WebRTC is a new standard defining peer-to-peer (usually) live video/audio streaming. It can be easily used in web browsers with JavaScript. It is brand new and not fully deployed yet (supported in all browsers except Safari, with Safari support coming soon).
It is a way to do streaming live video without Flash or HLS, both of which suck.
Janus
Janus is a two-faced server written in C that speaks RTP and RTSP on one side, and WebRTC on the other. It acts like a WebRTC peer and can be used to turn WebRTC into a client/server model, or facilitate client/client communications. It is an awesome project and will enable all kinds of cool, standards-based, real-time video and audio communication in web browsers and other things.
Your own peer-to-peer Skype replacement website
With Janus and a couple hundred lines of JavaScript you could make a peer-to-peer video calling web page. It’s really not that hard. Why not make something to replace the piece of shit that is Skype. It’ll be insanely popular and you barely need any infrastructure.
I’ve always thought it’d be really cool to have a geospatial visualization of different economic measurements like GDP, PPP, happiness, Gini coeffecient, core and non-core inflation, unemployment, corruption, etc. This would give anyone in the world the ability to visualize how different countries (and regions?) stack up to each other in an intuitive way. Graphs and data are not accessible to most people, but visually seeing their country be obviously shittier compared to neighboring countries could help increase demand for measures to improve the quality of life of their citizenry.
Maps and visualizations can convey information and affect people a lot more than articles and numbers can.
Trick is finding good, comparable sources of data. Probably the CIA world factbook and Shadow Govt Stats would be good places to start.
AWS is awesome and can save companies gazillions of dollars on capex, datacenter, personnel, development and operations costs. If you aren’t using AWS you’re an idiot. Really. You just don’t know it yet.
Doing AWS The Right Way isn’t hard but requires some experience or just reading how to do it The Right Way.
So many businesses have important applications that are built on old systems like COBOL and JCL.
They are desperate to modernize these codebases and not be reliant on impossible-to-replace hardware and systems that nobody understands and cannot hire anyone to do.
COBOL is incredibly unsexy-sounding and most young people have never heard of it and want to build apps or screw around with JavaScript.
Everyone who is qualified to do this is dead or retired.
Companies and governments are unable to hire anyone to fix their crap.
COBOL is incredibly easy to read. Probably hard to write, but you wouldn’t need to write any.
Porting legacy applications to modern systems could be extremely fun and lucrative.
7 Reality capture * VR
Someone is going to have a lot of fun and make a ton of money making games or whatever by buying reality capture devices and scanning in real-world environment (or built sets, theater-style) for photo-realistic VR applications.
I maintain a nifty music visualizer project called projectM. It is an open-source re-implementation of the venerable WinAmp Milkdrop visualizer.
It needs some software work to port it to be OpenGL-ES compatible.
Once it works with GLES you could easily make an embedded linux system (probably a Rasberry Pi or something more beefy) that would have audio in and HDMI out.
Attorney General Jeff Sessions believes we aren’t tough enough on drugs, and we need to lock people up longer to reduce crimes related to drugs. It’s an interesting theory, one that we’ve implemented at a policy level for quite a few decades. It seems that rarely do politicians or journalists ask the simple question: has it worked so far?
We’ve been issuing longer and longer jail and prison sentences for drug-related crimes, especially notably for the Schedule I “Devil’s Lettuce” scourge of violent hemp addicts inflicting untold misery on the population.
One could point out some flaws in the logic behind the theory that locking people up is good for society, reduces violence and drug usage, and is a deterrent to would-be tokers and dealers. Putting people behind bars with often violent criminals for years probably doesn’t make them better people. Keeping them away from their children probably doesn’t improve society. Incarcerating them probably isn’t great from a fiscal standpoint. Proscribing personal usage of certain drugs on a demonstrably arbitrary and non-medical, non-biological, non-psychological basis really seems to violate the reasonable concept of not prosecuting victimless crimes. The fact that addiction has been shown to be a disease, greatly predicted by genes in fact, and not a moral failing. The logic behind the idea that drugs can ruin lives, therefore we should lock them up with criminals in a cage for years away from their families, give them felony charges, and make it incredibly difficult to find gainful employment afterwards doesn’t seem to be a great life-enhancer either. The fact that ethanol alcohol, an incredibly toxic, dangerous, addictive, inhibition-destroying, violence-inducting drug and poison to all living tissue is readily available on most blocks in the country for unlimited purchase while marjiuana is classified as Schedule I, unavailable for research purposes without an extremely cumbersome DEA license, legislated as having no conceivable medical usage, and worthy of felony charges. By the federal government of course, not in the many states which currently permit medical and recreational usage.
One could go on at length about the contradictions in logic of this drug enforcement policy theory. It doesn’t seem to convince some people. After all it’s a complex topic, there are many very different kinds of drugs, behaviours, societal normals, scare campaigns and wildly-differing personal experiences. I don’t expect this matter to be settled by pure reasoning alone. Nor is it necessary to discuss this in the abstract.
What are the goals of the drug war? Ostensibly it’s to reduce overdoses, addiction, usage, drive up drug prices, reduce availability and deter usage and related criminal activity. Reasonable goals, I think most would agree.
Or as one of the top aids to Nixon, who launched the drug prohibition campaign, describes the policy:
“The Nixon campaign in 1968, and the Nixon White House after that, had two enemies: the antiwar left and black people,” former Nixon domestic policy chief John Ehrlichman told Harper’s writer Dan Baum …
“You understand what I’m saying? We knew we couldn’t make it illegal to be either against the war or black, but by getting the public to associate the hippies with marijuana and blacks with heroin. And then criminalizing both heavily, we could disrupt those communities,” Ehrlichman said. “We could arrest their leaders. raid their homes, break up their meetings, and vilify them night after night on the evening news. Did we know we were lying about the drugs? Of course we did.”
Did you fall for this campaign perhaps? Well you’re an idiot. But ignoring your simple gullibility, let’s forget about this interview and focus on the laudable goals mentioned previously. Reducing demand, access, affordability and overdoses.
Opioids—prescription and illicit—are the main driver of drug overdose deaths. Opioids were involved in 33,091 deaths in 2015, and opioid overdoses have quadrupled since 1999.
Source: Substance Abuse and Mental Health Services Administration (SAMHSA), National Survey on Drug Use and Health
If you do any research you can easily see that overall demand for drugs has remained constant. People who want to do drugs will do them. All of the trillions of dollars spent on incarceration, interdiction, prosecution over fifty years have had little discernible impact on demand. Meanwhile fatal overdoses have greatly increased, hard narcotics prices have dropped dramatically. All kinds of drugs are trivially easy to obtain (according to my cool friends). Mexico is a failed state, run by narco-terrorists, and many cities are beset by gang violence for the simple reason that drugs are in great demand and quite illegal. Millions of lives have been ruined by the government in pursuit of getting people to not ruin their lives with drugs. So at what point does one look at the current policy and decide maybe it isn’t working out like the theory predicts? What’s the threshold for admitting maybe the last five decades of locking people up isn’t having the desired result?
Wikipedia: In October 2013, the incarceration rate of the United States of America was the highest in the world, at 716 per 100,000 of the national population. While the United States represents about 4.4 percent of the world’s population, it houses around 22 percent of the world’s prisoners.[1]Corrections (which includes prisons, jails, probation, and parole) cost around $74 billion in 2007 according to the U.S. Bureau of Justice Statistics.[2][3]
On what basis are we evaluating the effectiveness of this policy, if not based on medicine, price and availability, overdoses, demand, enriching of narco-terrorists and violent gangs, lives ruined, money wasted, or principles of justice?
Recently beautiful South San Francisco hosted the annual Silicon Valley PostgreSQL conference, a gathering of the world’s top open-source database nerds.
Some of the fantastic talks I attended were:
PL/pgsql:
A deep dive into the myriad features of the built-in postgres procedural language, PL/pgsql. It’s a sort of funny-looking but very capable and featureful language that lets you very easily mix procedural code with SQL statements and types based on your rows and tables. It’s something I’ve used before in a very limited form before but I really had no idea how many standard scripting language features were available, including things like “auto” and composite types, multiple return values, IN/OUT/INOUT/VARIADIC parameters, automatic function AST and SQL prepared statement caching, anonymous functions. PL/pgsql is very handy for trigger functions, administrative functions (like partitioning tables on a periodic basis) and distilling complex logic into reusable pieces. There are some important caveats about function performance, so if you’re planning on calling them often be sure to read up on what you should and shouldn’t do. Try to avoid functions calling other functions if possible, take advantage of the advisory keywords like IMMUTABLE and figure out if it’s okay to serialization inside of a transaction boundary.
pg_paxos:
Paxos is a distributed consensus algorithm and its integration into postgres as an extension gives you the nifty ability to paxosly-replicate tables and use a paxos(key) function to find out what value a majority of nodes report back with the option to use constraints as well. Seems like it could be useful for things like master elections, geographically disparate systems that have low latency for local writes but eventually become consistent, and times when you only care about an upper or lower bound (easy with the constraints). Not sure if I’ll ever have a need for it or not.
Go:
Went to a talk on using go with postgresql. There’s a nice driver for it. Mostly people seem to do raw SQL queries, using ORMs like gorm doesn’t seem like a very popular option. I imagine largely because people using go are doing so because they care about performance, and because ORMs are going to obviously be more limited in a feature-constrained compiled language. Speaker claimed his go rewrite of pgnetdetective was a bajillion times faster than the python version.
Becoming a PostgreSQL Guru:
We all want to be the proverbial unixbeard guru in the corner office who acolytes petition to receive tidbits of wisdom. A big ingredient in achieving enlightenment involves knowing what the new aggregate functions (see sections 7.2.4 and 7.2.5) can do for you. There are easy ways to auto-generate hierarchical aggregates by groups of different ranges and sets, using GROUPING SETS, CUBE, ROLLUP, LATERAL JOIN, CTE and window functions. If you find yourself needing to generate some reports there’s a really good chance some of these new features can speed things up a huge amount and require less code.
Durability:
Postgres has many knobs related to how safe you want to be with your data. These are great to know about in some detail because often you will have different demands based on your application or business. Naturally they have tradeoffs so knowing how to make informed choices on the matter is crucial. For example if you’re a bank, you may not want to finish a transaction until 3-phase commit happens on all write replicas, but if you have some web session cookie table or log table on a single box you may want to make it SET UNLOGGED to vastly improve performance, with the caveat that you may not have perfect crash recovery of the latest writes if something terrible happens. Great that postgres gives you lots of options in these areas.
Supporting legacy systems:
A gentleman from a consulting company shared his experiences as a person hired by companies to come in and support or maintain or migrate extreme legacy systems and how useful postgres is in that process, along with some Java toolkit for bridging old systems. He namedropped things like FoxPro, JCL, COBOL, Solaris and a bunch of other things I didn’t recognize. I’ve always thought it’d be a fun job to take these ultra old systems that companies entirely depend on and are desperate to get off of and help them out. It’s not hip like writing new JavaScript build systems or whatever but I bet there’s real good money in it. One thing that’s always stuck in my head was how during the California budget crisis ten years ago or so, the governor wanted to pay all state employees minimum wage but the comptroll-er said it couldn’t be done. You see, the state’s payroll system runs on COBOL and their two job reqs have gone unfilled for years and years. Probably because all COBOL devs are dead or retired. It’s written out in plain English though so I don’t get what the big deal is…
In conclusion it was a fine set of talks, I wish I could have seen some of the others that were going on at the same time in other rooms. The SF Postgresql Meetup has more of these same types of great informative lectures going on year-round and I highly recommend attending them if this sort of stuff gets you pumped up too.
This so-called reporting on the DNC hack really grinds my gears.
First let me preface this by saying I am not claiming to know who hacked the DNC, although it’s probably the Guccifer 2.0 person who’s been blogging about it the entire time. Maybe it was actually people working in the FSB and GRU for the Kremlin. That is beside the point. The point is the evidence that has been trotted out is of extremely questionable quality, the people reporting on it are clueless muppets who don’t know shit about computers, all sources point back to one guy who is part of the company paid by the DNC to spin things, and you should be highly skeptical of these claims. Again, maybe Russians did do it, I really have no idea obviously. But the absurd claims being said and printed really need some fact checking. Seems to be all the rage these days so let me try my hand at it here.
Let’s talk about what is being reported!
In the press there has been an unending stream of articles blaming Russian and specifically Putin himself for the hack. Usually with a photo of Putin and a stock image of a faceless male in a hoodie typing on a laptop with numbers flying out of it as he hacks the shit out of governments.
All of these stories lead back to the same person, the CTO of CrowdStrike which got called in and paid to do PR damage control for the DNC. Every article about this for a long time had only his blog post as evidence, nothing more.
Now attributing hacks is a really, really, really hard problem. I cannot stress this enough. It is incredibly difficult to be sure of who actually was behind a hack. More recently they have claimed that the IPs that were used came from Russia, and they used tools that they believe were used by the same russian hackers previously. Now if you know anything about computers at all you wouldn’t be one of these muppet “reporters” and you’d probably have a real job, and you’d also know that isn’t remotely convincing evidence.
There is an atrocious Buzzfeed article (why) that makes really goofball claims, including attributing some totally random unrelated ISIS hack was actually done by the same russians because a machine believed to have been compromised by the same russkiis was used. Well guess what, if a computer is hacked by one person, usually it’s backdoored and lots of services are enabled and any firewalls are removed and it’s open for anyone else to use who stumbles across it. But of course what would one expect from Buzzfeed. Also I suggest not listening to any other Cyber Journalists, and that goes doubly true for Brian Krebs who still has a vendetta against me (really, I asked him recently) for trolling him and many others and nearly ending his career with some off-the-wall claims.
You can read the article here but I don’t really recommend it because it will make you stupider: https://www.buzzfeed.com/…/meet-fancy-bear-the-russian-grou…
Now we have Mrs. Clinton saying Putin is trying to destabilize the election by hacking the DNC to get Trump elected. Says 17 intelligence agencies “confirmed” it. Really she means DNI Clapper, noted perjurer, who said “We believe, based on the scope and sensitivity of these efforts, that only Russia’s senior-most officials could have authorized these activities.” Words matter, especially ones like “confirmed” when you’re talking about attributing hacking. You know, the thing that’s really, really, really hard to be certain about. Note that “confirmed” does not appear anywhere in that statement.
The FBI says Russians probably did it. I assume that they are going off of the CrowdStrike report although who knows. They also claim that North fucking Korea hacked Sony based on hard evidence such as “the FBI discovered that several Internet protocol (IP) addresses associated with known North Korean infrastructure communicated with IP addresses that were hardcoded into the data deletion malware used in this attack”.
You know, the DPRK where the entire country’s phone system works by means of human fucking switchboard operators.
Little is also made of the fact that there’s actually someone calling themselves “Guccifer 2.0” (fun fact: Mr. 1.0 lied about hacking Mrs. Clinton’s email for lulz, which set off that whole wacky investigation into her email servers) who’s been maintaining a blog this whole time leaking documents from the hack and lolling at the ineptitude of people making wild claims about multiple russian intelligence agencies being behind it all.
Guccifer 2.0 posted this message while releasing the hacked documents:
“Worldwide known cyber security company CrowdStrike announced that the Democratic National Committee (DNC) servers had been hacked by “sophisticated” hacker groups.
I’m very pleased the company appreciated my skills so highly))) But in fact, it was easy, very easy.
Guccifer may have been the first one who penetrated Hillary Clinton’s and other Democrats’ mail servers. But he certainly wasn’t the last. No wonder any other hacker could easily get access to the DNC’s servers.
Shame on CrowdStrike: Do you think I’ve been in the DNC’s networks for almost a year and saved only 2 documents? Do you really believe it?
Here are just a few docs from many thousands I extracted when hacking into DNC’s network.”
On the CrowdStrike blog they responded by claiming the blog must be a russian disinformation smokescreen. Okay.
Some more of the “evidence” released includes statements like “Fancy Bear has used sophisticated — and expensive — malware during its operations”, which of course the russian government provides (while also stating that the operatives are at arm’s length from the government and don’t really have contact with the government, not sure how that works). I am not sure what to make of this statement. I think they are referring to 0-days? Then they say the DNC was hacked because someone made a Google Apps login page at “accoounts-google.com“. Now domains aren’t free but like, I don’t think you gotta have a nation-state-sized bank account to afford one.
They even go so far as to make the claim that not one commie intelligence agency but BOTH theКГБ I mean FSB AND the GRU both hacked the DNC by accident at the same time. Wow! Incredible
CrowdStrike also helpfully provided the IoCs, hashes of the trojans used by the hackers. I tried looking up some of the hashes and found nothing but references back to the same story. Maybe they know something we don’t, but they haven’t really said what.
Also let us not forget that there has been a constant, unrelenting media and economic assault on the pinko bastards for years and nothing would make officials happier than to have more villainous deeds to pin on Putin. He’s a dick, no doubt, but one should consider the interest our government has in reaching a certain conclusion. Many times in recent history these sort of motivations have produced their desired conclusions which turn out to be utterly incorrect. Remember that business about WMDs in Iraq? Or the utter failure to predict the Soviet Union collapsing because the director of the CIA fired anyone who said the Soviets weren’t a giant powerful menace? (ok I don’t remember that one since I was like five but you get my point).
What is my point again? My point is that you should look at these claims with a very critical eye. Remember that attributing hacking is really, really, really hard. It is also trivial for someone to forge an attack to look like it was done by another person or government when we allow the standards of evidence to be so low. Or even quite likely, simply someone randomly reusing an owned host or rootkit source that was left behind.
Be wary of anyone claiming to know who hacked whom. Be extra wary of claims that the hackers are working under the explicit direction of a foreign government. Sometimes they are! This is not in dispute. But it’s incredibly difficult to be confident of these things, it’s incredibly easy to set someone else up, and anyone who earnestly uses the word “cyber” in their speech should be immediately suspect.
Take this shit seriously because it is getting more and more serious. NATO has said that hacking is an act of war that can be retaliated against with violence.
I promise you that every evil troll antisocial misanthrope (of which there is no shortage of) who reads these proclamations is immediately thinking about just how easy it would be to set off WWIII. I’d really prefer that not happen. If people demand a higher standard of evidence and attribution that may make a real difference.
I wrote about this previously, going into more depth regarding the attribution problem, which as I mentioned, is really, really, really hard.
The Affordable Care Act, also known by many as Obamacare really set this country’s healthcare system back in a major way. Let me try to explain why I have such an issue with it.
The biggest problem is that it is not a single-payer (“government-funded”) healthcare system like in every other first world country, not to mention very many third world countries too. This is the only correct system. If you believe our system of health insurance is more or less functioning properly and nicely and efficiently and providing the best bang for our personal and government-contributed bucks, you are utterly misinformed.
Working in healthcare IT for many years has given me a small glimpse into the madhouse of medical billing in America. The system is fucked. Ask anyone in healthcare and they’ll tell you the same thing. It’s all dumb. The thousands upon thousands of different insurance plans, the multitude of types (government, HMO, PPO, Discount Card, Indemnity, POS, EPO, Medicare, Medicare Advantage, Medi-Cal, Medicaid, Premier, Worker’s Compensation…) have different rules about reimbursement and fracture the American people’s ability to negotiate good deals on drugs and services. There is wild variation in prices due to an utter lack of transparency. The scheme of employers providing healthcare for their workers makes no logical sense, hurts competitiveness and massively screws over anyone who loses their job, unless they want to pay COBRA to keep their coverage (now around $1000/mo for some). Medical bills are submitted to third parties on all sorts of different paper forms, often faxed around. Oh yes, faxes are considered state of the art when it comes to medical billing and health insurance companies. In short, the current system would only be considered acceptable by anyone who has no idea how much better pretty much everyone in the developed world has it than us. This is reflected by popular opinion, as of 2016, showing a majority of Americans just want a normal federal-funded single-payer healthcare system. It’s the obvious solution, everybody knows it. So why don’t we have it?
Well, we have this health insurance scheme instead. Instead of the government providing basic healthcare to everyone it only provides healthcare to some people through a bewildering array of disparate systems. Poor people, people with kids, poor people in California, seniors, veterans, congresscritters, that sort of thing. If you don’t fit into one of those you can buy healthcare insurance instead of maybe get it provided by your employer if you’re lucky. A plan can cost several hundred dollars a month and may or may not include vision and dental insurance too. There is a provision of the ACA that says everyone must have health insurance or face a steep tax penalty (2.5% of your total household adjusted gross income). As a result, everyone must have health insurance.
Now I, just a lowly taxpayer, wonder if everyone has insurance, what exactly are the insurance companies doing? What benefit do we as a society gain from a universal system of insurance? Well, supposedly the health insurance companies price risk appropriately and disburse funds for claims.
Probably the main indicator of your likelihood of filing a lot of expensive claims are your pre-existing conditions. Like if you have cancer or some rare disease, you’re going to cost a lot of money. Before the ACA this would make it very hard to get normal health insurance because you would be a terrible policyholder from the insurance company’s point of view. One of the truly fantastic things, and at the same time one of the most subtly problematic things in the ACA is that it disallows pre-existing conditions from driving up your premiums or being denied coverage. This is actually really great news for seriously ill people, and it deserves being said that it has given (relatively) reasonably-priced healthcare to millions of people who need it the most. The end result appears to be a major net positive for society, and it really is. Taken in a vacuum this is a noble and wonderful thing. But it also undermines the entire argument for the extant system.
Now if everyone has insurance, and the insurance companies are not allowed to properly price risk, what function do they provide? If they cannot perform any real actuarial purpose then they are essentially clogging the arteries of our healthcare system, siphoning off vast quantities of money, wasting everyone’s time and collecting a massive payoff while decimating the quality of our healthcare.
Healthcare providers just want to care for people and, well, provide health care. That’s why they got into it and that’s what makes them put up with the years of school and massive debt and internships and all the rest. Once they actually try to practice medicine though they are faced with the intractable and thankless task of trying to deal with health insurance companies. Filing claims, getting denied, re-filing claims, telling patients you can’t see them because their employer went with the wrong insurance company or plan type, telling seniors they can’t get the medicine they need, buying ink for your fax machine, dealing with your medical billing intermediary company, upgrading to ICD-10, and on and on. This takes time and costs a great deal of money. It is not good for anyone except for the health insurance companies because it gives them a reason to exist.
The potential saving in efficiency, the massive gain in time of providers and nurses and office managers, the insanely powerful bargaining power, the standardization of billing forms and reimbursements would be some of the incredible benefits of having a coherent national health system. My problem with the ACA is that it cements this horrible mess of insurance providers. Its smaller improvement in expanding coverage means that we can pretend our system works for longer now instead of getting the sane and efficient system that we desperately need. That is why I have a problem with it. It powers the vacuum machine stuck in our pockets by health insurance companies. It entrenches the current corrupt system. It makes it that much harder for us to right it. The current shit abyss of healthcare probably resembles that of our legal system. It’s something most of us healthy people don’t have to get too acquainted with, so we don’t demand much change because it doesn’t affect us yet. But when you fall into this pit you’re going to wonder why our country is so fucked up. Even having health insurance won’t protect you from bankruptcy, of which health care is now the number one cause in America.
If a majority of Americans want a single-payer system, and we’re the only country that hasn’t gotten it yet, why do we still have this joke system of rent-seeking insurance companies taking their fat slice of the $2.9 trillion dollars a year we spend on health care (projected to shoot to $5.2 trillion in 2023)? Well, for one thing the opinions of the bottom 50-70% or so of Americans have no discernible impact on policy that gets made at the federal level. As in, the majority of Americans are literally disenfranchised because politicians do simply do not care what they think.
In 2007 health insurance companies were major donors to Obama’s and Hillary Clinton’s campaigns to become president. In the 2012 campaigns the insurance industry (with Blue Cross as the largest individual) contributed “a record $58.7 million to federal parties and candidates as well as outside spending groups” according to OpenSecrets. Draw your own conclusions.
MarketWatch has a bunch more fun facts about specific major problems with our health insurance system.
If you remember the old windows music player Winamp, it came with an amazing visualizer named Milkdrop written by a guy at nVidia named Geiss. This plugin performed beat detection and splitting the music into frequency buckets with an FFT and then fed that info into a randomly-selected “preset.” The presets are equations and parameters controlling waveform equations, colors, shapes, shaders,”per-pixel” equations (not actually per-screen-pixel, rather a smaller mesh that is interpolated) and more.
Most of the preset files have ridiculous names like:
“suksma + aderassi geiss – the sick assumptions you make about my car [shifter’s esc shader] nz+.milk”
“lit claw (explorers grid) – i don’t have either a belfry or bats bitch.milk”
“Goody + martin – crystal palace – Schizotoxin – The Wild Iris Bloom – mess2 nz+ i have no character and feel entitled to one.milk”
Milkdrop was originally only for windows and was not open-source, so a few very smart folks got together and re-implemented Milkdrop in C++ under the LGPL license. The project created plugins to visualize Winamp, XMMS, iTunes, Jack, Pulseaudio, ALSA audio. Pretty awesome stuff.
This was a while ago, but recently I wanted to try it out on OSX. I quickly realized that the original iTunes plugin code was out of date by about 10 major versions and wasn’t even remotely interested in compiling, not to mention lacking a bunch of dependencies built for OSX.
So I went ahead and updated the iTunes plugin code, mostly in a zany language called Objective-C++ which combines C++ and Objective-C. It’s a little messed up but I guess it works for this particular case. I grabbed the dependencies and built them by hand, including static versions for OSX in the repository to make it much easier for others to build it (and myself).
Getting it to build was no small feat either. Someone made the unfortunate decision to use cmake instead of autotools. I can understand the hope and desire to use something better than autotools, but cmake ain’t it. Everything is written in some ungodly undocumented DSL that is unlike any other language you’ve used and it makes a giant mess all over your project folders like an un-housebroken puppy fed a laxative. I have great hope that the new Meson build system will be awesome and let us all put these miserable systems out to pasture. We’ll see.
cmake – not even once
Long story short after a bunch of wrangling I got this all building as a native OSX iTunes plugin. With a bit of tweaking and tossing in the nVidia Cg library I got the quality and rendering speed to be top-notch and was able to reduce the latency between the audio and rendering, although I think there’s still a few frames of delay I’d like to figure out how to reduce.
I wanted to share my plugin with Mac users, so I tried putting it in the Mac App Store. What resulted was a big fat rejection from Apple because I guess they don’t want to release plugins via the app store. You can read about those travails here. I think that unpleasant experience is what got me to start this blog so I could publicly announce my extreme displeasure with Apple’s policies towards developers trying to contribute to their ecosystem.
After trying and failing to release via the app store I put the plugin up on my GitHub, along with a bunch of the improvements I made. I forked the SourceForge version, because SourceForge can go wither and die for all I care.
I ended up trying to get it running in a web page with Emscripten and on an embedded linux device (raspberry pi). Both of these efforts required getting it to compile with the embedded spec for OpenGL, GLES. Mostly I accomplished this by #ifdef’ing out immediate-mode GL calls like glRect(). After a lot more ferocious battling with cmake I got it running in SDL2 on Linux on a Raspberry Pi. Except it goes about 1/5fps, lol. Need to spend some time profiling to see if that can be sped up.
I also contacted a couple of the previous developers and the maintainers on SourceForge. They were helpful and gave me commit access to SF, one said he was hoarding his GLES modifications for the iOS and Android versions. Fair enough I guess.
Now we’re going to try fully getting rid of the crufty old SourceForge repo, moving everything to GitHub. We got a snazzy new GitHub homepage and even our first pull request!
My future dreams for this project would be to make an embedded Linux device that has an audio input jack and outputs visualizations via HDMI, possibly a raspberry pi, maybe something beefier. Apparently some crazy mad genius implemented this mostly in a FPGA but has stopped producing the boards, I don’t know if I’m hardcore enough to go that route. Probably not.
In conclusion it’s been nice to be able to take a nifty library and update it, improve it, put out a release that people can use and enjoy, and work with other contributors to make software for making pretty animations out of music. Hopefully with our fresh new homepage and an official GitHub repo we will start getting more contributors.
I recorded a crappy demo video. The actual visualizer is going 60fps and looks very smooth, but the desktop video recorder I used failed to capture at this rate so it looks really jumpy. It’s not actually like that.
Editing the source of a lambda procedure in AWS can be very cumbersome. Logging in with two-factor authentication and then selecting your lambda and using their web-based “IDE” with nested scroll bars going on on the page is not the greatest. Even worse is if your function actually has dependencies! Then you cannot view the source on the web and must download a zip file, and re-zip and upload it every time you wish to make a change.
After selecting a lambda to edit, it downloads the zip (even if it wasn’t originally a zip), sticks it in a temporary directory and creates a sublime project for you. When you save any of the files it will automatically zip up the files in the project and update the function source automatically, as if you were editing a local file. Simplicity itself.
If you use AWS lambda and Sublime Text, get this plugin! It’ll save you a ton of time. Watch it in action:
Video instructions for installing the plugin from scratch:
Apple stopped including the OpenSSL development headers on recent versions of OSX, trying to get people to move away from the old 0.9.8 version that’s been deprecated for a very long time. Making people stop using this shared library is a Good Thing to be sure but you may come across older software that you want to build for yourself.
If you try to compile a newer version of OpenSSL you will likely find that programs will fail to build against more recent versions because a lot of data structures have been hidden. You may see errors such as:
error: variable has incomplete type 'EVP_PKEY' (aka 'struct evp_pkey_st')EVP_PKEY pk;^/usr/local/include/openssl/ossl_typ.h:92:16: note: forward declaration of 'struct evp_pkey_st'typedef struct evp_pkey_st EVP_PKEY;
If you want to get such code to compile there’s a quick and easy solution! OSX still ships with the 0.9.8 library, you just need to provide the headers. Remove any newer versions of OpenSSL, grab the 0.9.8 sources, and copy over the headers:
In my previous post I describe my adventures in building an AWS IoT-enabled application for a proprietary embedded linux system and getting it to run. The next step in our journey is to create a service that communicates with our device and controls it in a useful way.
What can we do with a system running with the aws_iot library? We can use the MQTT message bus to subscribe to channels and publish messages, and we can diff the current device state against the desired device state shadow stored on the server. Now we need the service side of the puzzle.
My sample IoT application is to be able to view images on an IP camera from anywhere on the internet. I’m planning to incorporate live HD video streaming as well but that is a whole other can of worms we don’t need to open for this demonstration. My more modest goal for now will be to create a service where I can request a snapshot from the camera be uploaded to AWS’s Simple Storage Service (S3) which can store files and serve them up to authenticated users. In addition I will attempt to build the application server logic around AWS Lambda, a service for running code in response to events without actually having to deploy a server or run a daemon of any sort. If I can manage this then I will have a truly cloud-based service; one that does not consume any more resources than are required to perform its job and with no need to pre-allocate any servers or storage. It will be running entirely on Amazon’s infrastructure with only small bits of configuration, policy and code inserted in the right places to perform the relatively simple tasks required of my app. This is the Unemployed DevOps lifestyle, the dream of perfect lazy scalability and massive offloading of effort and operations to Amazon. There is of course a large downside to this setup, namely that I am at the mercy of Amazon. If they are missing a feature I need then I’m pretty much screwed and if their documentation is poor then I will suffer enormously. A partial description of my suffering and screwed state continues below.
I’ve been bitten before by my foolish impetuousness in attempting to use new AWS services that have clearly not been fully fleshed out. I was an early adopter of the CodeDeploy system, a super useful and nifty system for deploying changes to your application on EC2 instances from S3 or even straight from GitHub. Unfortunately it turned out to not really be finished or tested or documented and I ended up wasting a ton of time trying to make it work and deal with corner cases. It’s a dope service but it’s really painfully clear nobody at AWS has ever bothered to actually try using it for a real application, and all of my feature requests and bug reports and in-person sessions with AWS architects have all resulted in exactly zero improvements despite my hours of free QA I performed for them. As a result I am now more cautious when using new AWS services, such as IoT and Lambda.
In truth attempting to make use of the IoT services and client library has been one of the most frustrating and difficult uphill battles I’ve ever waged against a computer. The documentation is woefully incomplete, I’ve wasted tons of time guessing at what various parameters should be, most features don’t really behave as one would expect and the entire system is just super buggy and non-deterministic. Sometimes when I connect it just fails. Or when subscribing to MQTT topics.
Usually this doesn’t happen. But sometimes it does!
Why does it disconnect me every few seconds? I don’t know. I enabled autoReconnect (which is a function pointer on a struct unlike every other function) so it does reconnect at least, except when it just fails for no apparent reason.
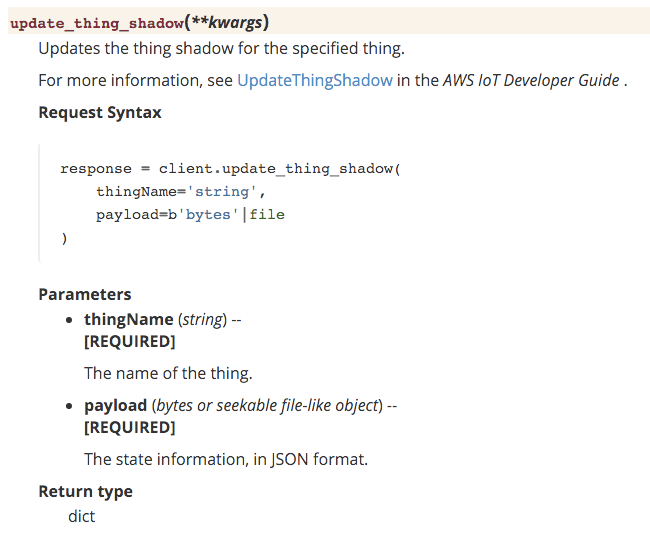
On the boto3 (python AWS clienet library) side things are not really any better. The device shadow support (called IoT Dataplane) documentation is beyond unhelpful at least as of this writing. If you want to update a device state dictionary (its “shadow”) in python, say, in a lambda, you call the following method:
Usually when you want to specify a dictionary-type object as a param in python it’s customary to pass it around as a dict. It’s pretty unusual for an API that is expecting a dictionary data structure to expect you to already have encoded it as JSON, but whatever. What is really missing in this documentation is the precise structure of the update payload JSON string you’re supposed to pass in. You’re supposed to pass in the desired new state in the format {“state”: { “desired”: { … } } }:
If you hunt around from the documentation pages referenced by the update_thing_shadow() documentation you may uncover the correct incantation, though not on the page it links to. It would really save a lot of time if they just mentioned the desired format.
I really definitely have no reason why it wants a seekable object for the payload since it’s not like you can really send files around. I actually first attempted to send an image over the IoT message bus with no luck, until I realized that the biggest message that can ever be sent over it is 128k. This application would be infinitely simpler if I could transmit the image snapshot over my existing message bus but that would be too easy. I am fairly certain my embedded linux system can handle buffering many megabytes of data and my network is pretty solid, it’s really a shame that AWS is so resource-constrained!
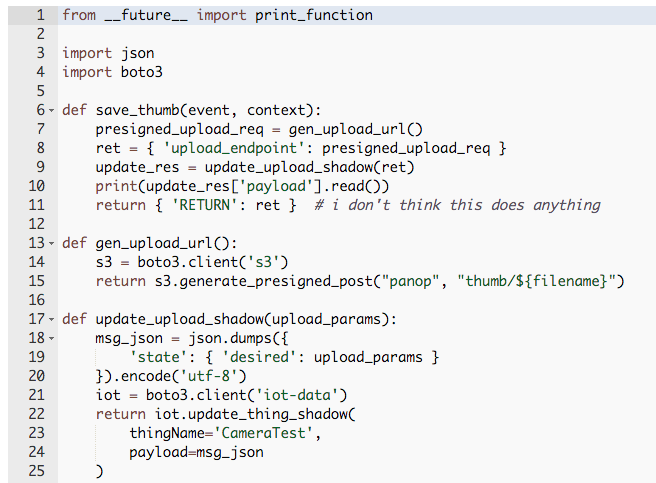
The reason I am attempting to use the device shadow to communicate is that my current scheme for getting an image from the device into AWS in lieu of the message bus is:
The camera sends a MQTT message that indicates it is online
When the message is received, a DevicePolicy matches the MQTT topic and invokes a lambda
The lambda generates a presigned S3 request that will allow the client to upload a file to an S3 bucket
The lambda updates the device shadow with the request params
A device shadow delta callback on the camera is triggered (maybe once, maybe twice, maybe not at all, by my testing)
Callback receives the S3 request parameters and uploads the file via libcurl to S3
Can now display thumbnail to a web client from S3
I went to the AWS Loft to talk to an Amazon architect, a nice free service the company provides. He didn’t seem to know much about IoT, but he spoke with some other engineers there about my issues. He said there didn’t appear to be any way to tell what client sent a message, which kind of defeats the entire point of the extra security features, and he was going to file an internal ticket about that. As far as uploading a file greater than 128k, the above scheme was the best we could come up with.
Regarding the security, I still am completely at a loss as to how one is supposed to manage more than one device client at a time. You’re supposed to create a “device” or a “Thing”, which has a policy and unique certificate and keypair attached to it and its own device shadow state. I assume the keypair and device shadows are supposed to be associated with a single physical device, which means you will need to automate some sort of system that provisions all of this along with a unique ThingName and ClientID for each physical device and then include that in your configuration header and recompile your application. For each device, I guess? There is no mention of what exactly how provisioning is supposed to work when you have more than one device, and I kinda get the feeling nobody’s thought that far ahead. Further evidence in support of this theory is that SNS messages or lambdas that are invoked from device messages do not include any sort of authenticated ClientID or ThingName, so there’s no way to know where you are supposed to deliver your response. Right now I just have it hard-coded to my single Thing for testing. I give Amazon 10/10 for the strict certificate and keypair verification, but that’s only one part of a scheme that as far as I can tell has no mechanism for verifying the client’s identity when invoking server-side messages and code.
It wasn’t my intention to bag on AWS IoT, but after months of struggling to get essentially nowhere I am rather frustrated. I sincerely hope that it improves in usableness and stability because it does have a great deal of powerful functionality and I’d very much like to base my application on it. I’d be willing to help test and report issues as I have in the past, except that I can’t talk to support without going in to the loft in person or paying for a support plan, and the fact that all of my previous efforts at testing and bug reporting have added up to zero fixes or improvements doesn’t really motivate me either.
If I can get this device shadow delta callback to actually work like it’s supposed to I’ll post more updates as I progress. It may be slow going though. The code, such as it is, is here.
I’m more allergic than most people to buzzwords. I cringe big time when companies suddenly start rebranding their products with the word “cloud” or tack on a “2.0”. That said, I realize that the cloud is not just computers in a datacenter and the Internet of Things isn’t all meaningless hype either. There exists a lot of cool new technology, miniaturization, super cheap hardware of all shapes and sizes and power requirements, ever more rapid prototyping and lot more that adds up to what looks like a new era in embedded system hardware.
People at the embedded linux conference can’t wait to tell you about IoT stuff
But what will drive this hardware? There is a lot of concern about the software that’s going to be running on these internet-connected gadgets because we all just know that the security on most of these things is going to be downright laughable, but now since they’re a part of your car, your baby monitor, your oven, your insulin pump and basically everything, this is gonna be a big problem.
So I’ve embarked on a project to try to build an IoT application properly and securely. I think it’ll be fun, a good learning experience, and even a useful product that I may be able to sell one day. At any rate it’s an interesting technical challenge.
My project is thus: to build a cloud-based IoT (ughhh sorry) IP camera for enterprise surveillance. It will be based on as much open source software as possible, ABRMS-licensed, mobile-first and capable of live streaming without any video transcoding.
I think I know how to do this, I’ve written a greatdeal of real-timestreamingsoftware in the past. I want to offload as much as the hard stuff as possible; let the hardware do all the h.264 encoding and let AWS manage all of the security, message queueing and device state tracking.
At the Dublin gstreamer conference I got to chat up an engineer from Axis, an awesome Swedish company that makes the finest IP cameras money can buy. He informed me that they have a new program called ACAP (Axis Camera Application Platform) which essentially lets you write what are essentially “apps” that are software packages that can be uploaded to their cameras. And they’re all running Linux! Sweet!
And recently I also learned of a new IoT service from Amazon AWS. I was dreading the humongo task of writing a whole new database-backed web application and APIs for tracking devices, API keys, device states, authentication, message queueing and all of that nonsense. Well it looks like the fine folks at Amazon already did all the hard work for me!
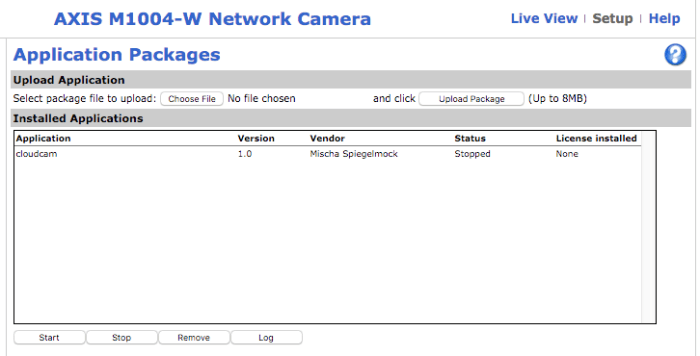
So I had my first development goal: create a simple AWS-IoT client and get it to run on an Axis camera.
Step one: get access to ACAP
Axis doesn’t really make it very easy to join their development program. None of their API documentation is public. I’m always very wary of companies that feel like they need to keep their interfaces a secret. What are you hiding? What are you afraid of? Seems like a really weird thing to be a control freak about. And it majorly discourages developers from playing around with your platform or knowing about what it can do.
But that is a small trifle compared to joining the program. I filled out a form requesting access to become a developer and was eventually rewarded with a salesbro emailing me that he was busy with meetings for the next week but could hop on a quick call with me to tell me about their program. I informed them that I already wanted to join the program and typed all the relevant words regarding my interest into their form and didn’t need to circle back with someone on a conference call in a few weeks’ time, but they were really insistent that they communicate words via telephone.
After Joe got to give me his spiel on the phone I got approved to join the Axis developer partner program. As far as ACAP they give you a SDK which you can also download as an Ubuntu VirtualBox image. Inside the SDK is a tutorial PDF, several cross-compiler toolchains, some shady Makefile includes, scripts for packaging your app up and some handy precompiled libraries for the various architectures.
Basically the deal is that they give you cross-compilers and an API for accessing bits of the camera’s functionality, things like image capture, event creation, super fancy storage API, built-in HTTP server CGI support, and even video capture (though support told me vidcap super jankity and I shouldn’t use it). The cross-compilers support Ambarella ARM, ARTPEC (a chip of Axis’s design) and some MIPS thing, these being the architectures used in various Axis products. They come with a few libraries all ready to link, including glib, RAPP (RAster Processing Primitives library) and fixmath. Lastly there’s a script that packages your app up, building a fat package for as many architectures as you want, making distribution super simple. Now all I had to do was figure out how to compile and make use of the IoT libraries with this build system.
Building mbedTLS and aws_iot
AWS has three SDKs for their IoT clients: Arduino Yún, node.js and embedded C linux platforms. The Arduino client does sound cool but that’s probably underpowered for doing realtime HD video, and I’m not really the biggest node.js fan. Linux embedded C development is where it is at, on the realz. This is the sort of thing I want to be doing with my life.
Word
All that I needed to do was create a Makefile that builds the aws_iot client library and TLS support with the Axis toolchain bits. Piece of cake right? No, not really.
The IoT AWS service takes security very seriously, which is super awesome and they deserve props for forcing users to do things correctly: use TLS 1.2, include a server certificate and root CA cert with each device and give each device a private key. Wonderful! Maybe there is hope and the IoT future will not be a total ruinfest. The downside to this strict security of course is that it is an ultra pain in the ass to set up.
You are offered your choice of poison: OpenSSL or mbedTLS. I’d never heard of mbedTLS before but it looked like a nice little library that will get the job done that isn’t a giant bloated pain in the ass to build. OpenSSL has a lot of build issues I won’t go into here.
To set up your app you create a key and cert for a device and then load them up in your code:
Simple enough. Only problem was that I was utterly confused by what these files were supposed to be. When you set up a certificate in the IoT web UI it gives you a public key, a private key and a certificate PEM. After a lot of dumbness and AWS support chatting we finally determined that rootCA referred to a secret CA file buried deep within the documentation and the public key was just a bonus file that you didn’t need to use. In case anyone else gets confused as fuck by this like I was you can grab the root CA file from here.
The AWS IoT C SDK (amazon web services internet of things C software development kit) comes with a few sample programs by way of documentation. They demonstrate connecting to the message queue and viewing and updating device shadows.
#defineAWS_IOT_MQTT_HOST"B13C0YHADOLYOV.iot.us-west-2.amazonaws.com"///< Customer specific MQTT HOST. The same will be used for Thing Shadow#defineAWS_IOT_MQTT_PORT8883 ///< default port for MQTT/S #defineAWS_IOT_MQTT_CLIENT_ID"MischaTest"///< MQTT client ID should be unique for every device#defineAWS_IOT_MY_THING_NAME"MischaTest"///< Thing Name of the Shadow this device is associated with #defineAWS_IOT_ROOT_CA_FILENAME"root-ca.pem"///< Root CA file name#defineAWS_IOT_CERTIFICATE_FILENAME"1cd9c753bf-certificate.pem.crt"///< device signed certificate file name #defineAWS_IOT_PRIVATE_KEY_FILENAME"1cd9c753bf-private.pem.key"///< Device private key filename
To get it running you edit the config header file, copy your certificates and run make. Then you can run the program and see it connect and do stuff like send messages.
Once you’ve got a connection set up from your application to the IoT API you’re good to go. Kind of. Now that I had a simple C application building with the Axis ACAP SDK and a sample AWS IoT application building on linux, the next step was to combine them into the ultimo baller cloud-based camera software. This was not so easy.
Most of my efforts towards this were spent tweaking the Makefile to pull in the mbedTLS code, aws_iot code and my application code in a setup that would allow cross-compiling and some semblance of incremental building. I had to up my Make game considerably but in the end I was victorious. You can see the full Makefile in all its glory here.
The gist of it is that it performs the following steps:
loads ACAP make definitions (include$(AXIS_TOP_DIR)/tools/build/rules/common.mak)
sets logging level (LOG_FLAGS)
grab all the source and include files/dirs for mbedTLS and aws_iot
define a static library target for all of the aws_iot/mbedTLS code –
produce executable:
The advantage of creating aws-iot.a is that I can quickly build changes to my application source without having to re-link dozens of files.
I combined the Axis logging macros and the aws_iot style logging into one syslog-based system so that I can see the full output when the app is running on the device.
Uploading to the Camera
Once I finally had an ACAP application building I was finally able to try deploying it to a real camera (via make target of course):
Getting the app running on the camera and outputting useful logging took quite a bit of effort. I really ran into a brick wall with certificate verification however. My first problem was getting the certs into the package, which was just a simple config change. But then it began failing. Eventually I realized it was because the clock on the camera was not set correctly. Realizing the importance of a proper config, including NTP, I wrote a script to configure a new camera via the REST API. I wanted it to be as simple as possible to run so I wrote it without requiring any third party libraries. It also shares the package uploader config for the camera IP and password so if you’ve already entered it you don’t need to again.
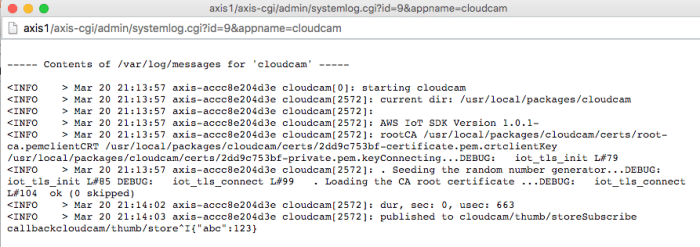
With NTP configured at least there are no more certificate expired errors. I’m able to connect just fine on normal x86 linux, but fails to verify the certs when running on the camera. After asking support, they suggest recompiling mbedTLS with -O0 (disable optimizations) when building on ARM. After doing so, it connects and works!
🌭🍕🍔 !!!!! Success!
To summarize; at this point we now have an embedded ARM camera device that is able to connect and communicate with the AWS IoT API securely. We can send and receive messages and device shadow states.
So what’s next? Now we need a service for the camera to talk to.







 Recently beautiful South San Francisco hosted the annual Silicon Valley PostgreSQL conference, a gathering of the world’s top open-source database nerds.
Recently beautiful South San Francisco hosted the annual Silicon Valley PostgreSQL conference, a gathering of the world’s top open-source database nerds.