As I have a dedicated room for my office in our house and work from home, my wife doesn’t always know when I’m in a meeting. To me the obvious technical solution here was to hook up a networked lightbulb and control it with a big illuminated button on my desk, changing it from blue to red whilst I Zoom.
System Overview
I used a $5 RISC-V single-board computer called the Milk-V Duo. This thing is probably rather overpowered for this application but it runs Linux and is easy enough to configure. I saw a great review of it on YouTube randomly which inspired me to try it out. It’s super cheap and I’m a big RISC-V booster because it is a non-patent-encumbered CPU architecture and it’s from Berkeley.
There’s a nifty little I/O board it slots into to provide an ethernet jack.
For the lightbulb, I used a Philips Hue bulb. At first I tried connecting to the bulb directly using Bluetooth, which is technically possible but ended up being a nightmare to control. Philips does not seem to provide much in the way of documentation and I wasted an evening trying to discover how to properly issue commands to change the color via Bluetooth. It didn’t go very well and seemed to reset itself with a new address whenever I messed up. I gave in and got a Hue Bridge which improved things considerably; I can control my various bulbs by speaking REST with the Bridge and I can share control of the bulbs with my wife.
Changing Colors
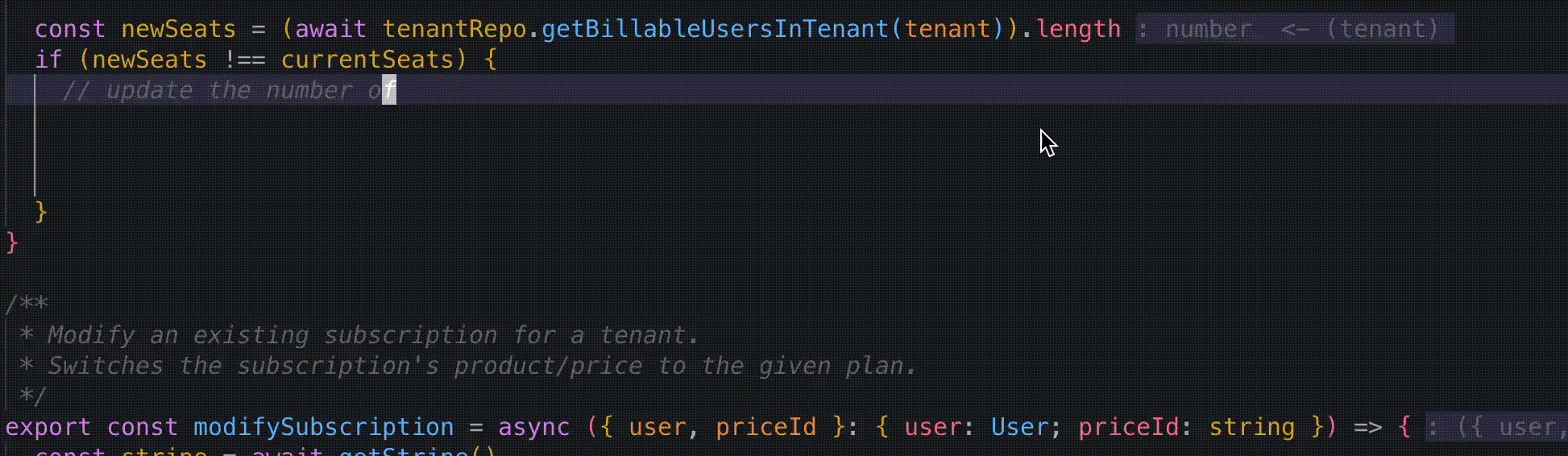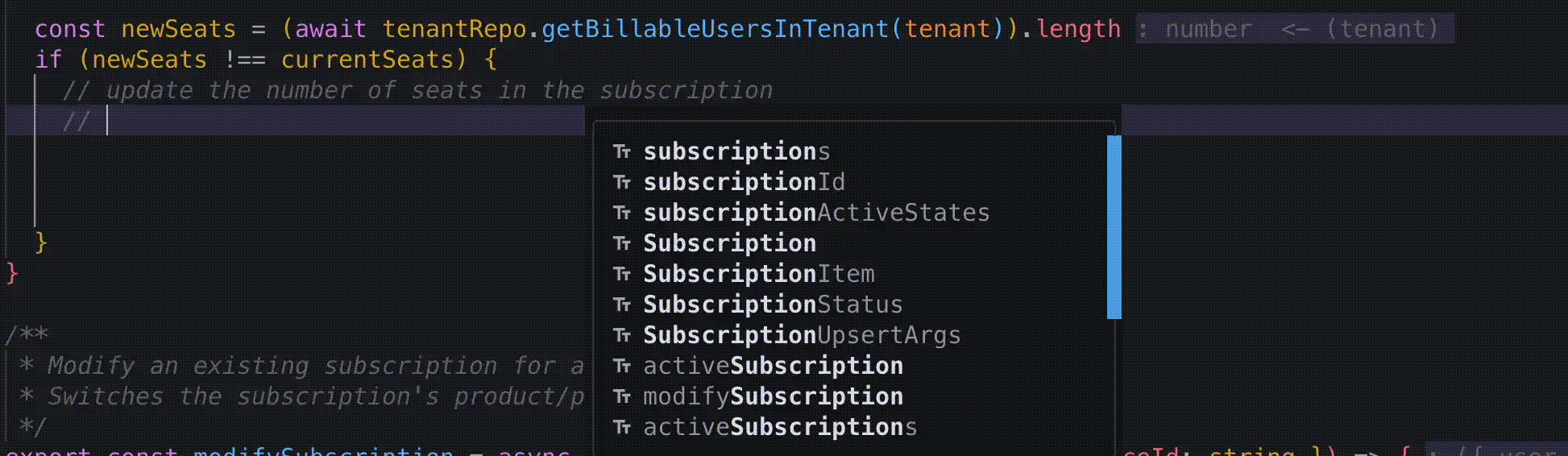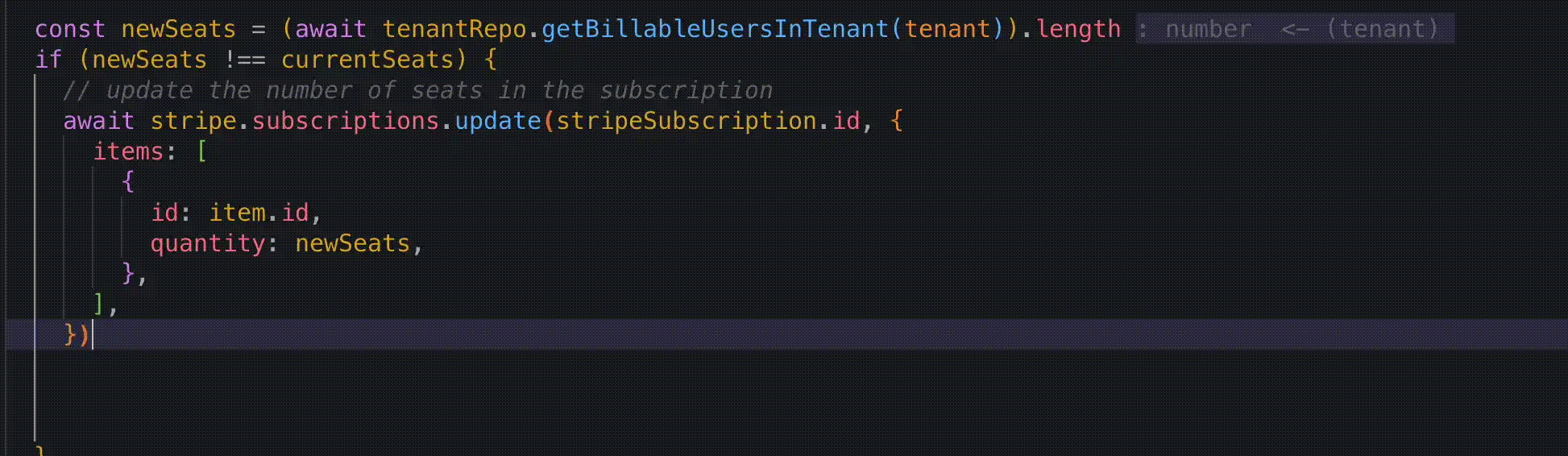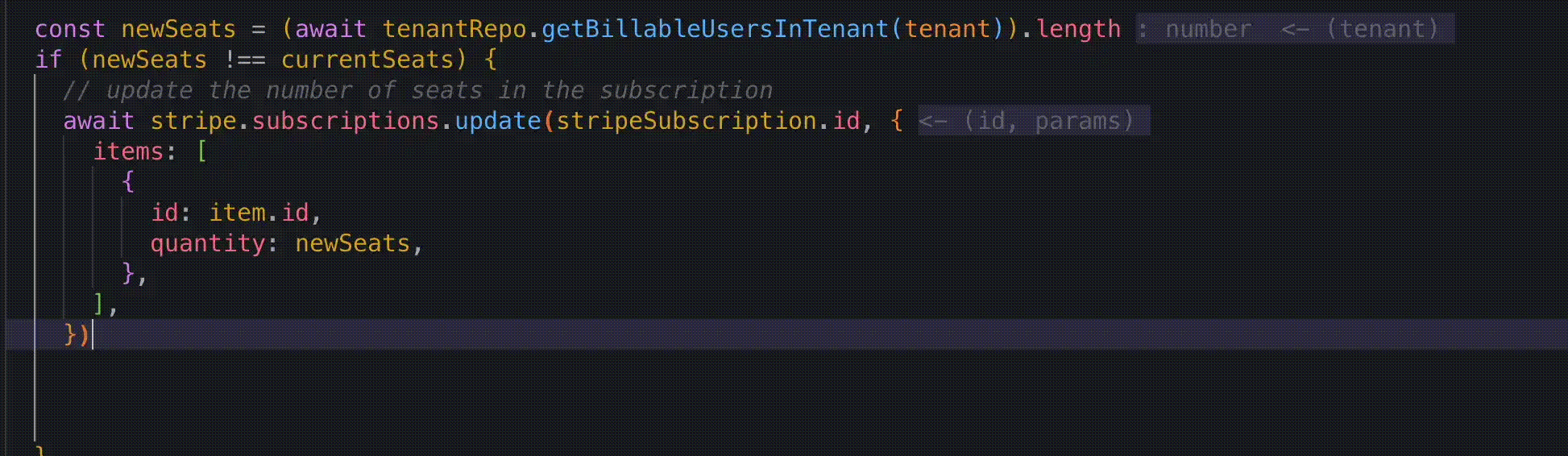
You can communicate with the bridge once you set up an access token and list the lights. For example to change the light to purple:
And to change it to red, a hue value of 2000 does nicely.
The Button
I prototyped the input on a breadboard with a tiny switch I had lying around first.
But for a system like this you absolutely need a more sizable solid button with a light on it so you know when it’s active. After extensive searching I found this nice button and a housing it fits in perfectly.
Once it arrived, I connected up the Button of Moderate Gravitas.
Software
The other piece of the project was creating some software to run on the Milk-V. What it needs to do:
Open a GPIO (general-purpose input/output) pin on the circuit board to be our input.
Open a GPIO pin to be output, this will control the LED inside the button to show if it’s red or not.
The hardware switch (the button) will determine if high or low voltage is connected to the input pin so we can decide what color the lightbulb should be.
Send a HTTP request to the Hue bridge to tell it to change colors.
With some experimentation and help from ChatGPT, I created a Rust program that makes use of the gpio_cdev library to use the newer linux /dev/gpiochip0 GPIO user-space interface.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
It’s not too hard to build the application for the Milk-V. You can cross-compile it and static link it to produce a self-contained binary that will run on a RISC-V system.
You need to create a .cargo/config.toml file with:
Getting an OS image for the Milk-V duo took a bit of effort. They provide a buildroot system you can customize if desired. This wasn’t too bad but it took me a few tries to figure out how to copy over the binary to the system. It runs busybox and dropbear, a very lightweight system and SSH server which doesn’t support SFTP. But you can SCP it over using the -O flag which uses an older method to send a file over SSH to the target device:
Then all that remains is to create an initscript to start the program on boot. Now you have a sweet button to change the color of a lightbulb somewhere else.
Is GraphQL a tool that will make your life better or worse?
TL;DR: as with any technology it depends on your situation and needs. There are real benefits for developer experience and solving many related problems with a cohesive architecture, but it’s not just a simple drop-in replacement for REST, HATEOAS or {g,t}RPC. GraphQL is better for serious projects with interactive user interfaces and a rich relational data model. If you are willing to adopt a new paradigm and use it as a foundation for a new application, it can be worthwhile and make your life moderately easier.
I’ll summarize the tradeoffs here and go into more detail with examples and explanations afterwards.
Pros:
Can obviate the need for a web framework or server entirely
End-to-end type safety
Great for language-agnostic APIs (vs. something like tRPC) and code generation
Presents a unified client interface that can weave together independent services or functions on the backend
Implement simple handlers without even talking to your application backend
Add (simple) declarative access controls
Smart caching
Real-time push events (WebSockets) are solved for you
Documentation generation for free (like OpenAPI but better)
Client has more control over what data is fetched retrieved
Designed for data structured as a graph (obviously) or hierarchical/relational data
Fetch all the data the application needs in a single request (great for mobile apps)
Can segregate your application services into independent units to get the benefits of a microservice architecture without the overhead and complexity
Cons:
Requires some specialized tools to work with compared to REST
Not as universally understood and adopted as REST
Can be more strict than necessary for your project
Requires some sort of extra schema definition step to add a new “endpoint”
Not necessarily suitable for public/unauthenticated APIs
No support for untyped/unstructured fields, just “string”
Caveats
I’m writing based on my experience with particular implementations of GraphQL servers and clients. My setup has been AWS AppSync, graphql-code-generator, TypeScript, React, and Apollo Client. Some of my opinions are relevant to this setup and some are broadly applicable. I think AWS and React are common enough technologies that it’s worth looking more at some concrete implementation details there.
Other Opinions
GraphQL was designed and created by Facebook, a company that seems to make a lot of money and build performant software and complex user interfaces that work across a variety of platforms. They are also behind React and are worth taking seriously when it comes to web technologies, even if they were originally cursed with PHP and MySQL.
Anecdotally I’ve seen some articles and videos across the transom bagging on GraphQL. I recently listened to a terrific interview on the Changelog podcast diving deep into API design, and the design of hypermedia and HATEOAS which I highly recommend. There was some very light and admitted highly subjective criticism of GraphQL on it but they are keeping an open mind. I hope to fill some open minds with my arguments for and against GraphQL, which is the best you can do with any technology other than say “it depends.” The episode and transcript can be found here:
GraphQL is an attempt to add another layer of abstraction and standardization on top of traditional HTTP-based APIs. There’s nothing amazingly groundbreaking about it, but it provides for a standard architecture that enforces many practices that can be beneficial for people building moderately serious apps. You must define a schema for the types of requests your clients can make, what fields appear in the request and response bodies, what changes can be subscribed to (think WebSockets), and extensions that can be implemented by the gateway (think permissions or @deprecated).
This schema can be derived from code or written before code. It contains enough information to generate types so your clients and servers know exactly what will be in a given request, which is also enabled by the validation that will be automatically performed to ensure all requests and responses strictly conform to the declared schema. So as far as checking types of data or getting only the fields you explicitly allow in a request, that is one less thing to worry about on the server side and is a more secure default than REST APIs which allow the client to send any sort of data and fields it pleases with a request. The schema also enables documentation, client generation, a fully discoverable API, and a playground for testing requests. Very similar to what you get if you use OpenAPI (aka Swagger) generation tools with REST APIs, but in my opinion it’s much smoother and pleasant compared with OpenAPI. When you define an operation (equivalent of an endpoint), it must be a query, mutation, or subscription. This is very much like HTTP verbs like GET and POST, but more helpfully explicit and strict about the semantics.
The API discovery of fields and operations gives a bit more flexibility in API design and the actual work that must be done to make sure the client can retrieve all the data it needs in a single request. I’m going to borrow the examples from graphql.org here:
On the left is a query which is asking for two separate pieces of information at the same time: give me the name of hero and give me the name of the droid with id2000.
The schema definition and server implementation can make many fields on objects like hero or droid available to be queried, optionally spawning additional requests to fulfill the request. This lets the API designer expose all the data they deem necessary for the client to have at some point without having to define endpoints or parameters to handle every permutation of data fetches and information a client may wish to display in a given interface. It pushes a little more work onto the client side of things but in a very natural way. Let the client decide for a given situation what data it needs, ask the server, which then will issue the appropriate requests to fulfill the request. This may sound a bit like a “backend for frontend” often implemented in microservice architectures. GraphQL is a wonderful replacement for a BFF.
A Replacement for Web Frameworks
This is going to be controversial statement but you can replace your web server, web framework, DTOs (data transfer objects, also called schemas), OpenAPI generation tooling, BFF, and application load balancer with GraphQL. It solves all of these problems for you in an elegant and well-thought-out cohesive architecture. But it is a different paradigm than your typical backend developer is used to.
Boring History
As a certified Old Person building web applications since about 2000, I’ve encountered a good number of web frameworks. Perl, Python, Java, Node, Ruby, they’re all the exact same thing from Catalyst to Flask to Spring to Express to Nest to Rails. In a nutshell they:
Let you map routes to function handlers
Define what shape data should be in for requests and responses
Validate API requests
Run in some container to service requests
They typically have some other helpful things like ORM integration and middleware but these are trivial to incorporate if desired.
What? How Can I Live Without A Web Framework??
Do I detect a note of panic? Relax. GraphQL handles these things for you. It maps requests to handlers, strictly defines what shape data will be in going in and out of your endpoints, and takes care of the HTTP request handling layer for you. So you can define a schema and then functions which are invoked as needed to service client requests, possibly in parallel or in response to certain fields being requested by the client.
Arguably at the end of the day we have in its end result the same functionality whether we use a web framework or GraphQL, but I believe the bundling of this functionality with the extra thought and care that has gone into making GraphQL a more modern solution is worth serious consideration for new projects. Web application frameworks haven’t changed in twenty years, best practices have evolved since then. In the end you can achieve the same results with CGI scripts or PHP 3, or <form> tags and jQuery, but we know that there have been advancements in tooling and architecture since then.
Maybe I Do Need A Web Framework?
As I started off with, I am absolutely not arguing GraphQL is better in every way or should be used in all situations. There are a great many valid reasons for not choosing to adopt GraphQL for your project. A few off the top of my head:
Adding a new GraphQL-based service when you already have other APIs (REST or otherwise). GraphQL is a terrific unifier of services but a big ask of teams to adopt incrementally. Managing tooling for two API paradigms sounds like extra suffering. I will point out that you can use a REST API Gateway as a data source for an AppSync GraphQL service though.
Small projects. Often I am working on projects that are business-critical, involve large relational databases, will be worked on and maintained actively for years. If you want to throw together a small project or a prototype, the extra overhead is not worth it. The payoffs come with larger applications.
When your frontend and backend are tightly coupled. GraphQL adds an extra layer of abstraction which is extraneous if your backend and frontend are part of the same application. For example if you are using NextJS as both client and server, I would recommend server actions or tRPC.
Public APIs. If you are building an API which does not require authentication, or is designed to be easy to consume by clients outside your organization, I would advise sticking to something everyone understands and can be easily tested with tools like CURL. If you want other developers to get up and running and consuming your API with a minimum of extra obstacles, just stick with REST like everyone else.
However if you are embarking on a greenfield, serious project and you expect your API to scale with your organization and provide a high level of strictness and clarity and documentation, GraphQL may be a strong candidate.
Type Safety
I have similar feelings about GraphQL as I do about TypeScript. Sure, people have been building web applications just fine thank you with REST and JavaScript for many years, maybe around 25 at this point which is a lifetime in an engineer’s career. But there comes a point, maybe after another late-night debugging session where you eventually discover some mistyped parameter or property that shouldn’t have existed at runtime is ruining your weekend. Maybe you wonder, why do all these things have to be runtime errors? Maybe the Python heads don’t know there is a better way and think all errors should be runtime errors. I don’t know.
GraphQL and TypeScript ask a bit more of you, the person designing the API or writing the code to implement it. It’s more steps to solve the same problem and you just want to close this ticket. Why waste my time? The answer is that our tools can yell at us before we ship the code, not after. Obviously not in all cases, but many classes of bugs become less likely to happen at runtime, which does save us time and suffering in the long run. They increase maintainability, readability, code completion, AI copilots, and documentationability.
Same reason we write tests. It takes more time to write tests than to not write tests, but it pays off in the long run if we think about the runtime bugs we avoid and the safety we get when refactoring code, and the lower likelihood of someone less familiar with the system breaking other things in a few years time when they try to change something. Again not every software project needs tests, but you know who you are.
GraphQL’s strictness is especially helpful if annoying in the context of an API. A published API is a contract with your clients you must not break. If a client relies on a username field being present in some endpoint, you must keep that field around. If you want to move or rename the field or make it a different type, you risk breaking every old version of your clients which still expect that field to exist with a particular type. GraphQL doesn’t solve the problem by allowing you to just change schemas up on your clients as you like, but it can alert you to the fact you are making a backwards-incompatible schema change and yell at you. This is a very useful CI action to run. For example the graphql-inspector:
Because there’s nothing worse than accidentally pushing an API change that breaks every client. These are the kinds of validations we can leverage with GraphQL.
GraphQL Server
You do of course need some software that performs the duties of a GraphQL API server. There are many very featureful and robust options like Hasura and Apollo, with features like taking your existing Postgres database and generating operations and types, or federation where you can have multiple servers handling different pieces of your graph.
Myself, I always default to using an AWS service if it is good enough to suit my needs. It’s not because AWS has the greatest version of every service you will never need. Reasons why:
The more infrastructure Amazon runs instead of me, the better.
It will be more reliable than if I run it myself
I don’t have to maintain it
They have great documentation and support and monitoring
I don’t ever have to think about scaling anything
AWS services are designed to work with each other. You end up with a cohesive architecture that is more than the sum of its parts.
Integration with distributed tracing
Integration with other AWS data sources
Can run queries on RDS directly
Can query DynamoDB directly
Integrated authentication with Cognito
Pay-as-you-go billing. Great for prototyping on the cheap but being able to scale to handle serious volume without changing anything.
AWS AppSync
So I’ve been using AWS AppSync. It’s a bit oddly named but it’s a serverless GraphQL API. You upload a schema to it, define how users authenticate to it, and then connect operations to resolvers. You can tell it to directly query RDS or DynamoDB, you can write JavaScript resolvers that are executed inside AppSync (this is very cool but also maybe unwieldy to maintain or debug, I would compare it to using stored procedures in your DB instead of application code), and you can use lambda functions to handle requests. It can handle caching and tracing for you.
A powerful architecture is to use a serverless GraphQL server and functions defined for most of your application query, mutation, and subscription operations. Depending on your setup and needs this can give you many of the benefits of a microservices-style architecture without all the headaches and overhead introduced. You may have different problems (mostly cold starts) but I am a big of it regardless.
To give an example, suppose a client runs a getProfile query. You want some business logic to grab the currently authenticated user’s profile information from the database and return it. You would create a standalone lambda function in whatever language you like that is called when the getProfile query is performed, do your business logic, and return the result. AppSync handles the request/response validation and authentication and dispatch. This function is self-contained, not connected to anything else in your application, which has some consequences:
You can deploy new versions of this function without changing anything else in your application, if you want.
You can define scaling limits, memory limits, and timeout for this function, if you want.
You can define exactly what permissions the function has if you want to, what security groups it’s in, its IAM role. This is the absolute maximum application of the principle of least privilege, if fine-grained security is important for you.
You can write it in whatever language you want, build it with whatever tooling you want.
Different teams and projects can manage different subsets of functions, enabling teams to work independently but each be contributing to a unified service.
These are all optional benefits. You can also use a single IAM role and toolchain and language and limits for all functions in your application, but you also have the flexibility to slice up pieces of your services into independent units to avoid a monolith or big ball of mud situation. You can create a “monolith” library of all of your business logic and repositories but package it as separate functions. Again, if you want. You can also create a single resolver function that handles all requests if you prefer simplicity. Or do both!
This architecture is most suited to compiled languages (like Rust or Go) or JavaScript/TypeScript because each function should be small and self-contained. This is where JavaScript’s tree-shaking tools really shine. If your function loads some data from the database and imports some functions, that is all of the code that will be in your function. Your codebase may grow but the resolver functions stay the same size. If you want you can have one large monolithic-style library, or a set of libraries, where each resolver function only pulls out the pieces it needs from the library and compiles or bundles it into a small piece of code that is invoked on-demand by your GraphQL server. Basically any language should be fine for this setup unless it’s Python.
In my opinion this is a wonderful modern application of the UNIX tool philosophy: do one thing and do it pretty well. Create small self-contained units that can be assembled by the user to suit their needs.
DALL-E really let me down here.
Another thing AppSync handles for you are subscriptions. These let your client application subscribe to events or data updates in real-time. Setting up and administering your own WebSocket services can be a giant pain in the ass, especially if behind a load balancer. GraphQL and AppSync make this Just Work and Not Your Problem.
My biggest problem with AppSync is that it does not support unauthenticated requests. Any application will have a need for these, for example handling signup or forgot password flows (arguably these can be handled out of the box by Cognito but you will have other needs). So your application may need something like a REST API to fall back on for these types of requests or to use an unauthenticated Cognito identity pool role (cool although a pain to set up). I hope AWS adds a better solution some day.
Just REST With Extra Steps?
Some feedback from my coworkers when building a project making heavy use of GraphQL was “it feels like REST with extra steps.” Which is absolutely true, though the number of extra steps can depend quite a bit on your setup, like if you’re doing code-first or schema-first, need to run a code generation step, and depending on how you consume the API.
Speaking as generally as possible, it’s likely building a REST API will be faster and easier than GraphQL. If these are your priority, you probably want REST. It’s standard, you can build new endpoints quickly without having to define the request and response shapes, polymorphic types are much easier to deal with, you probably don’t need any code generation or extra tooling, and everyone’s familiar with it.
GraphQL will probably be more complex but this complexity pays off depending on your application. Your technical and business requirements are the deciding factor. If end-to-end type safety and validation is important to you, or self-documenting APIs, or real-time subscriptions, or you need to do relational queries via your API, or want client generation for different platforms, GraphQL may save you time and be more maintainable.
If your application isn’t so serious, or is small and unlikely to grow into a large API surface, if it’s just you or a small team, or if your frontend and backend can be tightly coupled, I would probably do a REST API due to its simplicity and low overhead.
GraphQL vs. REST: When to Use Each
When to Use GraphQL
GraphQL is particularly effective in scenarios with:
Complex Data Requirements: When applications need to retrieve complex, nested data structures in a single request, GraphQL provides a more efficient way to query the exact data required.
Dynamic Queries: In cases where clients may need to change their data requirements frequently, GraphQL enables clients to request only the fields they need, reducing the payload size and improving performance.
Multiple Resources: If your application architecture involves multiple resources that often link together, GraphQL allows for a more streamlined approach to fetching related data in a single round trip.
Real-Time Functionality: Applications that benefit from real-time updates, such as chat applications or live dashboards, can leverage GraphQL’s subscription capabilities for handling real-time data effortlessly.
When to Use REST
If you’re looking for:
Simplicity and Speed: For simple applications with straightforward API needs, REST provides a quick and easy method to implement CRUD operations with standard HTTP verbs.
Less Frequent Changes: If your API endpoints and data requirements are stable and unlikely to change frequently, REST’s fixed endpoints reduce complexity and can be more straightforward for consumer integration.
Well-Defined Resource Models: When your application is built around a clear resource structure that maps directly to HTTP verbs, REST’s resource-oriented approach is a natural fit, making it easy to understand and implement.
Support for Caching: RESTful services often leverage HTTP caching mechanisms effectively. If caching responses is a key consideration for performance, REST can provide built-in support for caching through standard HTTP headers.
In conclusion, evaluating your application’s specific needs will guide your choice between GraphQL and REST. For complex, dynamic data interactions with a focus on developer flexibility and efficiency, opt for GraphQL. For simpler use cases with stable requirements and resource-oriented designs, REST remains a robust and effective solution.
V8, the JS runtime underneath Chrome, Edge, Node, Deno, and Electron, got some useful improvements for developers.
One is a new simple (single-pass SSA, CFG, IR builder) JIT for short-lived programs like command-line tools or serverless functions. Called Maglev.
I’m very interested how it will stack up against AWS’s low-latency runtime (LLRT) that will be compatible with “some of” Node, also optimized for start-up time instead of long-running applications which benefit more from a more complex and rigorous optimizing JIT.
Another bonus from v8 12.4 is new JS language features:
– Array.fromAsync() takes an iterable of promises and returns an array of awaited items in serial fashion. It can be used with async generator functions too.
– New Set methods like intersection, union, etc. I assumed these would have to get added at some point because it’s so obvious to have them and they’re a great DX in langs like Python and Kotlin.
– Iterable helper methods. These let you do some more functional-style things with iterators like .filter(), .map() and all sorts of things you can do on arrays. But an iterable can be an infinite generator so these methods get applied as you grab more values from the iterator (with .next()) instead of all at once as on an array.
Based Jensen Huang, CEO of Nvidia, which is one of the largest companies in the world by market cap now, said this February that people should stop learning to code. He was making the point that people will soon be able to instruct computers with natural human language to get what they want out of them. If you’re a younger person or a parent, it’s worth asking now, is there still value in learning to program a computer or get a computer science education?
I respect Jensen enormously and believe he is worth taking seriously, even if he used to slang 3D-Sexy-Elf boxes to gamers. Also to recognize his bias as the manufacturer of the picks and shovels for the current venture gold rush and his incentives to pump up the future perceived value of his company’s stock, if such a thing is even possible at a P/E of 73.
My perspective is as a software practitioner, having been a professional software “engineer” for two decades now, consulted and built companies on software of my design, and writing code every day, something I do not believe Mr. Huang is doing. Let’s start with a little historical perspective.
Past Promises To Eliminate Programmers
Programming real physical computers in the beginning was a laborious process taking weeks to rewire circuitry with plugboards and switches in the early ENIAC and UNIVAC days.
As stored-program machines became more sophisticated and flexible, they could be fed programs in various computer-friendly formats, often via punched cards. These programs were very specific to the architecture of the computer system they were controlling and required specialized knowledge about the computer to make it do what you wanted.
As the utility of computers grew and businesses and government began seeing a need to automate operations, in the 1950’s the U.S. Department of Defense along with industry and academia set up a committee to design a COmmon Business-Oriented Language (COBOL) as a temporary “short-range” solution “good for a year or two” to make the design of business automation software accessible to non-computer-specialists, across a range of industries and fields to promote standards and reusability. The idea was:
Representatives enthusiastically described a language that could work in a wide variety of environments, from banking and insurance to utilities and inventory control. They agreed unanimously that more people should be able to program and that the new language should not be restricted by the limitations of contemporary technology. A majority agreed that the language should make maximal use of English, be capable of change, be machine-independent and be easy to use, even at the expense of power.
The general idea was that now that computers could be instructed in the English language instead of talking to them at their beep-boop level, and programming could be made widely accessible. High-level business requirements could be spelled out in precise business-y language rather than fussing about with operands and memory locations and instruction pointers.
In one sense this certainly was a huge leap forward and did achieve this aim, although to what degree depends on your idea of “widely accessible.” COBOL for business and FORTRAN for science and many many other languages did make programming comparably widely available in contrast to before, although the explosion of personal computers and even more simplified languages like BASIC helped speed things along immensely.
Statistically, the number of people engaged in programming and related computer science fields grew substantially during this period from the 1960s to the year 2000. In the early 1980s, there were approximately 500,000 professional computer programmers in the United States. By the end of the 20th century, this number had grown to approximately 2.3 million programmers due to the tech boom and the widespread adoption of personal computers. The percentage of households owning a computer in the United States increased from 8% in 1984 to 51% in 2000, according to the U.S. Census Bureau. This increase in computer ownership correlates with a greater exposure to programming for the general population.
Every advancement in programming has made the operation of computers more abstract and accessible, which in my opinion is a good thing. It allows programmers to focus on problems closer to providing some value to someone rather than doing undifferentiated mucking about with technical bits and bobs.
As software continues to become more deeply integrated into every aspect of human life, from medicine to agriculture, to entertainment, the military, art, education, transportation, manufacturing, and everything else besides, there has been a need for people to create this software. How many specialists will be needed in the future though?
The U.S. Bureau of Labor Statistics projects the demand for computer programmer jobs in the U.S. to decline 11% from 2022-2032, although notes that 6,700 jobs on average will be created each year due to the need to replace other programmers who may retire (incidentally, COBOL programmers frequently) or exit the market.
So how will AI change this?
Current AI Tooling For Software Development
I’ve been using AI assistants for my daily work, including GitHub’s Copilot for two and a half years, and ChatGPT for the better part of a year. I happily pay for them because they make my life easier and serve valuable functions in helping me to perform some tasks more rapidly. Here’s some of the benefits I get from them:
Finishing what I was going to write anyway.
It’s often the case that I know what code needs to be added to perform some small feature I’m building. Sometimes function by function or line by line, what I’m going to write is mostly obvious based on the surrounding code. There is frequently a natural progression of events, since I’m giving the computer instructions to perform some relatively common task that has been done thousands of times before me by other programmers. Perhaps it’s updating a database record to mark an email as being sent, or updating a customer’s billing status based on the payment of an invoice, or disabling a button while an operation is proceeding. Most of what I’m doing is not groundbreaking never-before-seen stuff, so the next steps in what I’m doing can be anticipated. Giving descriptive names to my files, functions, and variables, and adding descriptive comments is already a great practice for anyone writing maintainable code but also really helps to push Copilot in the right direction. The greatest value here is simply saving me time. Like when you’re writing a reply to an email in Gmail, and it knows how you were going to finish your sentence, so you just tell it to autocomplete what you were going to write anyway, like adding “a great weekend!” to “Have” as a sign-off. Lazy programmers are the most productive programmers and this is a great aid in this pursuit.
Saving me a trip to the documentation.
Most of modern programming is really just gluing other libraries and services together. All of these components you must interface with have their own semantics and vocabulary. If you want to accomplish a task, whether it’s resizing an image or sending a notification to Slack, you typically need to do a quick google search then dig through the documentation of whatever you’re using, which is also often in a multitude of formats and page structures and of highly varying quality. Another time saver is having your AI assistant already aware of how to interface with this particular library or service you’re using, saving you a trip to the documentation.
Writing tests and verifying logic.
It should be mentioned that writing code is actually not all that hard. The real challenge in building software comes in making sure the code you wrote actually does what you expected it to do and doesn’t have bugs. One way we solve this is by writing automated tests that verify the behavior of our code. It doesn’t solve all of our problems but it does add a useful safety net and helps later when you need to modify the code without breaking it. Copilot is useful for automating some of the tedium of this process.
Also sometimes if I have some piece of code with a number of conditions and not very straightforward logic, I will just paste it into ChatGPT and ask me if the logic looks correct. Sometimes it points out potential issues I hadn’t considered or suggests how to rewrite the code to be simpler or more readable.
Finding the appropriate algorithm or formula.
This is less common but sometimes I have some need to perform an operation on data and I don’t know the appropriate algorithm. Suppose I want to get a rough distance between two points on the globe, and I’m more interested in speed rather than accuracy. I don’t know the appropriate formula off the top of my head but I can at least get one suggested to me and it’s ready to convert between the data structures I have available and my desired output format. AIs are great at this.
Problems With “AI” Tooling For Building Software
While the term artificial intelligence is all the buzz right now, there is no intelligence to speak of in any of these commercial tools. They are large language models, which are good at predicting what comes next in a sequence of words, code, etc. I could probably ask one to finish this article for me and maybe it would do a decent job, but I’m not going to.
Fancy autocomplete is powerful and helps with completing something you at least have some idea of how to begin. This sort of tool has fundamental limitations though especially when it comes to software. For one thing, these tools are trained with a finite context window size, meaning they have very small limits in terms of how much information they can work with at any time, can’t really do recursion, and can’t “understand” (using the term very loosely) larger structures of a project.
There are nifty demos of new software being created by AI, which is not such a terribly difficult task. I’ve started hundreds of software projects, there’s no challenge in that. I admit it is very neat to see a napkin drawing of a simple web app turned into code, and this may very well one day in the medium term allow non-technical people to build simple, limited, applications. However, modifying an existing project is a problem that gets drastically harder as the project grows and evolves. Precisely because of the limited context window, an AI agent can’t understand the larger structures that develop in your program. A software program ends up with its own internal representations of data, nomenclatures, interfaces, in essence its own domain-specific programming language for solving its functional requirements. The complexity explodes as each project turns into its own deviation from whatever the LLM has been previously trained on.
Speaking of training, another glaring issue is that computer programmers (I mean, computers that program) only know about what they’ve seen before. Much of that training input is out of date for one thing. Often when I do use a LLM to help me use an API, it will give me commands for an older version of that API which are no longer correct or relevant. New technologies it has particular trouble with, for example giving me all kinds of nonsense about the AWS CDK. But worse than that, anything created after about 2022 or 2023 which be very hard for LLMs to train on because of the “closed loop” problem. This occurs when LLMs begin to learn from their own outputs, a scenario that becomes increasingly likely as they are used to generate more content, including code and documentation. The risk here is twofold: first, there’s the potential for perpetuating inaccuracies. An LLM might generate an incorrect or suboptimal piece of code or explanation, and if this output is ingested back into the training set, the error becomes part of the learning material, potentially leading to a feedback loop of misinformation. Second, this closed loop can lead to a stagnation of knowledge, where the model becomes increasingly confident in its outputs, regardless of their accuracy, because it keeps “seeing” similar examples that it itself generated. This self-reinforcement makes it particularly challenging for LLMs to learn about new libraries, languages, or technologies introduced after their last training cut-off. As a result, the utility of LLMs in programming could be significantly hampered by their inability to stay current with the latest developments, compounded by the risk of circulating and reinforcing their own misconceptions.
If we get rid of most of the programmer specialists as Mr. Huang foresees, then more code generated in the future will be the product of computery-type programmers. They learn by example, but will not always produce the best solution to a given problem, or maybe a great solution but for a slightly different problem. Sure, this can be said about human-style programmers as well, but we’re capable of abstract reasoning and symbolic manipulation in a way that LLMs will never be capable of, meaning we can interrogate the fundamental assumptions being made about how things are done, rather than parroting variations on what’s been seen before and assuming our training data is probably correct because that’s how it was done in the past. Their responses are generated based on patterns in the data they’ve been trained on, not from a process of logical deduction or understanding of a computational problem in the way a human or even a conventional program does. This means that while a LLM can produce code that looks correct, it may not actually function as intended when put into practice, because the model doesn’t truly “understand” the code it’s writing, it’s essentially making educated guesses based on the data it’s seen. While LLMs can replicate patterns and follow templates, they fall short when it comes to genuine innovation or creative problem-solving. The essence of programming often involves thinking outside the box, something that’s inherently difficult for a model that operates by mimicking existing boxes. Even more, programming at its core often involves understanding and manipulating complex systems in ways that are fundamentally abstract and symbolic. This level of abstraction and symbolic manipulation is something that LLMs, as they currently stand, are fundamentally incapable of achieving in a meaningful way.
If these programmer agents do become capable of reasoning and symbolicmanipulation, and if they can reason about large amounts of data, then we will be truly living in a different world. People with money and brains are actively working on these projects and there are financial and reputational incentives now motivating this work in a major way, so I absolutely expect advancements one day. How far that day is off, I dare not speculate on.
The Users Of Computer-Aided Programming Tools
One of the coolest features and biggest footguns about programming is that you can give a computer instructions that it will follow perfectly and without fail exactly as you specify them. I think it’s amazingly neat to have a robot that will do whatever you ask it, never get tired, never need oiling, can be shared and tinkered with, worked on in maximum comfort from anywhere. That’s partly what I love about programming, I enjoy bossing a machine around and imposing my will on it, and it almost never complains. But the problem anyone learns almost immediately when they start writing code is that computers will do exactly what you tell them to do without any idea of what you want them to do. When people communicate with each other there is a huge background of shared context, not to mention gestures, facial expressions, tones, and other verbal and non-verbal channels to help get the message across more accurately. ChatGPT does not seem to get the hint even when I get so frustrated I start swearing at it. Colleagues that work together on a shared task in the context of a larger organization have a shared understanding of purpose, risks, culture, legal environment, etc. that they are operating inside of. Even with all of this, human programmers still err constantly in translating things like business requirements into computer programs. A LLM with none of this out-of-band information will have a much harder time and make many more assumptions than a colleague performing the same task. The LLM may however be better suited for narrowly-defined, well-scoped tasks which are not doing anything new. I hope and believe LLMs will reduce drudgery, boilerplate, and wheel reinventing. But I wouldn’t count on them excelling at building anything new, partly because of how non-specialists will try to communicate with them.
In most professions a sort of jargon develops. Practitioners learn the special meanings of words in their fields, for example in medicine or law or baseball. In the world of software we love applying 10-dollar words like “polymorphism” or “atomicity” to justify our inflated paychecks, but there is another benefit to this jargon, which is it can help us describe common concepts and ideas more precisely. If you say to a coder to “add up all the stuff we sold yesterday”, you may or may not get the answer to the question you think you’re asking. If you say “sum the invoice totals for all transactions from 2024-04-01 at 00:00 UTC up to 2024-04-02 00:00 UTC for accounts in the USA” you are a lot more likely to get the answer you want and be more confident that you got a reliable number. Less precise instructions leave huge mists of ambiguity which programming computers will happily fill in with assumptions. This is where much of the value of specialists comes in, namely the facility in some dialect which enables a greater precision of expression and intent than the verbiage someone in the Sales or HR department will reliably deploy. In plenty of situations, say if you’re building a social media network for parakeets, maybe it’s okay. But when real money is on the line, or health and safety, or decisions with liability ramifications are introduced, I predict companies will still want to keep one or two specialists around to make sure they aren’t now playing a game of telephone with a coworker talking to a LLM on the other end and who knows what logic emerging out of the other end.
Introducing AI agents into your software development flow may create more problems than it solves, at least with what is likely to be around in the near term. On the terrific JS Party podcast they recently took a look at “Devin”, a brand new tool which claims the ability to go off by itself and complete tickets like a software engineer in your team might do. It received heaps of breathless press. But until these agents are actually reliable, other engineers still will have to debug the work done by the agent, which could end up wasting more time than is saved.
But the number they published, I think, was 13.86% of issues unresolved. So that’s about one in seven. So you pointed out a list of issues, and it can independently go and solve one in seven. And first off, to me, I’m like “That is not an independent software developer.” And furthermore, I find myself asking “If its success rate is one in seven, how do you know which one?” Are the other six those “It just got stuck”? Or has it submitted something broken? Because if it sets up something broken, that doesn’t actually solve the issue, not only do you have it only actually solving one in seven, but you’ve added load, because you have to go and debug and figure out which things are broken. So I think the marketing stance there is little over the top relative to what’s being delivered.
The software YouTuber Internet of Bugs went on to accuse the creators of Devin of misleading the public about its capabilities in a detailed takedown.
And in practice, a lot of code a LLM gives me is just wrong. A couple weeks ago I think I ended up trying to write a script for around four hours with ChatGPT when probably should have just looked up the relevant documentation myself. It kept going in circles and giving me code that just didn’t do what it said it did, even with me feeding it back output and error messages.
What’s The Future?
While there are many reasons for skepticism about AI-assisted programming, I am guardedly optimistic. I do get value out of the tools I use today which I believe will improve rapidly. I know there are very smart people out there working on them, assisted by computers making the tools even smarter, perhaps not unlike how computers started to be used to design better processors in a powerful feedback loop. I have limited expectations for LLMs but they are certainly not the only tool in the AI toolbox and there are vast amounts of money flowing into research and development, some of which will undoubtedly produce results. Computers will be able to drop some of the arbitrary strictness that made programming so tedious in the past and present (perhaps a smarter IDE will not bother you ever again about forgetting a ; or about an obviously mistyped variable name). I have high hopes for better static analysis tools or automated code reviews. Long-term I do believe how most people interact with computers will fundamentally change. AI agents will be trusted with more and more real-world tasks in the way that more and more vital societal functions have been allowed to be conducted over the internet. But someone will still have to create those agents and the systems they interact with and it won’t be only AI agents talking to themselves. At least I sure hope not.
So I’m not too concerned for my job security just yet. Software continues to eat the world and I’m not convinced the current state of the art can do the job of programmers without specialist intermediaries. As in the past, new development tools and paradigms will make programmers more productive and able to spend more time focusing on the problems that need solving rather than on mundane tasks. Maybe we will be able to let computers automate their automation of our lives but it will be on the less-mission-critical margins for quite some time.
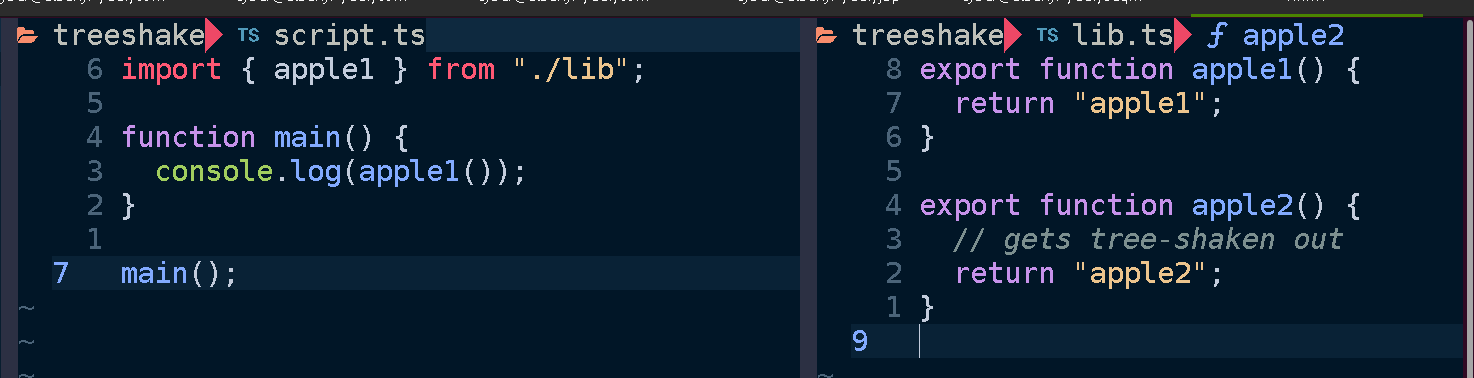
One fantastic feature of JavaScript (compared to say, Python) is that it is possible to bundle your code for packaging; removing everything that is not needed to run your code. We call this “tree-shaking” because the stuff you aren’t using falls out leaving the strongly-attached bits. This reduces the size of your output, whether it’s a NPM module, code to run in a browser, or a NodeJS application.
By way of illustration, suppose we have a script that imports a function from a library. Here it calls apple1() from lib.ts:
The main point here being that only apple1 is included in the bundled script. Since we didn’t use apple2 it gets shaken out like an overripe piece of fruit.
Motivation
There are many reasons this is a valuable feature, the main one is performance. Less code means less time spent parsing JavaScript when your code is executed. It means your web app loads faster, your docker image is smaller, your serverless function cold start time is reduced, your NPM module takes up less disk space.
A robust application architecture can be a serverless architecture where your application is composed of discrete functions. These functions can function like an API if you put an API gateway or GraphQL server that invokes the functions for different routes and queries, or can be triggered by messages in queues or files being uploaded to a bucket or as regularly scheduled events. In this setup each function is self-contained, only containing whatever code is needed for its specific functionality and no unrelated code. This is in contrast to a monolith or microservice where the entire application must be loaded up in order to handle a request. No matter how large your project gets, each function remains about the same size.
I build applications using Serverless Stack, which has a terrific developer experience focused on building serverless applications on AWS with TypeScript and CDK in a local development environment. Under the hood it uses esbuild. Let’s peek under the hood.
Mechanics
Conceptually tree-shaking is pretty straightforward; just throw away whatever code our application doesn’t use. However there are a great number of caveats and tricks needed to debug and finesse your bundling.
Tree-shaking is a feature provided by all modern JavaScript bundlers. These include tools like Webpack, Turbopack, esbuild, and rollup. If you ask them to produce a bundle they will do their best to remove unused code. But how do they know what is unused?
The fine details may vary from bundler to bundler and between targets but I’ll give an overview of salient properties and options to be aware of. I’ll use the example of using esbuild to produce node bundles for AWS Lambda but these concepts apply generally to anyone who wants to reduce their bundle size.
Measuring
Before trying to reduce your bundle size you need to look at what’s being bundled, how much space everything takes up, and why. There are a number of tools at our disposal which help visualize and trace the tree-shaking process.
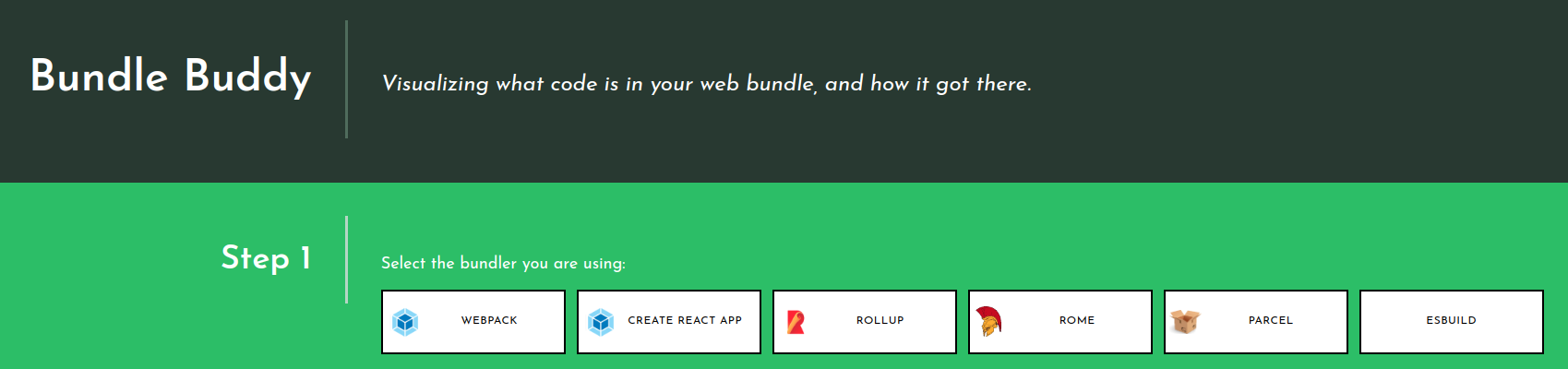
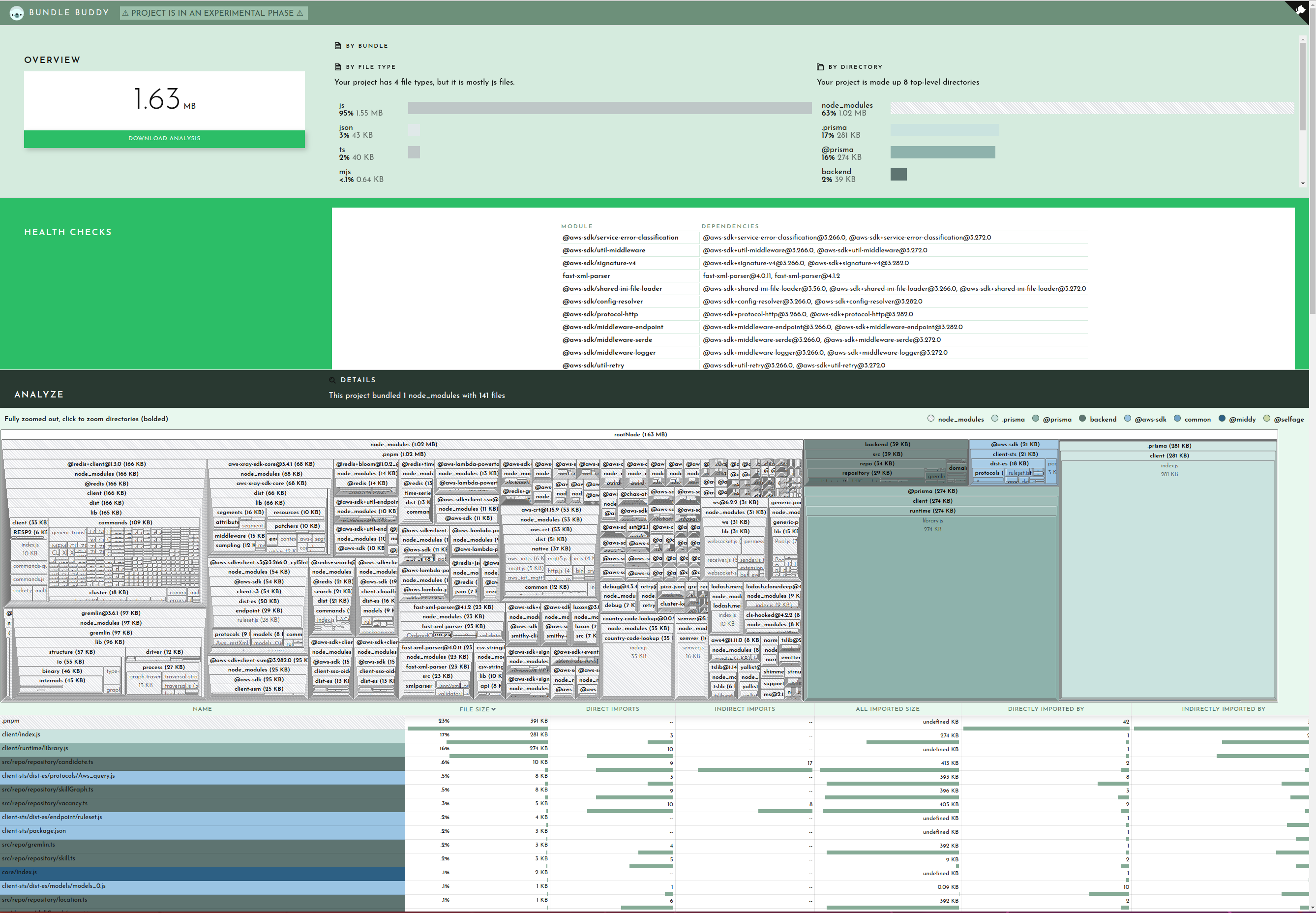
Bundle Buddy
This is one of the best tools for analyzing bundles visually and it has very rich information. You will need to ask your bundler to produce a meta-analysis of the bundling process and run Bundle Buddy on it (it’s all local browser based). It supports webpack, create-react-app, rollup, rome, parcel, and esbuild. For esbuild you specify the --metafile=meta.json option.
When you upload your metafile to Bundle Buddy you will be presented with a great deal of information. Let’s go through what some of it indicates.
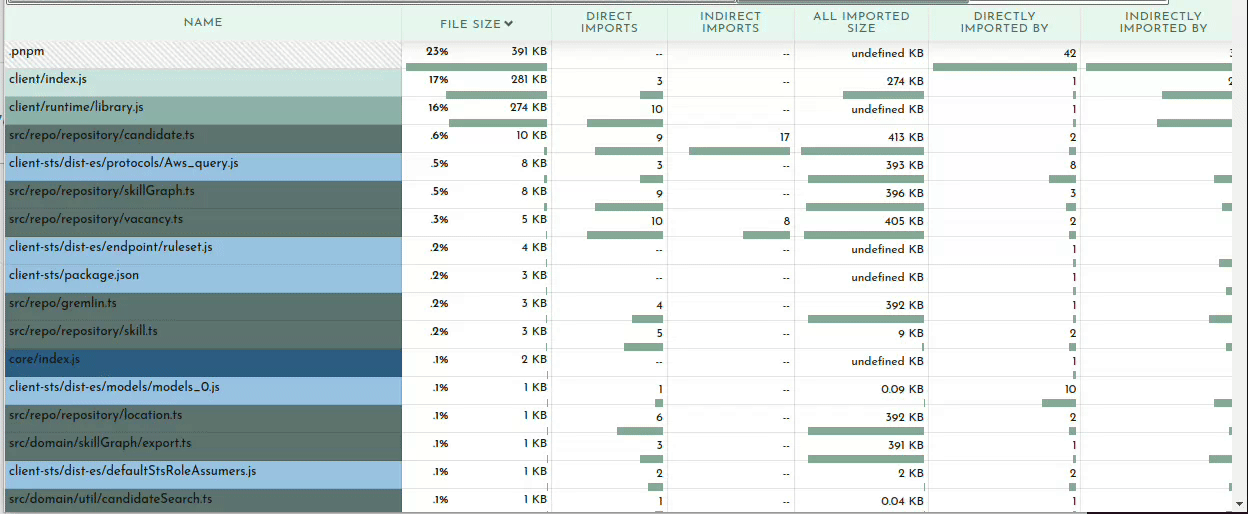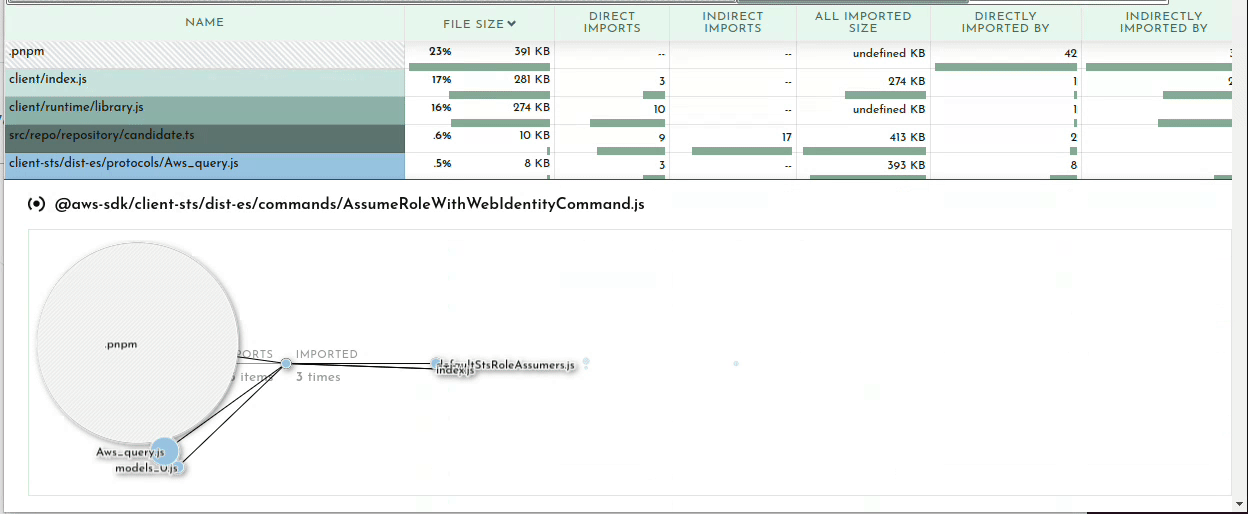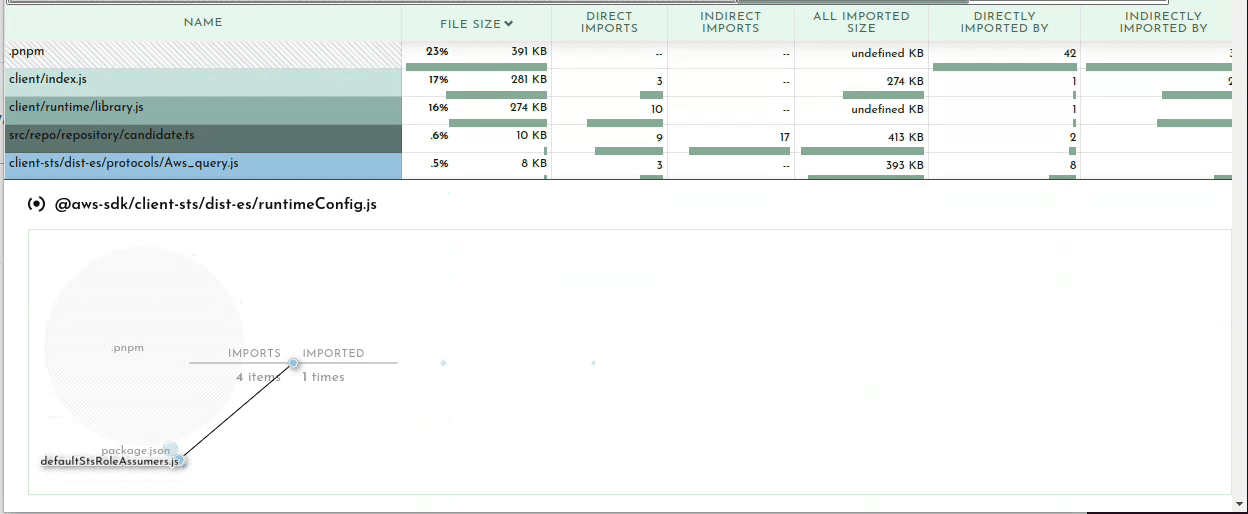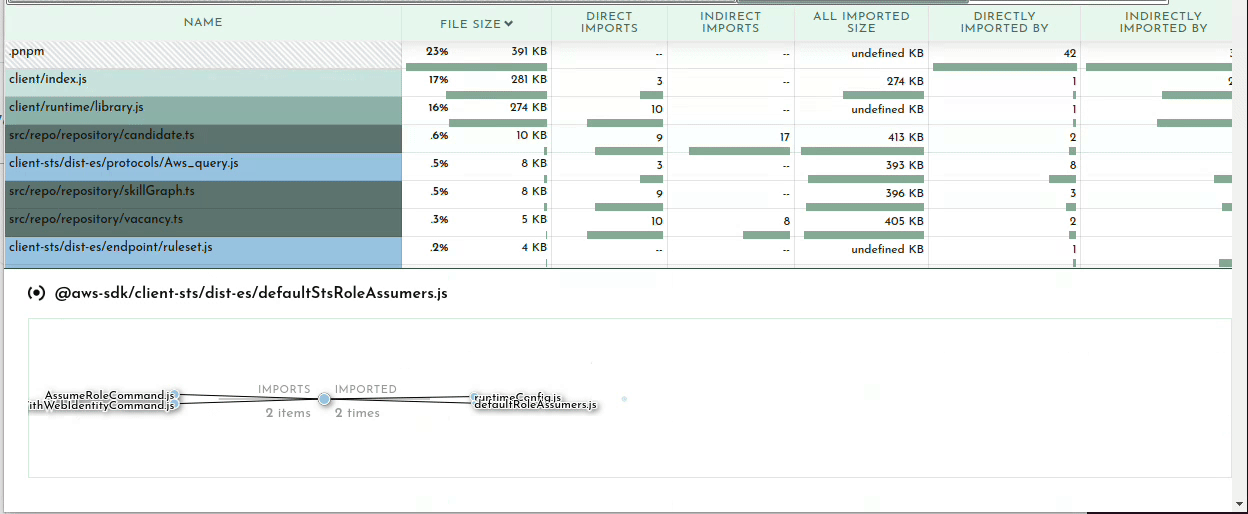
Bundle Buddy in action
Let’s start with the duplicate modules.
This section lets you know that you have multiple versions of the same package in your bundle. This can be due to your dependencies or your project depending on different versions of a package which cannot be resolved to use the same version for some reason.
Here you can see I have versions 3.266.0 and 3.272 of the AWS SDK and two versions of fast-xml-parser. and The best way to hunt down why different versions may be included is to simply ask your package manager. For example you can ask pnpm:
So if I want to shrink my bundle I need to figure out how to get it so that both @aws-sdk/client-* and @prisma/migrate can agree on a common version to share so that only one copy of fast-xml-parser needs to end up in my bundle. Since this function shouldn’t even be importing @prisma/migrate (and certainly not mongodb) I can use that as a starting point for tracking down an unneeded import which will discuss shortly. Alternatively you can open a PR for one of the dependencies to use a looser version spec (e.g. ^4.0.0) for fast-xml-parser or @aws-sdk/client-sts.
With duplicate modules out of the way, the main meat of the report is the bundled modules. This will usually be broken up into your code and stuff from node_modules:
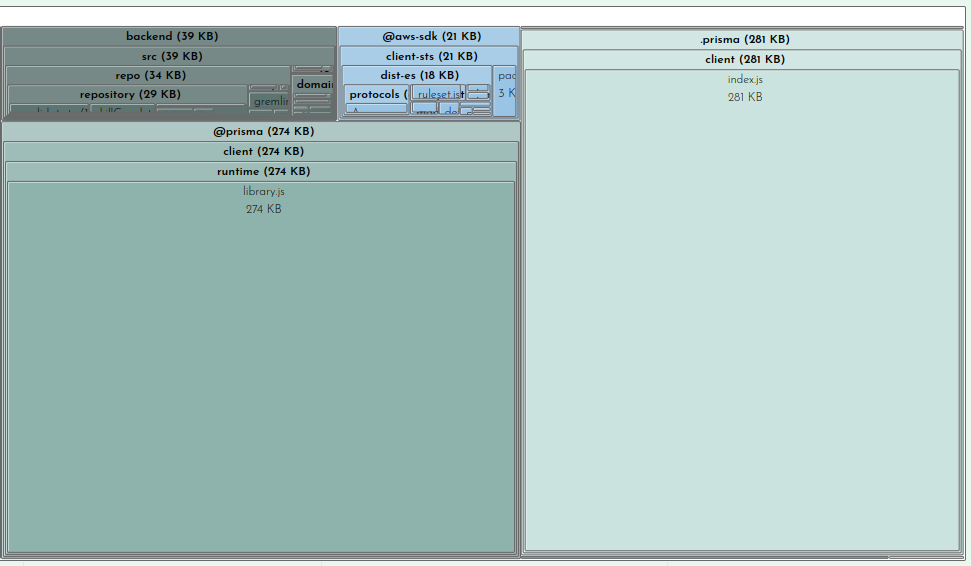
When viewing in Bundle Buddy you can click on any box to zoom in for a closer look. We can see that of the 1.63MB that comprises our bundle, 39K is for my actual function code:
This is interesting but not where we need to focus our efforts.
Clearly the prisma client and runtime are taking up sizable parcels of real-estate. There’s not much you can do about this besides file a ticket on GitHub (as I did here with much of this same information).
But looking at our node_modules we can see at a glance what is taking up the most space:
This is where you can survey what dependencies are not being tree-shaken out. You may have some intuitions about what belongs here, doesn’t belong here, or seems too large. For example in the case of my bundle the two biggest dependencies are on the left there, @redis-client (166KB) and gremlin 97KB). I do use redis as a caching layer for our Neptune graph database, of which gremlin is a client library that one uses to query the database. Because I know my application and this function I know that this function never needs to talk to the graph database so it doesn’t need gremlin. This is another starting point for me to trace why gremlin is being required. We’ll look at that later on when we get into tracing. Also noteworthy is that even though I only use one redis command, the code for handling all redis commands get bundled, adding a cost of 109KB to my bundle.
Finally the last section in the Bundle Buddy readout is a map of what files import other files. You can click in for what looks like a very interesting and useful graph but it seems to be a bit broken. No matter, we can see this same information presented more clearly by esbuild.
esbuild –analyze
Your bundler can also operate in a verbose mode where it tells you WHY certain modules are being included in your bundle. Once you’ve determined what is taking up the most space in your bundle or identified large modules that don’t belong, it may be obvious to you what the problem is and where and how to fix it. Oftentimes it may not be so clear why something is being included. In my example above of including gremlin, I needed to see what was requiring it.
We can ask our friend esbuild:
esbuild --bundle --analyze --analyze=verbose script.ts --outfile=tmp.js 2>&1 | less
The important bit here being the --analyze=verbose flag. This will print out all traces of all imports so the output gets rather large, hence piping it to less. It’s sorted by size so you can start at the top and see why your biggest imports are being included. A couple down from the top I can see what’s pulling in gremlin:
This is extremely useful information for tracking down exactly what in your code is telling the bundler to pull in this module. After a quick glance I realized my problem. The file repository/skill.ts contains a SkillRepository class which contains methods for loading a vacancy’s skills which is used by the vacancy repository which is eventually used by my function. Nothing in my function calls the SkillRepository methods which need gremlin, but it does include the SkillRepository class. What I foolishly assumed was that the methods on the class I don’t call will get tree-shaken out. This means that if you import a class, you will be bringing in all possible dependencies any method of that class brings in. Good to know!
This is a colorful but limited tool for showing you what’s being included in your NextJS build. You add it to your next.config.js file and when you do a build it will pop open tabs showing you what’s being bundled in your backend, frontend, and middleware chunks.
The amount of bullshit @apollo/client pulls in is extremely aggravating to me.
Modularize Imports
It was helpful for learning that using top-level Material-UI imports such as import { Button, Dialog } from "@mui/material" will pull in ALL of @mui/material into your bundle. Perhaps this is because NextJS still is stuck on CommonJS, although that is pure speculation on my part.
While you can fix this by assiduously doing import { Button } from "@mui/material/Button" everywhere this is hard to enforce and tedious. There is a NextJS config option to rewrite such imports:
Has a spiffy graph of imports and works with Webpack.
Tips and Tricks
CommonJS vs. ESM
One factor that can affect bundling is using CommonJS vs. EcmaScript Modules (ESM). If you’re not familiar with the difference, the TypeScript documentation has a nice summary and the NodeJS package docs are quite informative and comprehensive. But basically CommonJS is the “old, busted” way of defining modules in JavaScript and makes use of things like require() and module.exports, whereas ESM is the “cool, somewhat less busted” way to define modules and their contents using import and export keywords.
Tree-shaking with CommonJS is possible but it is more wooley due to the more procedural format of defining exports from a module whereas ESM exports are more declarative. The esbuild tool is specifically built around ESM, in the docs it says:
This way esbuild will only bundle the parts of your packages that you actually use, which can sometimes be a substantial size savings. Note that esbuild’s tree shaking implementation relies on the use of ECMAScript module import and export statements. It does not work with CommonJS modules. Many packages on npm include both formats and esbuild tries to pick the format that works with tree shaking by default. You can customize which format esbuild picks using the main fields and/or conditions options depending on the package.
So if you’re using esbuild, it won’t even bother trying unless you’re using ESM-style imports and exports in your code and your dependencies. If you’re still typing require then you are a bad person and this is a fitting punishment for you.
As the documentation highlights, there is a related option called mainFields which affects which version of a package esbuild resolves. There is a complicated system for defining exports in package.json which allows a module to contain multiple versions of itself depending on how it’s being used. It can have one entrypoint if it’s require‘d, a different one if imported, or another if used in a browser.
The upshot is that you may need to tell your bundler explicitly to prefer the ESM (“module“) version of a package instead of the fallback CommonJS version (“main“). With esbuild the option looks something like:
Setting this will ensure the ESM version is preferred, which may result in improved tree-shaking.
Minification
Tree-shaking and minification are related but distinct optimizations for reducing the size of your bundle. Tree-shaking eliminates dead code, whereas minification rewrites the result to be smaller, for example replacing a function identifier e.g. “frobnicateMajorBazball” with say “a1“.
Usually enabling minification is a simple option in your bundler. This bundle is 2.1MB minified, but 4.5MB without minification:
Sometimes you may want to import a module not because it has a symbol your code makes use of but because you want some side-effect to happen as a result of importing it. This may be an import that extends jest matchers, or initializes a library like google analytics, or some initialization that is performed when a file is imported.
Your bundler doesn’t always know what’s safe to remove. If you have:
import './lib/initializeMangoids'
In your source, what should your bundler do with it? Should it keep it or remove it in tree-shaking?
If you’re using Webpack (or terser) it will look for a sideEffects property in a module’s package.json to check if it’s safe to assume that simply importing a file does not do anything magical:
{
"name": "your-project",
"sideEffects": false
}
Code can also be annotated with /*#__PURE__ */ to inform the minifier that this code has no side effects and can be tree-shaken if not referred to by included code.
var Button$1 = /*#__PURE__*/ withAppProvider()(Button);
Not every package you depend on needs to necessarily be in your bundle. For example in the case of AWS lambda the AWS SDK is included in the runtime. This is a fairly hefty dependency so it can shave some major slices off your bundle if you leave it out. This is done with the external flag:
One thing worth noting here is that there are different versions of packages depending on your runtime language and version. Node 18 contains the AWS v3 SDK (--external:@aws-sdk/) whereas previous versions contain the v2 SDK (--external:aws-sdk). Such details may be hidden from you if using the NodejsFunction CDK construct or SST Function construct.
On the CDK slack it was recommended to me to always bundle the AWS SDK in your function because you may be developing against a different version than what is available in the runtime. Or you can pin your package.json to use the exact version in the runtime.
Another reason to use externals is if you are using a layer. You can tell your bundler that the dependency is already available in the layer so it’s not needed to bundle it. I use this for prisma and puppeteer.
Performance Impacts
For web pages the performance impacts are instantly noticeable with a smaller bundle size. Your page will load faster both over the network and in terms of script parsing and execution time.
Another way to get an idea of what your node bundle is actually doing at startup is to profile it. I really like the 0x tool which can run a node script and give you a flame graph of where CPU time is spent. This can be an informative visualization and let you dig into what is being called when your script runs:
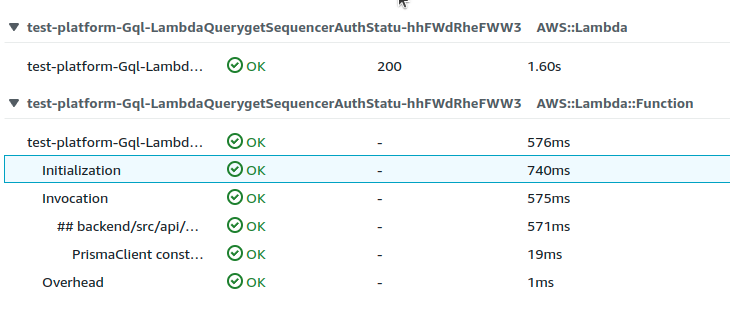
For serverless applications you can inspect the cold start (“initialization”) time for your function on your cloud platform. I use the AWS X-Ray tracing tool. Compare before and after some aggressive bundle size optimizations:
The cold-start time went from 2.74s to 1.60s. Not too bad.
If you’re using AWS CDK and Cognito, probably you want to have a test user account. I use one mainly for testing GraphQL queries and mutations in the AppSync console which requires you to provide a userpool username and password.
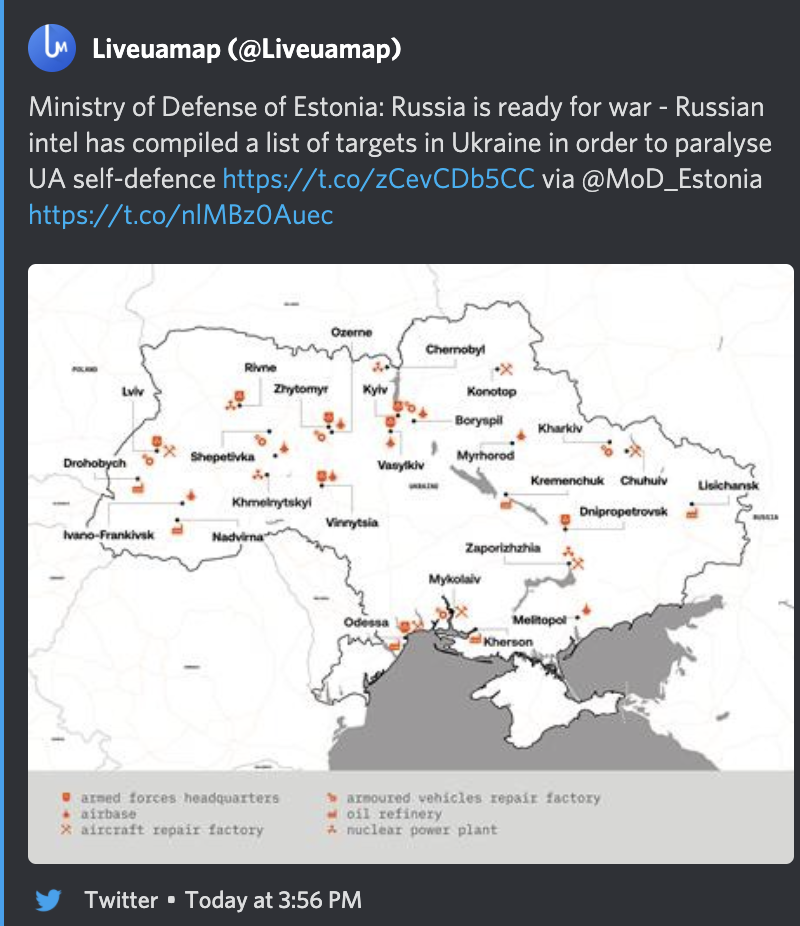
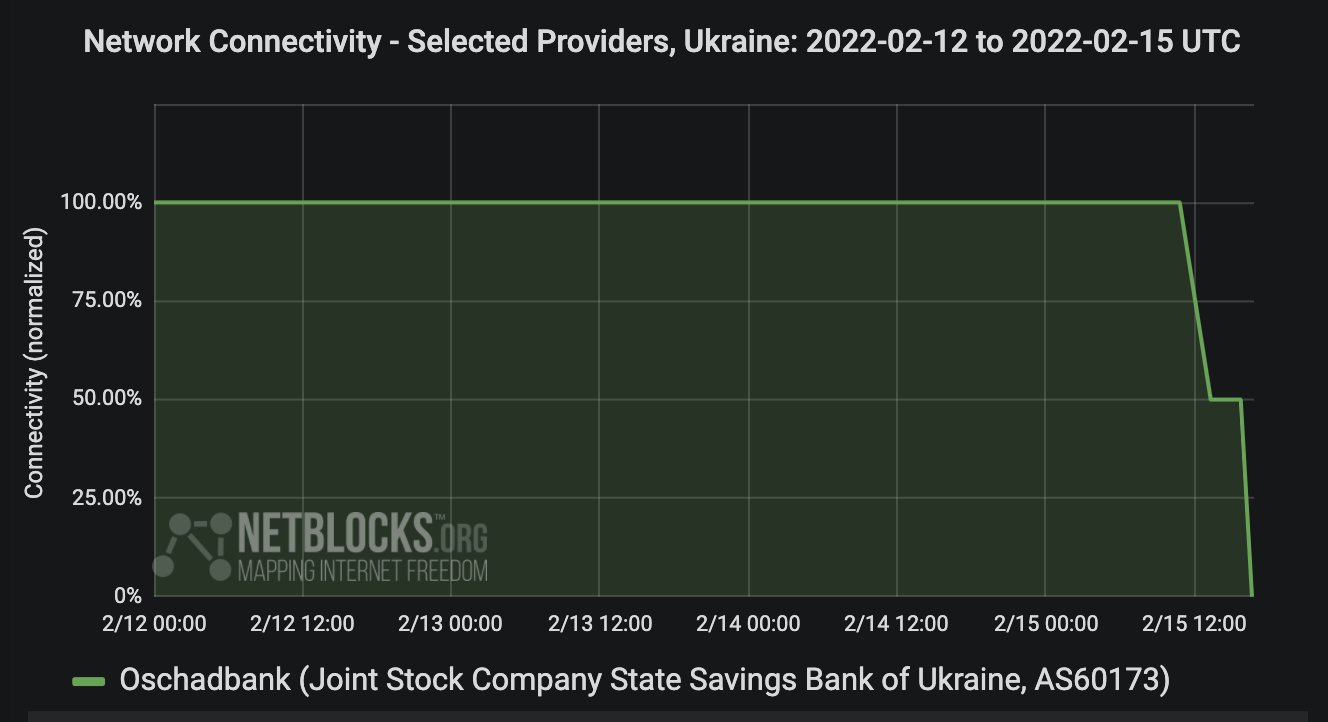
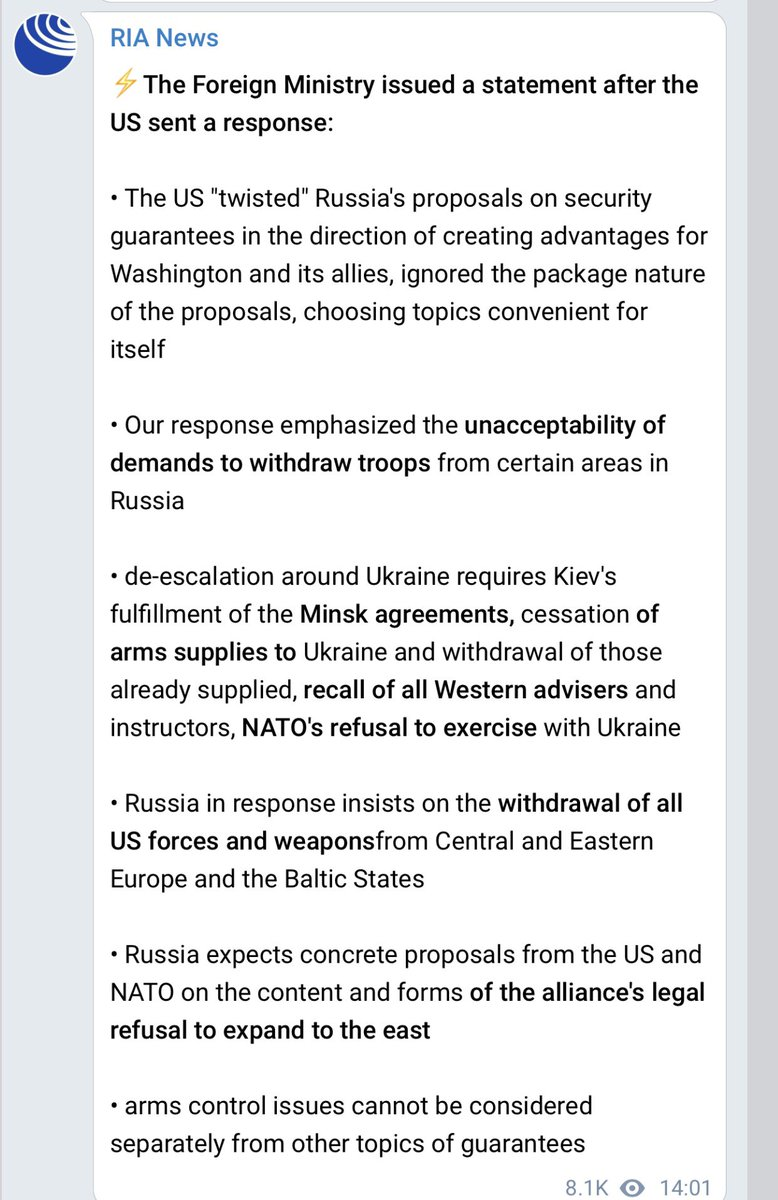
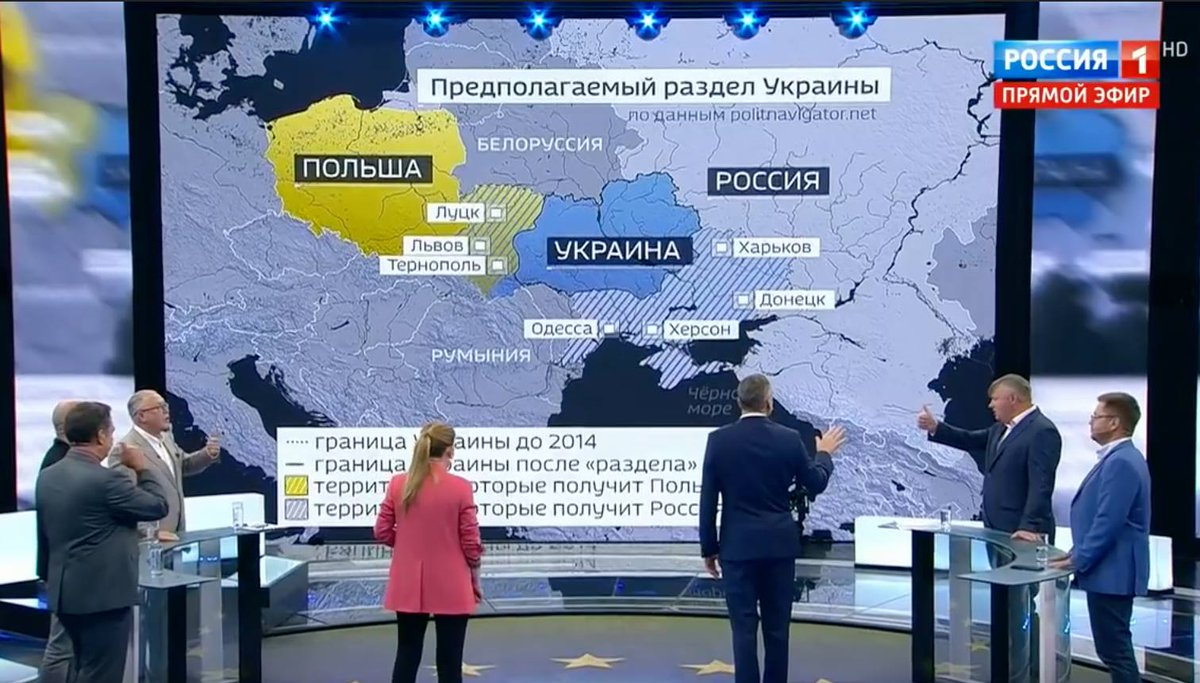
As a result of Russia’s invasion of Ukraine there have been a few lexical, orthographic, and semantic changes of note taking place in the Ukrainian language. They propagate alongside the flood of information, memes, and propaganda flowing over Ukrainian social media, primarily on telegram and Meta platforms. Some are more widespread than others, some may not last, but it’s curious to look at how war can change the perception of one’s neighbor in such a short period of time, with the language following along in changes in attitude.
To summarize information reported by the Ukrainian telegram channel “Gramota”:
Синонімічний ряд росія – московія тепер доповнили кацапстан, оркостан, мордор.
New synonyms for “russia”/”moscovia” (sic) are: “katsapstan”, “orcostan”, “mordor”. The latter synonyms are derived from the widespread Tolkeinian references to the invading army as a horde of orcs due to the poorly coordinated human wave attacks, slaughtering of civilians, and general disorder characteristic of the russian army. The army is also frequently referred to as “орда”, the Mongol horde which caused a great deal of destruction in the region in the past.
In addition the authors note the now somewhat commonplace writing of “russia”, “moscow”, “rf”, and “putin” in lowercase, even in some official media. (“Щоб продемонструвати свою зневагу, слова росія, москва, рф, путін ми стали писати з малої літери.”)
Not to be outdone, the Ukrainian Armed Forces suggested writing “russia” with an extra small “r” (“ₚосія”):
A new widely-used term to refer to russians of the putinist persuasion is “rashism” (рашизм) – a novel portmanteau of “russian” and “fascism”.
“The War in Ukraine Has Unleashed a New Word” – Timothy Snyder in New York Times Magazine
Змінили й правила граматики. Тепер принципово кажемо “на росії” у відповідь на їхнє “на Україні”.
This one is a little hard to explain but there are different prepositions that have been used to refer to being “in Ukraine” – during the Ukrainian SSR days when Ukraine was officially as a state inside the USSR the prefix “on” (на) was used with the locative or prepositional case with respect to Ukraine. After independence the appropriate prefix “in” (в) has been used to signify a distinct country instead of a region. Apparently some in russia still say “on Ukraine” to be disrespectful, so: “now we say ‘on russia’ in response to their ‘on Ukraine'”.
Нового значення з негативним забарвленням набуло дієслово спасати.
“A new meaning with a negative connotation was acquired by the verb ‘to save'”. As putin’s army came “to save” Ukraine from whatever it was supposedly saving them from, the word now has a sinister association.
Лягаючи спати, ми почали бажати спокійної ночі або тихої ночі. 🌙 Але тут ми не скалькували фразу “Спокойной ночи”. Це просто збіг. Ми вклали в неї свій зміст, переосмисливши значення спокою.
Going to bed, we began to wish each other a peaceful night or a quiet night. 🌙 But here we did not copy the (russian) phrase “Good night” (lit. “peaceful night”). It’s just a coincidence. We put our meaning into it, rethinking the meaning of peace.
Molotov cocktail recast as a Bandera smoothie (with a discussion on the gender of smoothie)
Three weeks of the unprovoked invasion of Ukraine by Russia has demonstrated the essential cruelty and homicidal nature of the Russian military and civilian leadership. Having discovered that their political goal of occupying the country and installing a puppet leader friendly to Moscow was going to be harder than anticipated, they have settled for wholesale slaughter of civilians with no particular goal other than that of terror and enlarging Russia’s territory.
As a genocide scholar I am an empiricist, I usually dismiss rhetoric. I also take genocide claims with a truckload of salt because activists apply it almost everywhere now.
Not now. There are actions, there is intent. It's as genocide as it gets. Pure, simple and for all to see
This is not the first or second time that the Muscovite government has attempted to erase the Ukrainian culture and people for the crime of being born on lands that Russia considers theirs to control. Much of the Russian-speaking populace of Eastern Ukraine are Russians that were moved into the region from Russia, while native Ukrainian families in the area were killed or forcibly relocated to Russia. This region with a higher density of Russian speakers is what Putin has used as a pretext to “protect” ethnic Russians from the violence in the region resulting from the Russian-backed separatists who revolted against the government in 2014. The banning of the Ukrainian culture in the Russian Empire and the deliberate death by starvation of millions of Ukrainians by Stalin were historical attempts at erasure still fresh in the Ukrainian cultural memory, along with recent injustices like Chernobyl and the annexation of Crimea and the Donbas, not to mention the twenty or so wars previously fought between Russia and Ukraine. Considering this it should have not been a surprise to the Kremlin when their invasion force was not welcomed with open arms as liberators.
Since the invasion failed to quickly occupy and control Kyiv, the parade uniforms brought with the soldiers were shelved and the standoff weaponry was hauled out as in previous Russian military campaigns against unwilling citizenry like in Syria and Chechnya. Due to their fear of entering hostile cities, the Russian military has been targeting critical civilian infrastructure for bombardment. Artillery, ballistic missiles, precision guided missiles, multiple-launch rocket systems, dumb bombs, smart bombs, and everything else that explodes has been lobbed into Ukrainian cities and towns that the Russian Horde comes upon. Hospitals, water treatment facilities, nuclear power plans, internet providers, mobile phone and TV towers, schools, government buildings of every sort, and residential buildings have all been targeted and blown to pieces.
This is a city on the Sea of #Azov and its name is Mariupol. It is named after the Virgin Mary, mother of Jesus Christ. 350 thousand residents of #Mariupol 18 days without water, food and electricity. Hundreds of air bombs hit the hero city. #Ukrainepic.twitter.com/FAl4vhfLks
Entire cities are now without electricity, internet, heat, or water. The strategy appears to be the same as in Aleppo and Grozny: murder and terrorize citizens until the city is no longer a point of resistance, due to surrender or complete razing, whichever comes first.
Bombed maternity hospital.
There are additional domains that the Kremlin is waging warn in: the cyber and information spaces. At the time of the invasion a new piece of malware was activated in Ukraine which was designed to permanently destroy all data stored on a computer. Not simply overwriting all files with garbage data but leveraging a signed disk driver to overwrite the master boot record and corrupting filesystem structures to make recovery impossible. A highly destructive and targeted attack launched right before the invasion.
Breaking. #ESETResearch discovered a new data wiper malware used in Ukraine today. ESET telemetry shows that it was installed on hundreds of machines in the country. This follows the DDoS attacks against several Ukrainian websites earlier today 1/n
And in a modus operandi that everyone should be familiar with now, the Russian government has been using every avenue of communication to get its false messages out regarding Ukraine. That the country is run by a “neo-Nazi junta” who seized power illegitimately, despite the free and fair democratic elections which elected a Jewish president.
When we say Kyiv is winning the information war, far too often we only mean information spaces we inhabit.
Pulling apart the most obvious RU info op to date (as we did using semantic modelling), very clear it is targeting BRICS, Africa, Asia. Not the West really at all. pic.twitter.com/GA5KUQo77S
Russia’s permanent representative to the United Nations Security Council called an emergency meeting to warn of the dangers posed by biological laboratories in Ukraine. In the meeting, Russia’s top UN ambassador claimed without evidence that Ukraine in conjunction with America was gathering DNA samples from Slavic peoples to create an avian delivery system for targeting Slavs with a biological weapon. I’m not making this up, you can watch the meeting yourself.
And in recent days Russian state media has been warning that Ukraine will use chemical weapons: “Ukrainian neo-Nazis are preparing provocations with the use of chemical substances to accuse Russia, the Ministry of Defense said.”
These are just a couple examples of a massive disinformation campaign coming out of the Kremlin. The claims are easily debunked. Ukraine is in compliance with biological safety inspections and only maintains facilities working with low-danger pathogens (BSL-1 and BSL-2) which are of no threat to anyone. Ukraine maintains no chemical or biological weapons research or weaponry, in contrast to Russia which operated the largest biological weapon program in world history and is infamous for using nerve agents to assassinate people in modern times, the only other country besides North Korea.
While the Russian government tries to convince the world of the aggressive and deadly nature of the Ukrainian threat, it is Russia that has invaded Ukraine and continues to deport and murder civilians and torture journalists in an effort to terrorize the country into submission. As of March 18th, the UN reported that about ten million civilians have fled their homes as a result of the war, with 6.5 million internally displaced and 3.2 million refugees fleeing to other countries. The UN High Commissioner for Human Rights recorded 1,900 civilian confirmed casualties in three weeks, with official Ukrainian estimates much higher.
In the House of Commons, MPs have unanimously adopted a motion to recognize that the Russian Federation is committing acts of genocide against the Ukrainian people. The motion was proposed by Heather McPherson, the NDP critic for foreign affairs.#cdnpolipic.twitter.com/z4WC44z9N5
In occupied Kherson, an illustrative example, it has been hard to get news out lately because the Russian military destroyed all means of telecommunications, confiscated cell phones, disabled the internet, and only allows citizens to watch Russian propaganda on TV. There are reports of Russian plans to stage a referendum in Kherson to annex the city by Russia, as was done in Crimea. The Crimean referendum only gave voters two choices: become an independent state or become part of Russia.
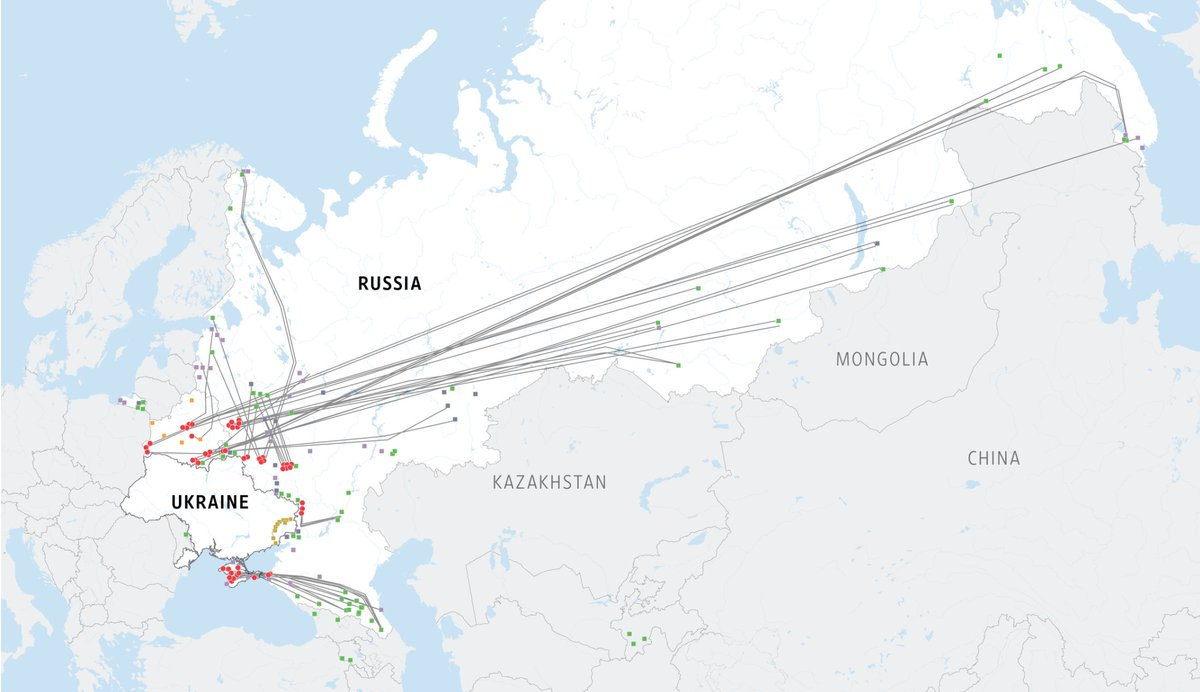
Many cities with millions of residents in Ukraine are being destroyed, as can be seen on this interactive map. Endless footage of civilian casualties can be seen on cell phone recordings taken on the ground by Ukrainians. The stories from cities under siege, like Mariupol, Kharkiv, Sumy, Mykolaiv, are the same. Indiscriminate bombardment of military and non-military targets alike, mostly the latter. Attacks on critical civilian infrastructure. Attempts to block electricity, internet access, food, water, and information from reaching the city. Rounding up and arresting Ukrainians critical of Russia.
The Russian plan appears to be to seize territory that it can, and erase territory that it cannot. The new political objective remains unclear.
Russia's deliberate destruction of Ukraine's food stores and grocery shops is painfully evident from @planet satellite imagery, with large grocery stores destroyed and deliberately targeted.
Last night, Russia struck the Retroville Mall near Kyiv, destroying most of it (including this smaller building but not only). At least four people died in this attack. pic.twitter.com/v7aIGMQmUQ
One of the silver linings of this terrible, unnecessary catastrophe is the fact that this ill-conceived invasion is the best documented in history. The dissemination of information about combat, forces, movements, official and unofficial statements, largely via Ukrainian telegram channels, is swift and unprecedented. Countries use their official twitter accounts to troll and mock belligerents. Soldiers and civilians on the ground post videos of them dressing down Russian conscript teenagers and borrowing occupying army hardware.
Huge caveat: the vast majority of what I see is from pro-Ukraine Telegram/Discord/Twitter, it’s only a few days into a massive operation, with major fog of war. This is absolutely not an accurate or complete picture of the war. But it is a darkly amusing one.
Here are a few choice quotes from professional analysts, military, and war nerds:
wait, how did you listen in to russian radio comms lol. Aren’t they supposed to be encrypted, not to mention off the internet..? Right?
It almost looked more as if they were trying to get as far they could down a road until they encountered a road block and were completely unworried about all the amazing angles people with cameras (which could just as easily be rifles) had on them. I’m kinda confused about wtf the idea behind that was too, maybe its just how things worked in syria…?
There are so many videos of russian troops within the cities in light armour and on foot its crazy. I havent seen this much yet. Could it be a sign that shelling is slowing down and they are entering next stage of their plan?
Its absolutely one of the most ill-executed military operations I have ever seen, they’ll use this war in military textbooks for generations to come as an instance of what not to do in strategic/tactical planning and execution.
What’s amazing is that this is fractally stupid – no matter what level you analyze the operation, from tactical to grand strategic, it’s mind-bogglingly stupid.
They’re definitely getting chewed if they enter actual urban combat. What the hell is this formation, military analysts are going to really be scratching their heads what is up with the military and it’s organisation.
Im listening to their comms, very chaotic. They get confused between each others. Also it seems that they are trying to fight ww2 style. Driving in between houses like some peasant with no radio to report while its 2022 and everyone is connected getting intel almost quicker then their radios and coordinating UA forces. And as someone said above their mistake make us think there hould be a logical yet bizarre explanation like “its a plan to outs putin and so on” but i think its their military doctrine not suited for 2022 I do not understand why they are running radios and maps instead of google maps or a chinese knock off. Like it is not like the americans aren’t watching you via satelite
Wow, rare video of the moment of engagement. They’re driving / walking right into ambushes across the city. What, are they trying to lose at this point? Literally feels like they have no control or awareness of the situation. What’s going on. They’re standing there to get shot… They are not very ready for urban fighting judging by that video.
https://twitter.com/RALee85/status/1497809352979361798 Does look like a recon group, not sure why a fuel tanker is driving with them though. That’s a city they’ve bypassed. They need fuel further up the line? That strikes me as a very… aggressive manuver to solve that problem. I have never seen a freaking patrol have a fueler attached Yeah, doesn’t seem like a patrol. I’m so confused honestly. Not sure why they seemed like they were stopping in a couple of different locations as well? An attempt at refueling that just got lost and accidentally drove straight through lines???
“We’re out of gas.”? The logistical problems are bad enough that they’ve… demechanized?
Let’s get into the best Ukrainian and NATO memes four days into this thing.
Latest from Telegram channels: In Ukraine, some local gopniks managed to find a lone Russian APC with the crew, so they beat them up, took the APC and the Russians and gave them to the Ukrainian army. That's one good Cheeki-Breeki right there. pic.twitter.com/2qoZY36hdX
Oh my… an Ukrainian villager again decided to bring back home an abandoned Russian military hardware but this time a 9K33 OSA surface-to-air missile system by tying it to his tractor. pic.twitter.com/9EeR1PA6V2
New (to me) dimension of crowdwork platforms: Russian military uses Premise microtasking platform to aim and calibrate fire during their invasion of Ukraine. Example tasks are to locate ports, medical facilities, bridges, explosion craters. Paying ¢0.25 to $3.25 a task. pic.twitter.com/kHTO2tSCUH
For some strange reason Russia offered to host negotiations at Gomel, in Belarus. Belarus is a belligerent in this war against Ukraine so it was an odd choice of location. Russian negotiating team was left to negotiate with themselves.
Zelensky press-secretary: we are aware that Russian delegation arrived in Homiel, we've indeed discussed talks there, but then Russia issued ultimatum that Ukrainian military should lay down the weapons, so there will be no Ukrainian delegation there https://t.co/WrlFGYBJTv
Zelensky is the number one target for the entire Russian military, spetznaz,FSB, GRU, Rosgvardia all out trying to get his ass, and he’s still making videos on the streets of Kyiv saying they are all here and not going anywhere. Imagine any American politician doing this. https://t.co/0j5fzovsWL
The sign is an obvious photoshop but one actually posted by the interior ministry to make the point.
!!! Ukraine's Interior ministry asked residents to take down street signs in order to confuse oncoming Russian troops. The state road-signs agency went one step further. (Roughly: all directions are to "go fuck yourselves") pic.twitter.com/8xVjceqRfx
Electronic roadsigns on the road from Boryspil airport – “russian ship – fuck off.”
Electrocar chargers in Moscow/St. Petersburg not working – "how can this be?" Reading "Glory to Ukraine"… "glory to heros"… "Putin fuck off"… "death to … er whatnow?" (Ukrainian word – "enemies") pic.twitter.com/8o4Pcl60wD
Putin reportedly has a $97 million luxury yacht called "Graceful". A group of Anonymous hackers on Saturday figured out a way to mess with maritime traffic data & made it look like the yacht had crashed into Ukraine's Snake Island, then changed its destination to "hell": pic.twitter.com/Ch53lcG7D6
A snapshot of the Russian economy: an investment expert goes live on air and says his current career trajectory is to work as "Santa Claus" and then drinks to the death of the stock market. With subtitles. pic.twitter.com/XiPVTSUuks
Some trolling from Ukraine: Head of Anti-corruption agency of Ukraine sent a letter to Russian defense minister Shoigu thanking him for embezzlement of Russian army pic.twitter.com/nIGQtSYnGz
Unlike many in the media and in the chattering classes, I have an acute need to keep up accurately with the “situation” going on between Russia and Ukraine, as my home is in Ukraine. I need to know if it’s safe to stay there or not, so I have been following developments closely. By which I do not mean watching CNN or spending much time reading the mainstream press, I mean following the events on the ground alongside statements, press, and propaganda from Russia, NATO members, the so-called DNR/LNR, Belarus (the most comical), Ukraine, and other interested parties. I’m able to do this thanks to a terrific OSINT discord in which there are of course randos like myself but also experienced intelligence analysts, military personnel, journalists, and people on the ground all around the region. Looking at satellite imagery, Tiktoks (there are dozens of videos posted every day in Russia and Belarus of troop and hardware movements), flights, news reports, press statements, diplomatic evacuations, and more.
So what’s going on? The TL;DR is that the situation is dangerous and the tension has only been building with no sign of de-escalation. While the media and politicians in the West have apparently been going bugfuck non-stop, some have suggested to distract from domestic issues, there are extremely valid reasons to be concerned that something up to and including a military invasion will happen. Many hybrid war elements including large-scale cyberattacks and misleading news have been ongoing and directed at Ukraine in recent days. Whether or not a full-scale military invasion will happen is only known by Putin at this point, but the alarm bells are being rung for good reasons.
Let me attempt to summarize why, starting with some publicly available military movements first:
While Russia and Belarus have announced the military exercises taking place, these exercises only represent a very small fraction of the forces that have been deployed. The forces deployed are mostly not in the regions the exercises have taken place, the scale of the build-up vastly exceeds the scope of the exercises.
The Russian Federation Baltic fleet has moved amphibious landing ships and submarines to the Black Sea, which was not scheduled.
Great numbers of units from the Eastern and Southern Military Districts have been relocated to the border.
Approximately 60% of Russia’s vast combined arms have moved to the Ukrainian border. The current estimates range from 140,000 troops to 180,000 troops split into 83 battalion tactical groups.
The U.S. intelligence community upgraded its warnings because of significant quantities of blood being moved to the field, where it has a shelf life of about three weeks. A precious resource, especially during covid, not normally used in exercises.
A large number of military hospital tents have been set up. Maybe for exercises but unlikely.
Recently Russian tanks have begun moving under their own power towards the border on city streets, tearing them up. Typically one does not destroy one’s own infrastructure during exercises.
Russia’s national guard Rosgvardia has been seen moving to the border. They would be expected to follow an incursion and secure newly-controlled territory.
Ramzan Kadyrov’s personal troops (“Sever” company) have been seen moving from Chechnya to the border. I would not want to meet them under any circumstances. Troops have been filmed boarding trains in Dagestan.
A massive array of S-300s, S-400s, with transloaders and missiles have amassed at the border with enough range to guarantee complete air supremacy.
A complement of Iskander ballistic systems accompany the troops. These would be used in any initial attack to neutralize airfields and for SEAD.
The 1st Guard Tanks Army has been forward deployed to Voronezh, on the border. These are the most elite ground troops Russia has, earmarked for general staff, and would comprise the tip of the spear of any invasion.
Russian troops and hardware is not only in training grounds but have been moved to forward operating bases, and actively deployed in the field. Given the snow, mud, and shitty conditions, it’s very unlikely that this posture can be kept up indefinitely.
Russia has stated that troops are moving away from the border and returning to bases after the completion of exercises. This is demonstrably false, as they have moved closer to the border and at least 7,000 additional troops have appeared in the last couple of days.
In the last couple days there has been a significant increase in artillery fire in the Donbass, reportedly mostly coming from the Russian side, likely attempting to provoke a reaction that can be used as a pretext for invasion.
In short, all of these elements do not necessarily mean there will be an invasion of Ukraine in the near term, but if one was about to take place this is precisely what one would expect to see preceding a large-scale invasion. If it’s a ruse it’s an extremely convincing one.
But the military posture is not the only cause for concern. The buildup of troops and hardware is one precondition, but it would be expected to be preceded by hybrid information war and cyber attacks. These have been dramatically scaled up since the 15th of February:
Multiple banks were taken offline at the same time. I was unable to log into my bank because the authentication server was offline.
The ministries of the interior and defense and the president’s website were taken offline. The A record for mil.gov.ua vanished and was unresolvable by CloudFlare.
The gov.ua DNS service sustained a 60GBps+ DDoS attack.
Many Ukrainians were sent SMS messages advising them to withdraw money from ATMs as soon as possible.
Russian news has been pumping out false or greatly exaggerated stories of mass graves, Nazi death squads, active genocides, and preparations for invasion of Donbass by Ukrainians. Any and every possible pretext for a Russian invasion has been floated in the media by official sources, LNR/DNR media, Belarussian sources.
In addition, in the past couple months:
The main general-purpose citizen mobile app (Дія) which is used for tax records, ID, Covid certification and other functions was hacked and the personal records of most Ukrainian citizens and residents was posted for sale on the darkweb.
Car insurance records on finances and addresses of many Ukrainians were stolen.
Around a terabyte of emails and documents from various ministries was reportedly stolen and published.
These are just a few selected observations out of many that I’ve seen go by. This is all based on open-source intelligence. The most urgent warnings have been coming from the U.S., U.K., Canada, and Australia. This is notable because they are four of the five eyes, countries with access to the most advanced and exceptional signals intelligence. More recently, Israel has been loudly sounding the alarm and increasing El Al flights trying to evacuate Israelis from Ukraine. Many have pointed out that when Israel is concerned, it’s worth taking notice.
People in the media with less, let’s say, granular accounts, have been quoting unnamed intelligence officials about specific dates and times of an invasion. I would not put too much stock in such reports because such reports are often of a more propagandistic nature. But I would very much look at the facts on the ground in conjunction with more official warnings. These official warnings have not predicted a specific date of invasion, only about the date upon which an invasion would be completely ready to go. It’s reasonable to be skeptical of these reports, but I believe they are not just pure fabrication or without basis in intelligence, publicly available or otherwise. There is a hypothetical argument to be made that by the leaking of intercepts and intelligence assessments, the U.S. has caused Putin to reconsider plans for invasion. This is a possibility, one of many, but one we cannot know today. Maybe in 15 or 20 years we’ll be able to look back and see what really happened in these times and know. Perhaps it is all merely military exercises, perhaps it is a move to permanently station Russian forces in Belarus, perhaps it was an attempt at diplomacy that failed(?), perhaps it was to intimidate Ukraine into accepting the Minsk agreements. It is clear that these maneuvers were many months or years in planning, executed at great expense, and not merely ordinary troop movements. There was a deliberate effort here to achieve something, opaque as that something may be at this moment.
What could the goal of these efforts be? Some say it is a bluff by Putin, to secure concessions from NATO and the U.S. by scaring everyone into thinking they will launch an attack on Ukraine in case their demands are not met. It’s no secret that the Russian Federation feels existentially concerned about the expansion of NATO, an explicitly anti-Russian alliance. They feel that the U.S.’s claims of upholding a rules-based international order and the sanctity of internationally recognized borders are laughably false. Sadly it must be admitted that they have a point. From the NATO bombing of Serbia and recognition of Kosovo, to the illegal wars of aggression in Iraq and Afghanistan, and more recently the covert and overt military interventions in places like Libya and Syria by the U.S. obviously run counter to the stated values and norms that are supposed to be so inviolable and non-negotiable. As an American I truly wish my government had more credibility and moral high ground here. Anyone who doesn’t have amnesia can see how hypocritical much of the moral posturing is, and Russia will play this up to the greatest extent possible.
However I am skeptical that this massive, expensive, extraordinary military buildup and active hybrid warfare aimed at Ukraine is purely about securing agreement from the U.S. and NATO. This is because their demands, given in writing, were clearly impossible to meet and Putin doubtlessly knew this. There is zero reason to believe Russia seriously expected NATO to kick out all of the members who joined since 1997. They also know that Ukraine is not going to be joining NATO anytime soon because of the active conflict in Donbass, among other reasons. The negotiations have been an obvious farce, so what would be the point of a bluff? If it is a bluff of an imminent attack, it certainly may be the most elaborate and convincing in all of modern history. No one hopes more than me that an invasion will not take place, and I think it unlikely that bombs will start falling on Kyiv, but I need to assess the situation rationally. Even if the risk is small, is it worth staying in Ukraine right now as all this is happening? Would you?
As to why former USSR countries desperately want to be a part of NATO, this is left as an exercise for the reader. In my personal opinion the only peaceful and lasting solution to this larger conflict would be for NATO to offer a path to Russia to join, with preconditions on a more democratic political system. This would take all of the wind out of Putin’s sails, prove that NATO is not purely an anti-Russia military alliance, and provide an avenue for political pressure to push the country in a positive direction as offering NATO and EU membership to other countries has done.
On at least one point, Russia has been consistent and persistent: that Ukraine must implement the Minsk agreements, which were signed as a ceasefire in 2015, under extreme duress. Russia’s interpretation of the agreements would effectively give Russian-backed separatists in the Donbass seats in parliament and political control and vetos on Ukraine’s foreign policy. Such an agreement, essentially signed at the time with a gun to their heads, is unimplementable in Kyiv today. Any government implementing Russia’s interpretation would be gone within a week, probably violently. Too many Ukrainians have fought and died to give power of their country over to Russia. Russia knows this and continues to push for it because they can say they are just trying to address the situation diplomatically. It is dreadfully cynical.
Another relevant agreement which Russia is not quick to bring up is the Budapest Memorandum, which was an agreement signed in 1994 by the U.S., U.K., Russia, Ukraine and others guaranteeing freedom from aggression and violations of borders in exchange for Ukraine giving up its nuclear weapons. To quote Wikipedia:
On 4 March 2014, the Russian president Vladimir Putin replied to a question on the violation of the Budapest Memorandum, describing the current Ukrainian situation as a revolution: “a new state arises, but with this state and in respect to this state, we have not signed any obligatory documents.” Russia stated that it had never been under obligation to “force any part of Ukraine’s civilian population to stay in Ukraine against its will.” Russia tried to suggest that the US was in violation of the Budapest Memorandum and described the Euromaidan as a US-instigated coup.
At the UN Security Council meeting in January on the Russian military buildup, the Russian ambassador blasted a shotgun of non-sequiturs ranging from Colin Powell’s evidence of WMDs in Iraq, the “CIA-backed color revolution installing Nazis in power” in the Maidan revolution (please don’t let me catch you repeating this profoundly inaccurate propaganda, even if you heard it repeated on your lefty podcasts), and “Ukrainian aggression” against Russian-speaking peoples. Following this verbal assault he regretfully excused himself because of an unmovable prior commitment, as the Ukrainian ambassador was about to begin his remarks. Since this, Russian ministers have been asserting the need to intervene in the event of attacks on Russian speakers in Ukraine in the event of genocide, this propaganda being pushed by state news agencies such as RIA Novosti in the past few days. The false narratives being constantly put out by state-owned media in Russia about the atrocities being committed in Ukraine have been reaching a fever pitch. If you think the media in the West is hysterical, you should see what they’re saying on Russian TV.
How to invade and split up Ukraine, on Russia 1.
Some say that Russia has done considerable damage against Ukraine without an invasion, and this is indeed true. The economic and human costs since 2014 but particularly in recent weeks has been enormous. Over 14,000 lives have been lost in the conflict, many flights over Ukrainian airspace have been canceled because insurance companies refuse to insure flights to and over Ukraine, remembering the MH-17 tragedy early in the war when a civilian airline was shot down with Russian weaponry. Billions of dollars in economic damage is being done to the Ukrainian economy, tourism is basically canceled.
Foreign ministries from the U.S., U.K., Australia, Sweden, Finland, Israel, Germany, Italy, UAE, Kuwait, Japan, Lithuania, and many other countries have told their citizens to leave immediately in no uncertain terms.
The U.S. embassy in Kyiv has been deactivated, the computers destroyed, and the staff evacuated to Lviv or outside the country. The Russian embassy was seen burning something today, most of its members evacuated as well. Some extremely VIP personnel were seen driving in black SUVs to the Polish border, running to a black hawk helicopter with a medevac callsign, and then quickly whisked away.
Difficult to understand how heavy the fighting has been in eastern Ukraine today until you compare it to the rest of the year so far.
The Ukrainian MoD reported more ceasefire violations today than they did for all of January. pic.twitter.com/JBVOobNcX9
The people who have it the worst are the poor residents of the Donbass. This morning a pre-school was shelled, with three staff injured. Ukraine isn’t even the real concern of Russia, NATO is. But here we are, caught in the middle as usual. Ukrainians don’t want to be pawns in some madman’s game, just to live in peace.