This is the first part of a series on serverless development with Python. Next part.
Serverless applications are great from the perspective of a developer – no infrastructure to manage, automatically scaling to meet requests without ever having to think about it, pay by the RAM gigabyte/second, and the ability to deploy via code however you desire. Logging comes free. For DevOps folks it’s a nightmare, as it represents the rapidly approaching obsolescence of their skills involving setting up web servers, load balancing, monitoring, logging, hanging out in datacenters, and other such quaint aspects of deploying web applications. Making a traditional web application run on AWS Lambda is not quite trivial yet, but is well worth understanding and considering next time you need a web service somewhere and it will surely get smoother and easier with time.
Oh yeah, what’s serverless mean here? It means you don’t manage any servers or long-lived processes. You put code in the cloud, and you run it whenever you want, however much you want, and don’t have to worry about the scaling part, while paying for only the CPU, memory, network traffic, and other services you consume. It’s a completely different way of deploying an application compared to managing daemons and servers and infrastructure and load balancing and all fun stuff that has very little to do with the code you want to write and deploy.
Python And Flask
There’s no shortage of options for web frameworks, and you can do a lot worse than Python 3 with Flask. Flask is a nice mixture of being able to create a simple web service with very little boilerplate, but also can also be used as a component for building more complex web applications, with the caveat that it’s more suited to APIs rather than server-side rendered apps when compared with something like Django. You should probably be writing single-page apps these days anyway.
Python is a very well-supported, readable, maintainable language with a vast amount of libraries available on the python module index. If you take the time to set up lint with mypy and flake8 you can even have some up-front checking of types and common mistakes. And it’s supported by AWS Lambda.
What A Serverless Flask Application Looks Like
To build a serverless Lambda application you should have a CloudFormation configuration template that describes your architecture.
The Lambda itself is one piece of this architecture; it is a function that can be invoked and can return a result. To use it as a web service, there needs to be a way to reach it from the web. AWS provides the API Gateway service which can listen for HTTP(S) requests on an endpoint and do something when requested. APIGW can either have an entry for each endpoint you desire (POST /api/foo, GET /api/bar, etc…) or it can proxy any request at a given host and path prefix to a Lambda and then interpret the response as an HTTP response to send back to the requestor. In this way it works like CGI or WSGI, and as long as your web framework knows how to deserialize an API Gateway proxy request and then serialize the response back into the format the APIGW expects, it can appear as any other web application “container” to your app.
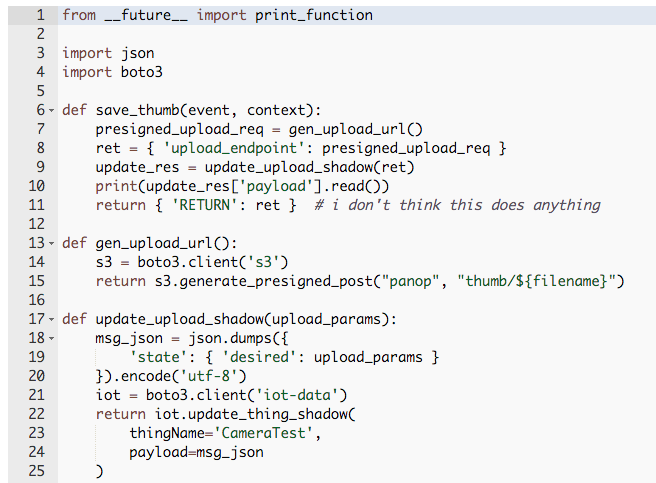
There is a very simple Flask extension for this – AWSGI. The example there shows everything you need to do to make a web application that runs as a serverless app:

The only thing that is really Lambda-specific is the lambda_handler, which gives Flask the WSGI request object it expects and then translates the response appropriately into the format AWSGI expects.
So between the Lambda hosting your application code and the API Gateway acting as its reverse proxy, your infrastructure is pretty clear at this point. There are some associated bits needed like IAM permissions and the like, and maybe a database or S3 bucket or whatever else your app requires. This can all be specified in the CloudFormation template.
AWS has CloudFormation “transforms” that simplify this configuration by providing templated resources for your template to use. Templates on templates is a truly auspicious way to declare configuration. You will harness more slack than you had previously dreamed possible.
Resources:
HelloWorldFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: hello_world/build/
Handler: app.lambda_handler
Runtime: python3.6
Events:
HelloWorld:
Type: Api
Properties:
Path: /hello
Method: get
This gives you a Lambda that runs code uploaded to a S3 bucket when invoked at /hello.
Deployment
Deployment is not yet quite as smooth as say, deploying your application to Heroku, but it is getting there. There do exist some popular tools for doing serverless orchestration like Serverless Framework but I’ve been trying to see how far I can get just using AWS’s native tooling.
AWS has a service that I think no one but myself has actually used called CodeStar. This sets up a serverless deployment pipeline for you automatically, configuring CodePipeline, CodeBuild, and CloudFormation to give you an entire CI/CD system. You can easily configure it to run a build every time you check something into a GitHub repo, and update a CloudFormation deployment automatically. In addition, it even has another level of template laziness in the form of the CodeStar CloudFormation transform.
The documentation on CodeStar and the transform is more or less non-existent, which makes it actually kind of a special challenge to use. However it does appear to take care of the step of uploading your code to an S3 bucket and providing some roles. Your CodeStar template.yml may look something like:
Flask:
Type: AWS::Serverless::Function
Properties:
Timeout: 10
Handler: myapp/index.lambda_handler
Runtime: python3.6
Role:
Fn::ImportValue:
!Join ['-', [!Ref 'ProjectId', !Ref 'AWS::Region', 'LambdaTrustRole']]
If you create a repository with the file myapp/index.py, with a lambda_handler function like the AWSGI handler previously shown, then you now have a serverless web application that will be updated every time you push to your GitHub repo and CodeBuild passes.
Note that CodeStar may have the potential to make developing serverless applications as easy as Heroku with the power of everything you get from AWS and CloudFormation, but it definitely feels today like something no one has actually tried to use. I attempted to add an IAM role to my Lambda function and I managed to stump AWS support. They finally admitted to me that there is no documented way to customize the IAM role:
“After some further testing and research into this I found that you cannot currently customize the serverless Lambda function’s IAM Role from the template.yml.
Instead, you will need to manually add the desired permissions to the IAM Role directly. As you pointed out though, the Lambda function’s role is created automatically and you do not have insight into how to identify the IAM Role being used.”
There is a workaround involving deducing how the role name is derived in the CodeStar transform (which is a rather opaque and mystical bit of machinery) and adding permissions to it, but as far as I’m aware none of this is really supported or documented. They said they plan to fix it though.
You absolutely do not have to use CodeStar for deploying Lambdas, but if you relish a little bit of a challenge with some of the more esoteric AWS services it can be a valuable tool depending on your needs. There’s always some satisfaction at watching unloved AWS services grow and mature over the years (CodeDeploy…) and you can tell war stories about arguing with AWS support reps for months on a single ticket.
Speaking of which, when I tried using CodeBuild for running tests for my project they didn’t have a python 3.6 image, making that tool completely useless. Looks like they have one now though, so maybe not useless anymore.
Other Deployment Options
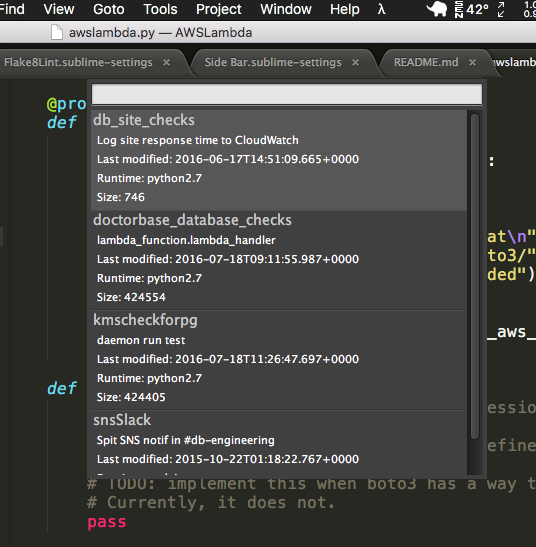
If you really just want to whip up a quick Lambda, you really don’t need a whole CI/CD system or CloudFormation of course. If you just want to write some code and run it and then not worry about it anymore, you can set it all up manually as a one-off function. I do this for some things like Slack bots and random little web services. I use Sublime Text 3 with an AWS Lambda editor plugin that I made. It lets you edit a Lambda directly from within Sublime, and uploads a new version whenever you hit save. It lets you invoke it and view the output within Sublime, and it has a handy shortcut for adding dependencies via pip to your project. It’s incredibly simple and vastly superior to using the web-based function editor, or unzipping and rezipping your bundle every time you want to modify the code.
Dependencies

Your Lambda is actually just distributed as a zip file of a directory. Into this directory goes your application code as well as any data files or dependencies it needs, along with your hopes and dreams. If you depend on other libraries (besides boto3, which Lambda already has for your convenience), you need to include them.
For a simple deployment, you can copy in libraries installed into a virtualenv for your project. If the libraries include native code, you must compile it on a linux amd64 machine because that’s what Lambda runs on. Some tools automate this with docker.
If you want something a little more friendly to use, you can set up a directory to stuff things in.
For my project, I made a dumb little “local pip” script that I can use to install packages with pip into a directory (“vendor/”). It’s nothing special or fancy. Just runs “pip install -t …” and deletes some unnecessary files afterwards.
In my application’s __init__.py file at the top I add vendor and the root path to PYTHONPATH, sort of giving me a mini-venv where I can just use any module installed to vendor/:
import os import sys vendor_path = os.path.abspath(os.path.join(__file__, '..', '..', 'vendor')) lib_path = os.path.abspath(os.path.join(__file__, '..', '..')) sys.path.append(lib_path) sys.path.append(vendor_path) from flask import Flask ...
And then any dependencies I package up can be imported easily.
Putting It Together
To experiment with CodeStar and serverless Flask I made a simple web application. It lets people ask a question or answer a question. It was created initially as a Slack app, although that didn’t quite go as I hoped.
An Aside: My goal was to allow anyone on Slack to receive the questions and answer them, but as I had it only hooked up to a Slack team full of trolls and degenerates the Slack app reviewer was extremely unimpressed with the quality and thoughtfulness of the responses he got when testing it. Which is entirely my fault, but whatever. It’s still available on the Slack app repository but since they wouldn’t permit it to work across teams (something about not being “appropriate for the workplace”?) the Slack interface is of limited usefulness.
Anywhoozlebee, the application is a simple one: allow users to ask questions, or respond to questions. It was implemented first as a web service compatible with the Slack webhooks and Slashcommand HTTP APIs, and then later as a REST API for the web.
If this was a serious project I would use PostgreSQL for a database, but in addition to trying to teach myself how to best design a serverless Flask application, I also wanted to spend as little money as possible hosting it. Unfortunately PostgreSQL is not exactly serverless at this point in time, and you can expect to spend at least tens of dollars a month on AWS if you want a PostgreSQL server on anything except a free tier micro EC2 instance. So I decided to try using AWS’s DynamoDB nosql… thing. It’s a pretty unpleasant key-value store and the boto3 documentation is written by a sadist, but it is cheap and can also scale a lot without having to care much. In theory anyway. Though apparently it sucks?
DynamoDB costs a few bucks a month for tables and indexes, although you can probably get by with one or two if you don’t try to do things like you would in a relational database. Between that and a million requests and 400,000 GB-seconds of compute time a month for free for Lambda, you can have some code run and a place to store data for peanuts. And it should scale horizontally without any effort or thought. I’m sure it’s not that simple in reality, but it’s nice to imagine. At least I never have to configure a webserver or administer a machine just to deploy a web application, and can do it on the (hella) cheap. One of the real values of serverless applications is the ability to just set something up once and then never worry about it again. If it works the first time, it’ll keep working. You don’t need to worry about disks dying or backups or dealing with traffic spikes or downtime. Sure AWS isn’t absolutely perfect but I sure trust them to keep my lambdas running day and night more than I trust most people, including myself. Especially including myself.
Secrets
With any application deployment, you will likely need to store some secrets. You don’t need to give your Lambda an AWS API key as it is invoked with an IAM role that you can grant access to the services it needs. For external services, you can use the AWS SSM Parameter Store. It just lets you store secrets and retrieve them if your role or user is granted permissions to read them. It’s a great place to store things like API keys and tokens.
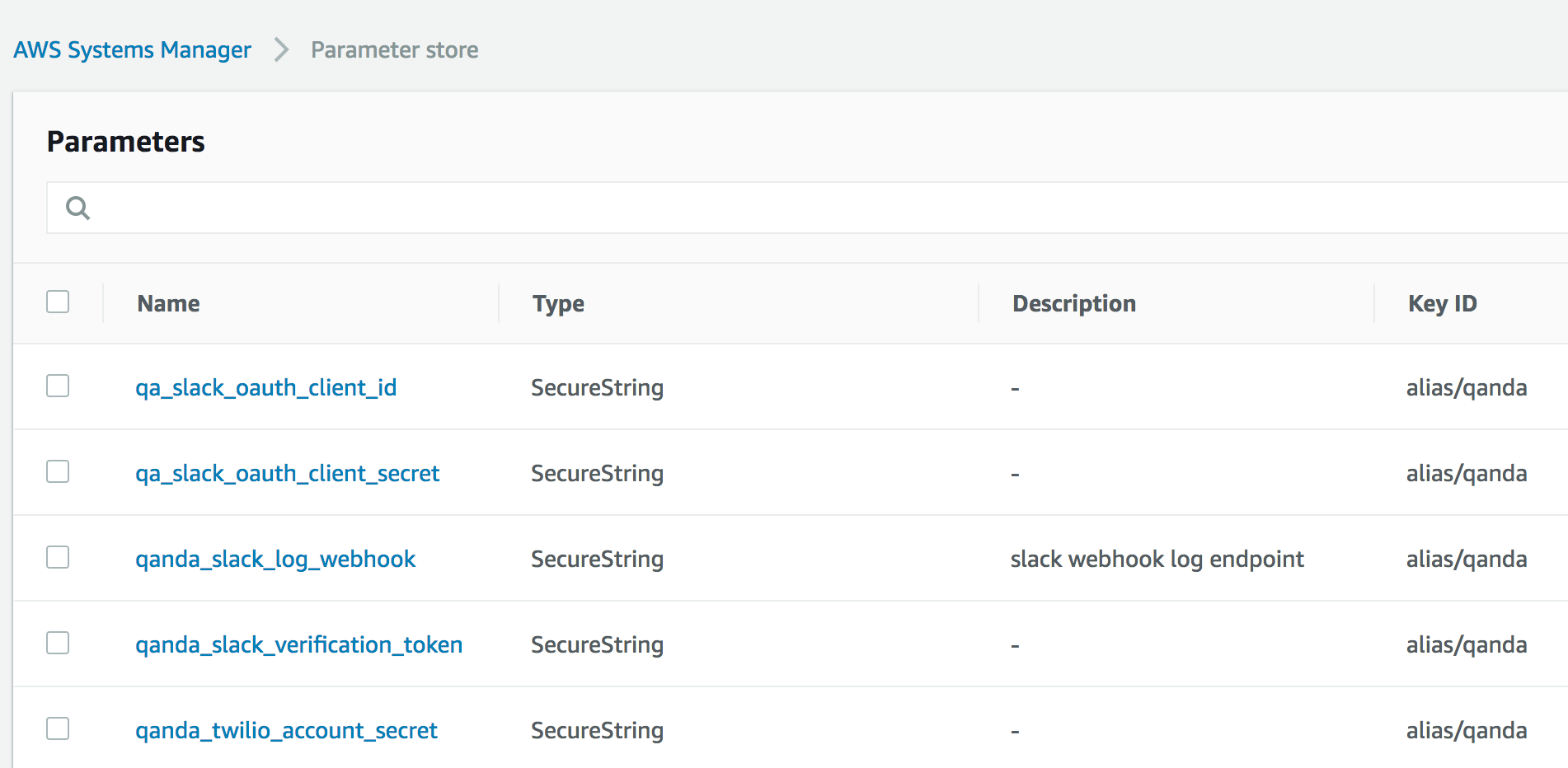
Since we’re using Flask, we can easily integrate SSM Parameter Store with the Flask config.py:
import boto3
ssm = boto3.client('ssm')
def get_ssm_param(param_name: str, required: bool = True) -> str:
"""Get an encrypted AWS Systems Manger secret."""
response = ssm.get_parameters(
Names=[param_name],
WithDecryption=True,
)
if not response['Parameters'] or not response['Parameters'][0] or not response['Parameters'][0]['Value']:
if not required:
return None
raise Exception(
f"Configuration error: missing AWS SSM parameter: {param_name}")
return response['Parameters'][0]['Value']
TWILIO_API_SID = get_ssm_param('qanda_twilio_account_sid')
TWILIO_API_SECRET = get_ssm_param('qanda_twilio_account_secret')
SLACK_OAUTH_CLIENT_ID = get_ssm_param('qa_slack_oauth_client_id')
SLACK_OAUTH_CLIENT_SECRET = get_ssm_param('qa_slack_oauth_client_secret')
SLACK_VERIFICATION_TOKEN = get_ssm_param('qanda_slack_verification_token')
SLACK_LOG_ENDPOINT = get_ssm_param('qanda_slack_log_webhook', required=False)
Secrets status: secreted.
Running Locally
Because Lambdas run inside of AWS, you might think that it would be very cumbersome to have to deploy and test every code change you make using AWS. And that would suck, if you actually had to do that. There’s an AWS project called SAM-CLI – Serverless Application Model Command Line Interface. Using docker Lambda images, you can invoke your application within the same environment it would be running under on Lambda. You can either feed it a JSON file describing a Lambda request and view the response, or you can start it up as a server that you can connect to like any other local development webserver. You do have to provide an AWS API key though if you want your app to make use of AWS services, as it’s running on your local machine and not under the auspices of an instance role in AWS.
Further Examples
In summary the above are considerations that are necessary for creating and deploying a serverless web application. I’m pretty pleased with the way everything fit together in my learning project QandA and I invite you to look at the project structure and source code for a complete working example. There are some more details I could go into about how I structured the Flask application, but they aren’t really Lambda- or serverless-specific and if you’re interested, really just check out the code.

Lambda is still in the early days and far from mature, and not yet as easy to work with as Heroku. But there is a high upside to being able to just have “code running in the cloud” without having to think about it or manage any server, and for basically free. Once you’ve taken the small amount of effort to set up a serverless application, you’re rewarded with an easy way to run code on the internet without having to worry about anything below the level of “request -> application code -> response”. I prefer worrying about code and configuration files over managing infrastructure and servers.