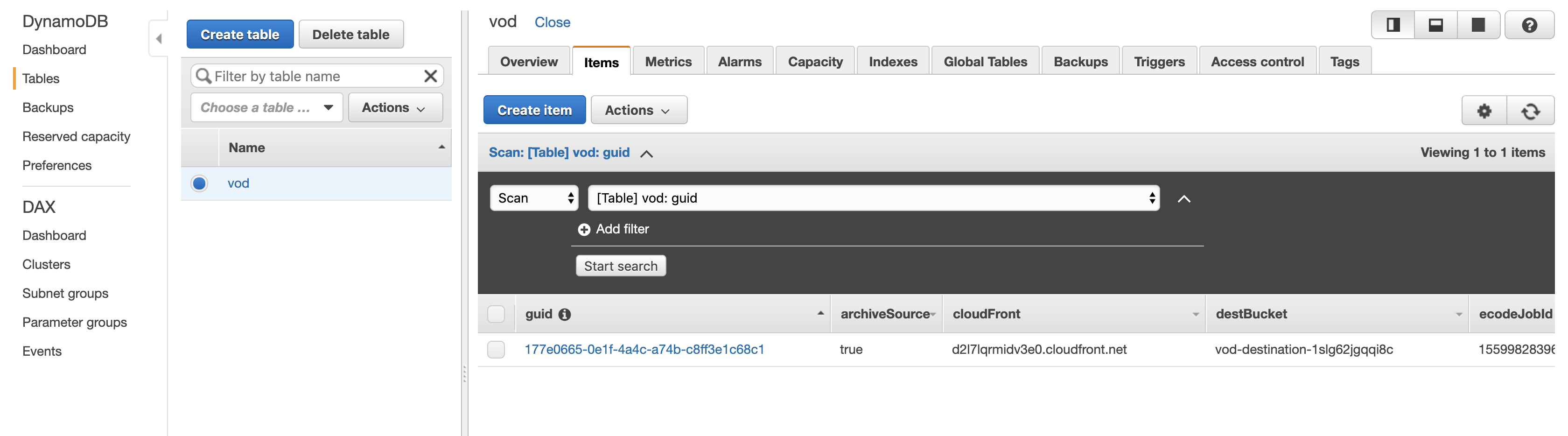
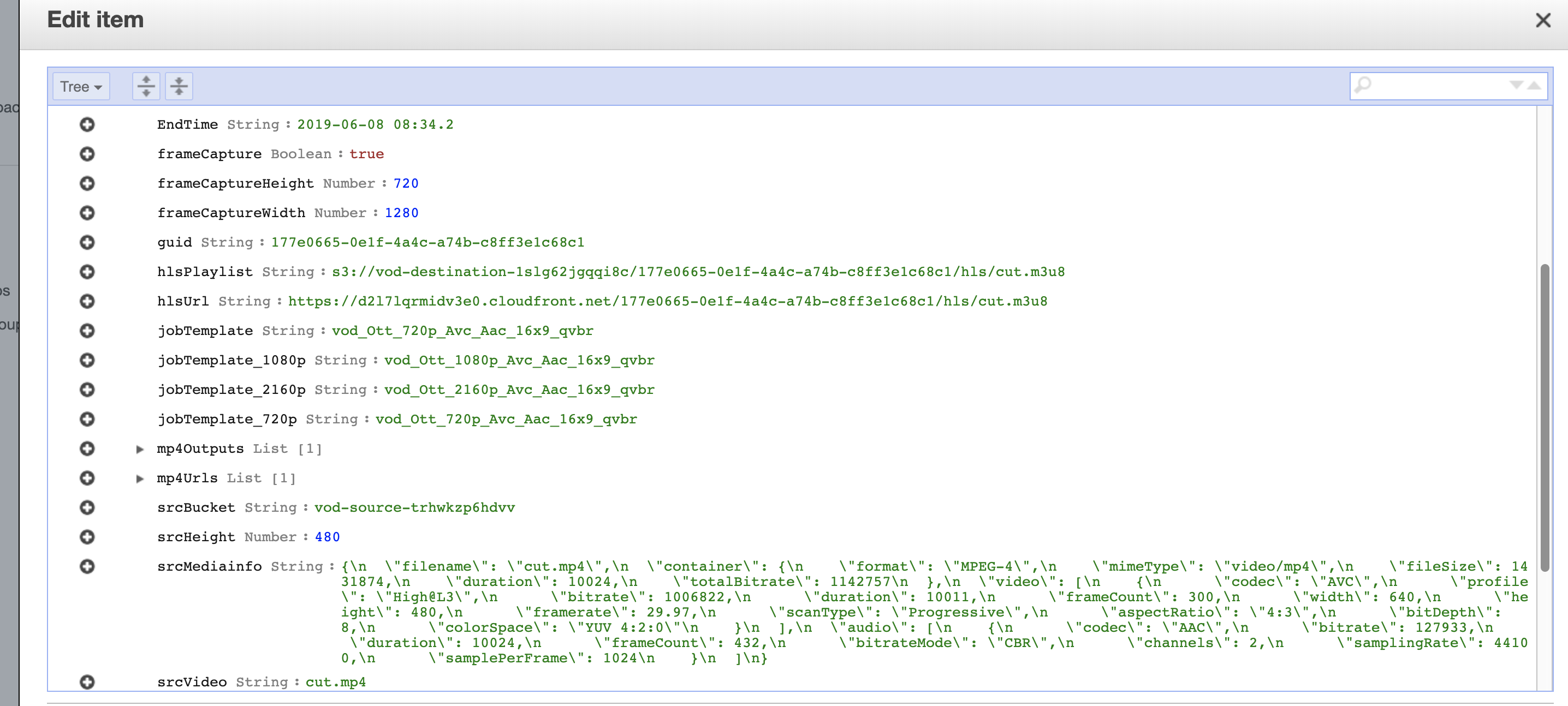
After the encoding is complete you will have an entry in the DynamoDB table with information about the media files and the outputs, including a HLS M3U8 (HTTP Live Streaming MP3 URL UTF-8 playlist) which can be used by any web or mobile client to stream your video at adaptable bitrates.
Integrating To Your Application
The VOD encoder pipeline is a pretty nifty example of how to use ready-made stacks of infrastructure, but what if you want to integrate this pipeline into your application? Let’s look at one way you can accomplish this.
Say you are building a CMS where you want users to be able to upload videos that can be streamed by clients. You will need a user interface for performing the upload and then a way to associate the results with that object when the encoding process completes or errors.
The flow from the application’s perspective will look like this:
- Register a Lambda for handling notifications from the VOD SNS topic.
- Create an object in your database to store the uploaded video. A row in a
videotable would suffice just fine. Make up a S3 key for this row (based on the video’s ID or better, UUID) and store it in thevideorow as well. - Generate a pre-signed S3 PutObject request URL (Python docs) for the media source bucket.
- On the browser side, upload the video file to the pre-signed S3 upload URL. Once the upload is complete the Lambda trigger will be automatically invoked, kicking off the encoding job.
- Process ingestion notification received from the SNS topic. This notification includes the UUID generated by the pipeline to keep track of your job and the original S3 key of the video file that was just uploaded. Store the VOD task UUID in your
videodatabase row associated with the S3 key. - When you receive a completion or error notification from the SNS pipeline, update the
videorow appropriately. You now have either a HLS playlist URL associated with yourvideoor an error message.
Registering For SNS Notifications
You can set up everything above by hand, but making reusable infrastructure is easier and more powerful. If you are using the Serverless toolkit you can use the SNS topic CloudFormation output (remember the one mentioned above that we had to add to the template?) to register a Lambda to listen for events:
functions:
vodSnsUpdateHandler:
handler: myapp.handler.vod_sns_update.handler
events:
- sns: ${cf:vod.SnsNotificationTopic} # cloudformation output
This will invoke the function myapp.handler.vod_sns_update.handler whenever a new message is published on the SNS topic in the CloudFormation stack named vod (that’s what I called it, you can change it if you really want).
Other CloudFormation Stack Outputs
Your application will also need to know the name of the source media S3 bucket to generate the presigned upload request as well as the name of the DynamoDB table to fetch the results from. Again, this example is for Serverless:
provider:
name: aws
...
environment:
S3_VOD_SOURCE_BUCKET: ${cf:vod.Source}
VOD_TABLE: ${cf:vod.DynamoDBTable}This has the effect of passing the source S3 bucket and DynamoDB table names from the VOD stack outputs into your application as environment variables.
S3 Presigned Upload
You can create a URL that you can give to a client to permit it to upload a file to a designated S3 key:
s3 = boto3.client("s3")
put_params = dict(Bucket=os.environ['S3_VOD_SOURCE_BUCKET'], Key=s3key)
expire = 3600 # one hour
url = s3.generate_presigned_url(
ClientMethod="put_object",
Params=put_params,
ExpiresIn=expire,
)
This URL can then be returned to a web browser which can then do a PUT to the URL with the contents of the file as the body of the request.

I recommend generating a S3 key in the form of: f"/video/{video.uuid}/media.mp4"
Processing SNS Notifications
This should be a Lambda handler that looks up the associated video entry in your database and updates it with the status published by the VOD pipeline. Some rough sample code:
import boto3
import os
import json
from myapp.db import db
from myapp.model.video import Video
from enum import Enum, unique
from typing import Optional
import logging
log = logging.getLogger(__name__)
@unique
class EncodingStatus(Enum):
new = "new"
ingest = "Ingest"
complete = "Complete"
error = "Error"
table = os.environ["VOD_TABLE"]
dynamodb = boto3.resource("dynamodb")
table = dynamodb.Table(table)
def handler(event, context):
records = event.get("Records", [])
with app.app_context(): # if you use Flask-SQLAlchemy
for record in records:
log.debug(f"Processing VOD SNS event...")
process_event_record(record)
db.session.commit()
return "ok"
def process_event_record(record: dict):
assert "Sns" in record
assert "Message" in record["Sns"]
message = json.loads(record["Sns"]["Message"])
# look up asset by key/bucket
src_video = message.get("srcVideo")
status = EncodingStatus(message.get("status", message.get("workflowStatus")))
guid = message.get("guid")
log.debug(f"Video: {src_video}, status={status}, guid={guid}")
if not src_video:
# this is missing in case of error
if status == EncodingStatus.error:
video = db.session.query(Video).filter_by(vod_guid=guid).one_or_none()
if not video:
log.warning(f"Got video GUID for unknown video {record}")
else:
video.encoding_status = status
log.warning(f"Got video encoding without video src {record}")
return None
# look up video by S3 key
video = Video.query.filter_by(s3key=src_video).one_or_none()
if not video:
log.warning(f"Could not find video {src_video}")
return None
# update video
video.vod_guid = guid
video.encoding_status = status
video.vod_last_message = message
video.hls_url = message.get("hlsUrl") if message.get("hlsUrl") else video.hls_url
thumbnail_urls = message.get("thumbNailUrl", [])
video.placeholder_url = thumbnail_urls[0] if thumbnail_urls else None
video_data_info = get_video_data_info(guid)
if not video_data_info:
if status == EncodingStatus.complete:
log.warning(f"Could not find data about encoding {record}")
return asset
src_media_info = video_data_info.get("srcMediainfo")
encoding_details = json.loads(src_media_info) if src_media_info else None
if not encoding_details:
log.warning(f"Could not find encoding info {record} // {encoding_details}")
video.duration = encoding_details["container"]["duration"] # ms
print(f"Media info: {src_media_info}")
db.session.commit()
def get_video_data_info(guid: str) -> Optional[dict]:
result = table.get_item(Key={"guid": guid})
return result.get("Item")
Conclusion
And now you have a powerful media encoding pipeline integrated into your application. Some features to note are :
- Thumbnail URLs are automatically generated.
- Media info is output which contains everything from duration to dimensions to colorspace.
- HLS, DASH, and MP4 outputs are produced.
- Quality-Defined Variable Bitrate encoding is used by default.
- Microsoft Smooth Streaming (MSS) and Common Media Application Format (CMAF) are also supported.
Hope that was helpful!

After uploading the first video file, I get the error “stdout maxBuffer exceeded” from the workflow at vod-mediainfo. Apparently when calling MediaInfo.command. How to resolve please?
LikeLike
Wow I have no idea sorry. You may wish to look at the lambda source.
LikeLike