Click here to read the Russian version of this article.

I started studying the Russian language in university for a short time, then picked up formally studying it again since living and spending a lot of time in Eastern Europe. I love languages and find them super fascinating, especially syntax and orthography. For whatever reason these things are greatly interesting to me and fun to learn about. Like all nice theoretical studies, actual practical applications and reality dampen the fun somewhat.
To study practical everyday Russian is to study exceptions and unnecessary complexity. The language it most resembles for me is Latin both grammatically and in terms of the extra work you have to do that just seems somehow extra or not adding much.
When a student begins to study the Russian language, the first word they encounter as in every other language study is “hello!” In Russian this word is “Здравствуйте!” (Zdrastvuyte!) Which is five or six syllables depending how you count that preliminary imposing consonant cluster with a rolled “R”. The student immediately gets the sense that this isn’t going to be so easy. A first impression is that some key vowels seem to be missing from most words. How does one say “zdr”? From here it goes downhill.
When you want to say you are going somewhere in Russian it’s not enough to express the concept of travel, but it’s almost required to be accompanied by information about the mode of travel. There are words for specifying walking, going by means of wheeled conveyance, sailing, flying. Unlike many other languages, not only should the mode be specified but each verb consists of a unidirectional/multidirectional pair that must be discriminated (“I went to the store on foot end of story” vs “I went on foot to the store and then somewhere else”) as well as an imperfective/perfective pair that forces the speaker to consider if the action was completed or ongoing (“I walked” vs “I was walking”). On top of having to pick the right verb for the transport modality/perfective aspect/directionality combination one also should often prefix the verb to indicate if the motion is into, around, out of, on top of, under, through, out from, up to but not inside, and so on.
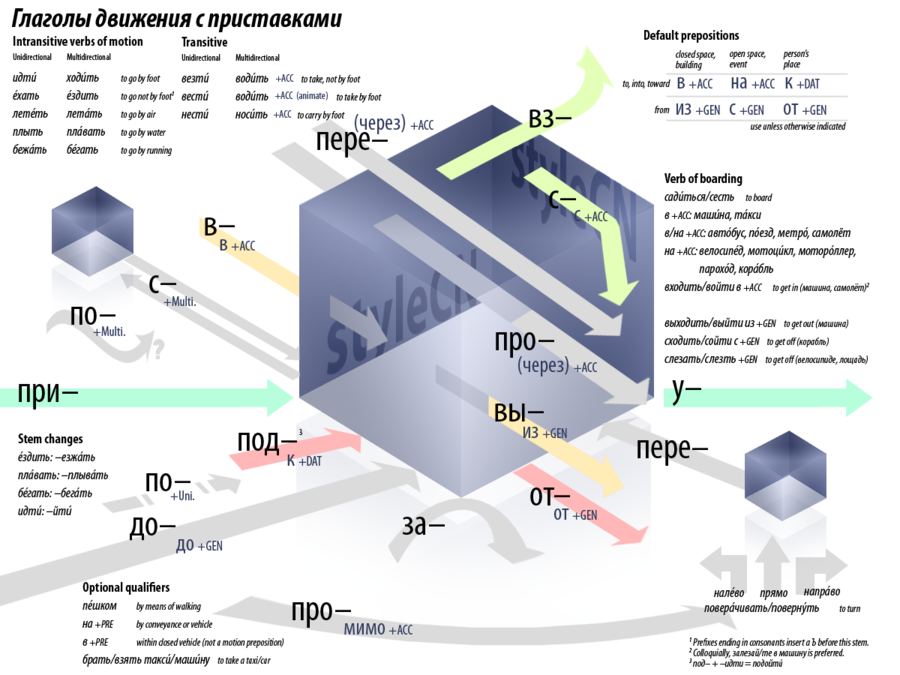
Along with learning the verbs of motion another fundamental aspect of the language is the noun inflection system. There are three genders, two numbers, and six main cases. Being an Indo-European language this system roughly similar to Latin, German, Old English and lots of other languages in this family.
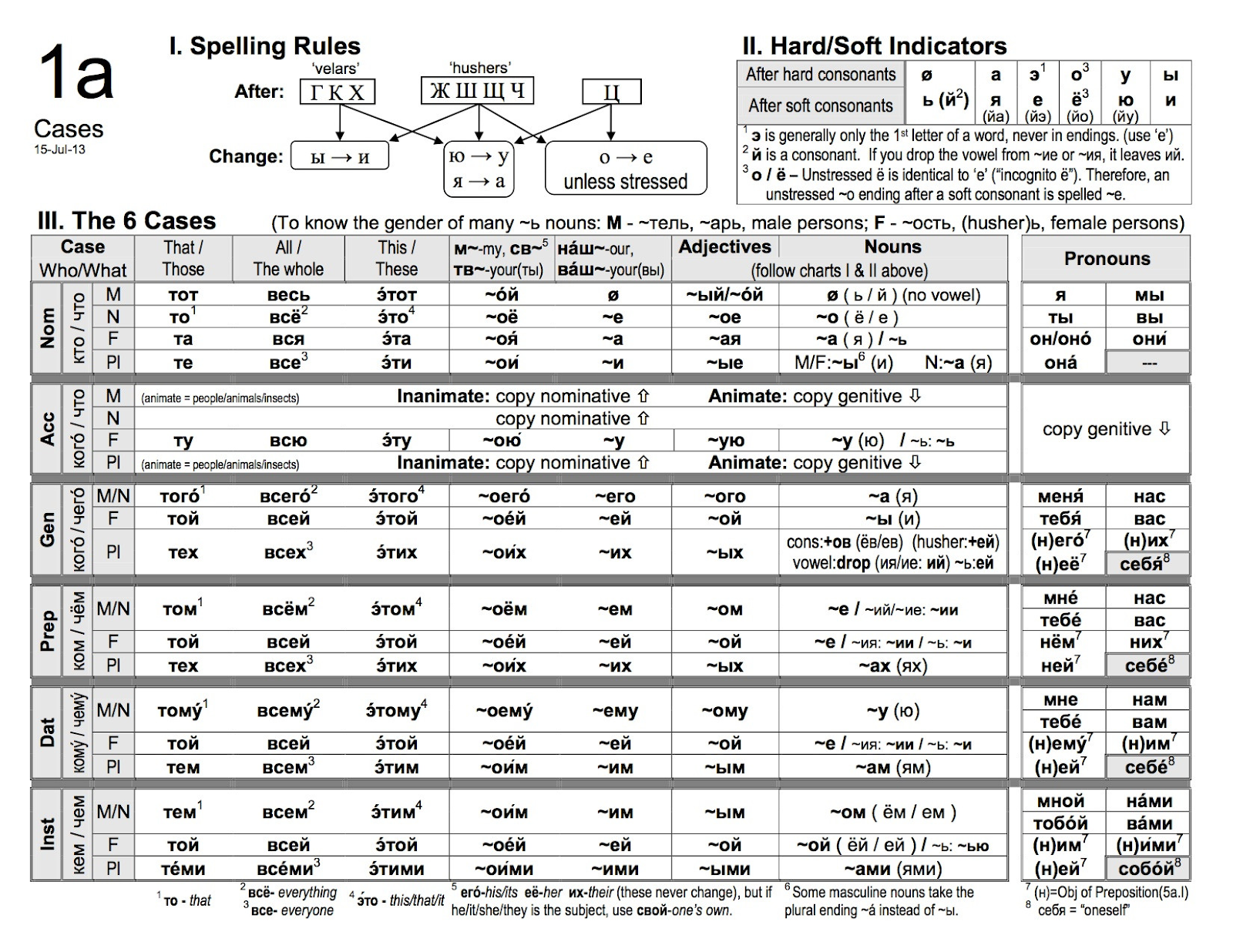
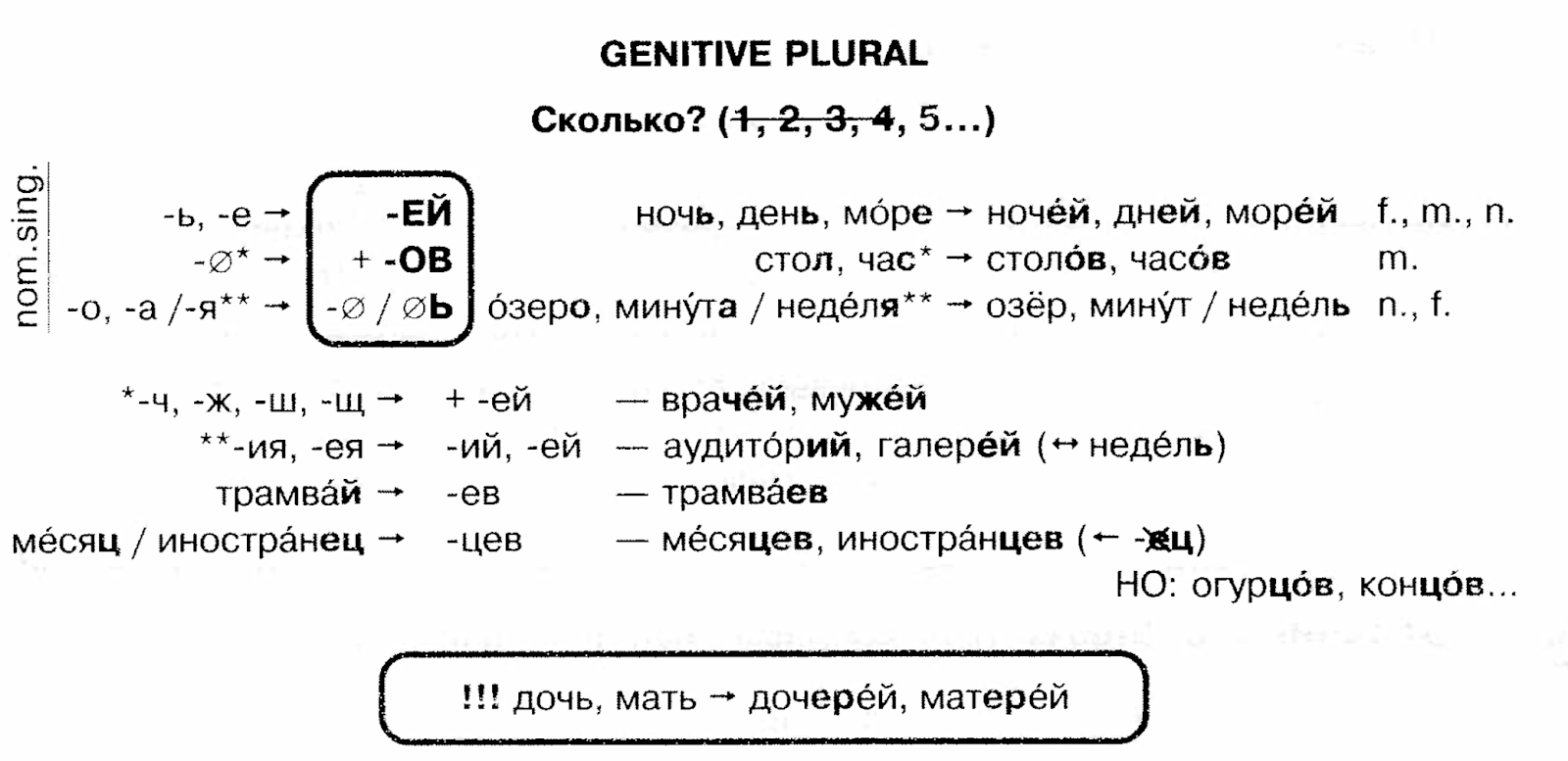
While Russian’s case system is not particularly unique there is the case of the particularly unpleasant Russian genitive. There are a couple of historical reasons for this; the Proto-Indo-European ablative case was folded into the modern genitive case, and the genitive is used for expressions of quantity which still retain an archaic dual number form used for numbers of things between two and four. The abessive construction (“there is no book”) also uses the genitive form. The formation of the genitive plural is famously complicated and difficult and as a student of Russian you devote considerable time and practice to this very common and challenging puzzle.
As if that wasn’t enough to keep straight, the genitive form (but not construction) comes into play when a direct object has a soul, though only if it is a masculine noun. When declining a masculine animate direct object one uses the genitive form not the accusative.

The declension of numerals in Russian is its own special challenge which is hard to convey in English but involves a lot of genitive cases. You can look at the Wikipedia section to get a little taste though.
Most numbers ending with “1” (in any gender: оди́н, одна́, одно́) require Nominative singular for a noun: два́дцать одна́ маши́на (21 cars), сто пятьдеся́т оди́н челове́к (151 people). Most numbers ending with “2”, “3”, “4” (два/две, три, четы́ре) require Genitive singular: три соба́ки (3 dogs), со́рок два окна́ (42 windows). All other numbers (including 0 and those ending with it) require Genitive plural: пять я́блок (5 apples), де́сять рубле́й (10 rubles). Genitive plural is also used for numbers ending with 11 to 14 and with inexact numerals: сто оди́ннадцать ме́тров (111 meters); мно́го домо́в (many houses). Nominative plural is used only without numerals: э́ти дома́ (these houses); cf. три до́ма (3 houses; G. sg.). These rules apply only for integer numbers. For rational numbers see below.
https://en.wikipedia.org/wiki/Russian_declension#Numerals
The Russian writing and sound system isn’t so hard in my opinion for native English speakers, once you get used to the Cyrillic alphabet. There are some things that stand out as distinct compared to English however.
The first is the letter <Ы> which one pronounces a bit like the “i” in “bill”, but pronounced much lower in your throat. There is a distinction made between this sound and “И” (sounds like “ee”) although when the two sounds are spoken it’s damn hard to hear the difference normally. Also important distinctions are made between voiced and unvoiced “sh” and palletized consonants, which again I think are extremely difficult for a native English speaker to pick up on or enunciate without a great deal of practice. There is a letter “Ё” (“yo”) which is often just written as “E” (“ye”) which a Russian student just has to accept and assume they are being tricked sometimes. Finally there are the unspoken letters “Ь” and “Ъ” which are called soft sign and hard sign. The soft sign palletizes the letter in front of it and the hard sign mostly doesn’t do anything (occasionally depalletizing or demarcating a stop), and used to be extremely common in writing until the Bolsheviks ruthlessly purged it almost entirely from the language.
The Cyrillic alphabet is named after St. Cyrill who did not invent it but did invent an alphabet called Glagolitic (“speaking”) of which a few letters were taken for the Cyrillic alphabet, though aside from those characters Cyrillic is mostly cribbed from the Greek alphabet.
One of the easiest things to learn in Russian is the conjugation of verbs. In fact there is only really one set of personal endings you have to learn (well, two conjugations but they’re the same pattern). On top of this there are only three tenses to contend with (past, present, and future). The past is formed by adding gender markers (a standard masculine/feminine/neuter or one shared plural suffix) to the root, which is refreshingly simple although it seems strange that the gender is relevant for the conjugation of verbs and only in the past. Participles do exist but as far as I can tell they are basically never encountered and only as sort of a final footnote in most textbooks.
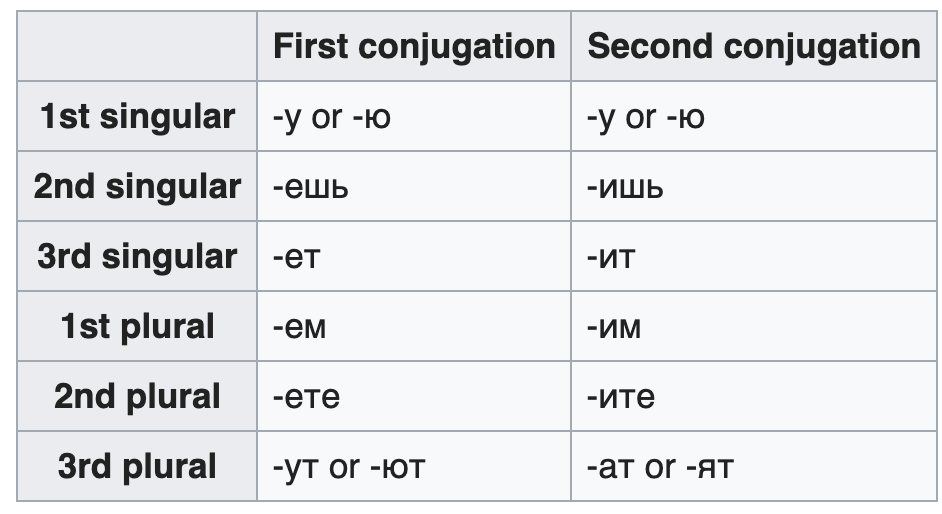
The only real complication with verbs is the previously mentioned perfective/imperfective aspect and prefixes. Verbs can have things stuck on the front to indicate if it is perfect or imperfect, and a future tense is simply formed by using a perfective form in what would normally look like the present, but since you can’t have a perfect action in the present, it means it’s the future instead. A bit odd but does make a certain kind of sense when you think about it.
Finally one last notable difference between English and Russian is swearing. The level of expressivity and creativity that appears to go into swearing in Russian is on another level, and probably beyond any sort of deep comprehension to a non-native speaker. Swear words also have vastly more force in Russian, and would almost never be uttered in any sort of semi-polite company and some probably would get you ejected from respectable society.
I am unable to really grasp the subtleties and complexity of the different prefixed and suffixed versions of “fuck” in Russian, and Google Translate doesn’t even try.
Studying Russian is a challenge, but getting all of the grammar right is really not the most important thing for daily usage. Even if you screw up most of the inflections people can still understand your meaning, and even native speakers get things wrong frequently. For me the hardest part is not speaking Russian but understanding what people say, mostly due to my unimpressive vocabulary and the speed in which people speak, but that can be true in any language and isn’t specific at all to Russian.