Click here to read the English version of this article.
Изучать русский язык – изучать исключения и ненужную сложность.
Когда студент начинает учить язык, первое слово – «Здравствуйте!»
И сразу же он знает, что не будет легко. Чтобы просто сказать “hello” нужно пять слогов, и постоянно хочется найти недостающие гласные, как будто их не хватает. Как произносить “здр-”? Это очень пугающее начало, и дальше только труднее.
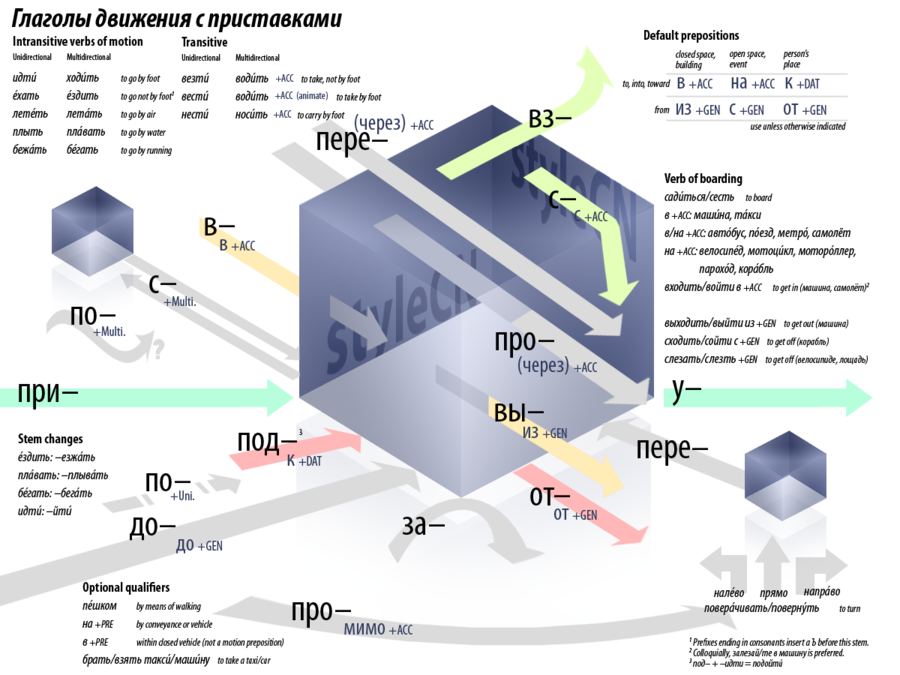
Например, когда человек хочет сказать о идти куда-то, ему нужно учитывать или “идти” это одно место или много мест – ”идти” или ходить – пешком или на колесном транспорте (ехать/ездить), “в” или “под” или “у” или “из” (уйти, выйти, прийти, …), и если совершенный или несовершенный вид (“пойти”), или на самолёте или на корабле.
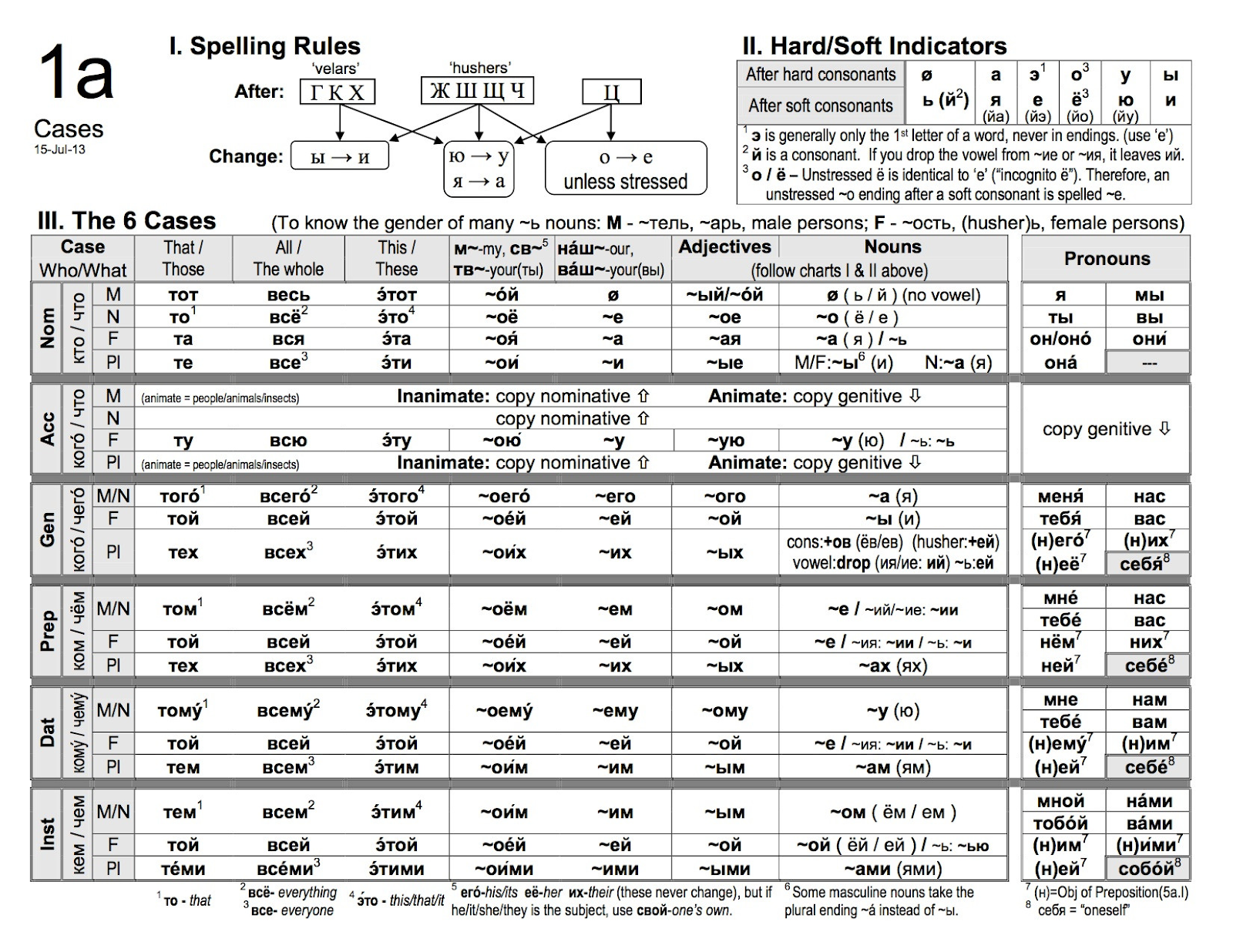
После того как студент выучил “идти”, он может выучить как использовать существительные “на каждый день”. В отличие от английского, у русских существительных есть падежи. Есть простые правила, как например винительный падеж – ”я читаю книгу.” Окей, есть три рода, и это не так трудно, например окончания слов в мужском и среднем родах похожи, но когда студент изучает дальше, у него возникают сложности побольше .
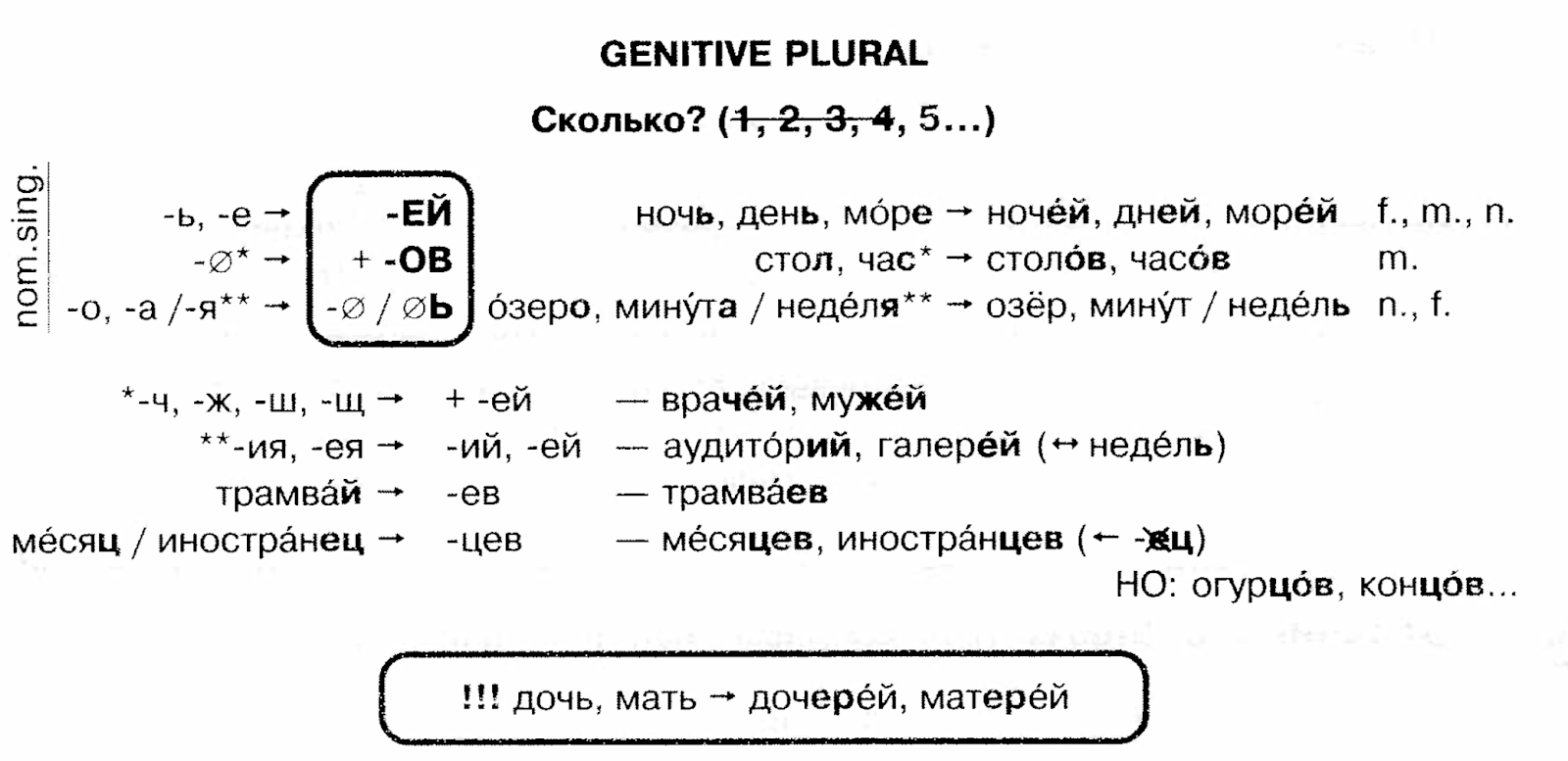
Родительный падеж (кого?/чего?) – проклятие каждого изучающего русский язык. Родительный падеж был аблатив падежом давным давно, но сейчас они оба – только родительный. Поэтому, он используется во многих случаях. Когда чего-то нет, родительный падеж – ”нет книги.” Когда считаете, родительный падеж – ”12 стульев.” Образовывать множественные существительные в родительном падеже – возможно самое сложное в русском языке. Студенты русского практикуют это часто.
Форма родительного падежа тоже появляется когда используется одушевлённый объект в винительном падеже (только если мужской) – ”Я вижу коня”, а когда неодушевлённый объект – “Я вижу дом”, и тоже самое с числами два-четыре – ”Я вижу три вилки.”
Использовать числа тоже очень сложно. Они склоняются конечно, а также сохраняют свои архаичные двойсвестние формы из старославянского языка для чисел 2-4. Когда несчастный студент хочет сказать о количествах, ему обязательно нужно думать или число заканчивается на один, два, три, четыре, или больше.
Пять и т.д. стульев – (форм множественного родительного)
Дальше, «двенадцать стульев» но «двадцать один стул». Ой вей.
И если бы хотел говорить о собирательных числительных, также используют множественный родительный даже для чисел 2-4: «двое друзей». Смотрите ещё больше сложностей здесь.
Русская орфография и фонология менее трудна, немного исключений для носителей английского языка. Буквы <Ы> (делается из «ъ + і») и её звука /ɨ/ нет в английском языке. Трудно произносить, и слышать разницу между <И> и <Ы>, так же как и между <Ш> и <Щ>. Мягкий знак <Ь> и твёрдый знак <Ъ> просто сбивают с толку. А буква <Ё> часто пишется как <Е>, интересно, что людей которые пишут её правильно называют ёфикаторами.
Кириллица – алфавит назван в честь Кирилла и Мефодия главным образом состоит из Греческого алфавита, с немногими символами из Глаголицы «Аз Буки Веди» представляющими звуки, которых нет в Греческом алфавите (как <Ш>). Носители русского языка не верят мне, когда я говорю русский алфавит – это почти всё из Греческого алфавита. Ещё я покажу эту таблицу.
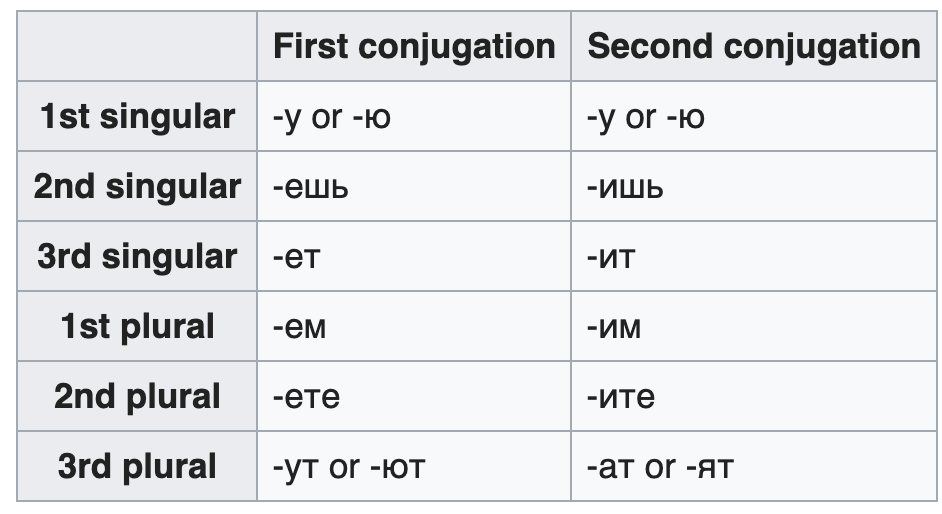
Некоторые вещи легче в русском языке чем у большинства индоевропейских языков. Например глаголы. Спряжение глагола обычно регулярное, и только одна основная форма, это легко запомнить.
Так же глаголов только три времени (прошлое, настоящее, будущее), реже используемые деепричастия, а наиболее совершенные глаголы формируются префиксами (писать ⇾ написать).
А много слов таких же как и в романском, немецком, латинском и английском языках. Немного примеров:
Есть – как “est” на латином (to be)
Ярмарка – как “jahr” на немецком
Проект – как “projekt” на немецком
Бровь – “brow”
Бить – “beat”
Быть – “be”
Ложь – “lie”
Носок – “sock”
Щека – “cheek”
Пламя, плыть, плот, полёт – (flame, fleet, float, flight) – общий индоевропейский сдвиг из /ф/ от /п/ (c.f. Lat. “pater” ⇾ “father”)
О мате, я знаю мало. Не понимаю русские ругательства – это так сложно. В английском языке ругательства не очень сильные или оскорбительные, но люди советуют мне не говорить эти слова на русском. На самом деле в английской Википедии – ”In modern Russia, the use of mat is censored in the media and the use of mat in public constitutes petty hooliganism, a form of disorderly conduct, punishable under article 20.1.1 of the Offences Code of Russia.” Мало информации в английской Википедии о мате, но в русской Википедии – длинная статья, которую я не могу понять и Гугл Перевод не помогает.
Изучать русский язык – это приключение и довольно не быстро. С практикой, возможно обращаться к людям, но сложнее понимать когда они отвечают. Если я читаю со словарём или кто-то говорит медленно, я могу понять много. Говори со мной и помогай мне учить!
WebSockets, the standard for doing real-time bidirectional communication typically between a browser and a server, is a fair attempt to create a standard to supplant the previously employed hacky solutions and continues to evolve in terms of implementation.
The basic idea has primarily been to establish some sort of channel in which a server can “push” events to a client, rather than the client “polling” every so often to see if there is new information. This was until fairly recently a relatively obscure concept, but now any smartphone owner is extremely well-acquainted with push notifications. This real-time channel has been used for not just notifications but also services like VOIP and gaming.
In the days before the WebSocket standard various semi-clever attempts to implement push notifications were devised. The first was using <iframe>s to load an HTML document using chunked encoding, where the server would write a script tag with some new data in the form of JavaScript commands when the data became available. When the browser encountered a closing script tag it would execute the JS immediately even though the document was still streaming.
The next scheme was using XML HTTP Request (aka XHR [aka AJAX]) to do something similar but without needing an <iframe>. This was known as “long-polling”, or “comet.” This was still mostly a unidirectional channel and suffered from timeouts and reconnection issues with potential race conditions.
Now with WebSockets we have a much improved system and wide browser support. But what about the backend? What happens when a browser or other client connects to a WebSocket server?
Previously we’ve developed and hosted WebSocket servers written in Perl, Go, and Python, using PostgreSQL asynchronous events as the message passing system. Deploying WebSocket servers is not as straightforward as HTTP servers because of the long-lived connections and having to perform TCP load balancing. Depending on your hosting setup you may have to deal with internal timeouts or getting events from your message bus to the right backend via some subscription mechanism.
Architecture
Since I love not running servers I’ve been excited about the chance to use serverless WebSockets via AWS API Gateway. In this new scheme you define Lambda functions that react to events such as authentication, connect, disconnect, and user-defined events that can be read from JSON message bodies.
Infrastructure-wise the setup is extremely basic. All of the real work to handle authorization and events and done in code, which we will look at shortly. Let’s use a concrete example of a typical WebSocket use case – sending notifications from the server to the client to inform it of some data change in order for the client to update some information in real time or notify the user.
For my application I created an authorizer function that validates a JWT encoded in the WebSocket URL query parameters (there is no good way in a browser to set headers when opening a WebSocket connection). This function denies or grants access to proceed and saves the authenticated user ID in the principalId response field, which is passed along to subsequent event handlers.
Once the authorization check is successful the special $connect route is called if there is a handler defined. In this handler we have the user ID in the invocation event passed along from the authorizer response and we have a connectionId. We save this user ID and connection ID pair in our database so that we can know who is connected and have the ability to send them a notification later on using their connectionId.
The API Gateway makes a best-effort attempt to detect disconnections and invokes the special $disconnect route whereupon our handler removes the connection record from the database.
Putting all of these pieces together with actual working code required me gathering a fair bit of information from different sources and working out the proper request fields and response formats but it all worked out wonderfully in the end. I’d like to share the working code examples for the handlers and some sample client code as well.
The Code
To define your handlers and when they get invoked you need to configure API Gateway to register your authorizer handler and the assorted route handlers. Using the Serverless toolkit this is straightforward and nicely documented. My configuration looks something like:
def authorizer(event, context):
method_arn = event.get("methodArn")
def deny(msg):
return {"message": msg,
"policyDocument": gen_policy(method_arn=method_arn, allow=False)
}
# get access token from query string
query_params = event.get("queryStringParameters")
if not query_params:
return deny("missing queryStringParameters")
if "token" not in query_params:
return deny("missing token in query string")
token = query_params["token"]
if not token:
return deny("empty token")
# decode and verify JWT token
decoded = None
try:
decoded = decode_token(token)
except ExpiredSignatureError:
return deny("Expired token")
identity = decoded.get("identity")
if not identity:
raise Exception("invalid JWT; missing identity")
# allow access
policy = gen_policy(method_arn=method_arn, allow=True)
context = {} # can add more auth context info here if desired
res = {
"principalId": identity,
"policyDocument": policy,
"context": context
}
return res
def gen_policy(method_arn: str, allow: bool):
effect = "Allow" if allow else "Deny"
return {
"Version": "2012-10-17",
"Statement": [{
"Action": "execute-api:Invoke",
"Effect": effect,
"Resource": method_arn
}],
}
This looks for a JWT in the query string and attempts to parse and validate it. If successful then an IAM policy is returned along with the decoded identity ID. The details of the event and policy can be found in the Lambda REQUEST WebSocket authorizer documentation.
If the client is granted Invoke access to the execute-api service then API Gateway will call our $connect route next:
def connect(event, context):
ctx = event.get("requestContext", {})
# get user and connection id
conn_id = ctx.get("connectionId")
auth = ctx.get("authorizer", {})
user_id = auth.get("principalId")
if not user_id:
return make_response(401, "Not authorized")
if not conn_id:
raise Exception("missing connectionId")
# save the connection id/user id pair in DB
WebsocketClient.save_connection(
user_id=user_id,
connection_id=conn_id,
domain_name=ctx["domainName"],
stage=ctx["stage"],
)
db.session.commit()
return make_response(200, "ok")
def make_response(status_code, body):
if not isinstance(body, str):
body = json.dumps(body)
return {"statusCode": status_code, "body": body}
The purpose of this route is to store the user ID and connection ID in the database along with the connection’s domain and stage. We will use this to send our notification to the client.
def send_ws(user_id, message):
"""Push a notification to the user if they have an active websocket connection."""
connections = WebsocketClient \
.query \
.filter_by(user_id=user_id) \
.all()
for conn in connections:
conn.send(message)
And conn.send():
import boto3
import json
from notifier.db import db, Model
from botocore.exceptions import ClientError
class WebsocketClient(Model):
...
def send(self, message):
"""Send a message to an active connection.
:param message: can be anything that is JSON-serializable."""
# get APIGW management client
apigw_mgmt_client = boto3.client(
"apigatewaymanagementapi",
endpoint_url=f"https://{self.domain_name}/{self.stage}",
)
try:
# send message
apigw_mgmt_client.post_to_connection(
Data=json.dumps(message).encode("utf-8"),
ConnectionId=self.connection_id,
)
except ClientError as err:
# gracefully handle case where client is no longer connected
code = int(err.response["Error"]["Code"])
if code == 410:
# client gone, cleanup
db.session.delete(self)
db.session.commit()
return
raise
This is the where the real action happens. When we want to send a message from the server to the client we do it with the PostToConnection call. We need to provide the API Gateway domain and stage for it to construct the URL needed for the API call. Boto is simply doing HTTP requests to interact with the WebSocket connection as documented here. And you can use an HTTP client directly if you like to get connection info, send a message, and close the connection.
For completeness let’s look at handling the $disconnect route:
def disconnect(event, context):
# get connection ID
ctx = event.get("requestContext", {})
conn_id = ctx.get("connectionId")
if not conn_id:
raise Exception("no connection id found")
# delete the connection record from our DB
WebsocketClient.delete_connection(connection_id=conn_id)
db.session.commit()
return make_response(200, "ok")
Client ➞ Server Messages
But wait, there’s more!
Our application is now ready to send notifications to our client, but if we want to be able to receive messages from the client we can support this case as well. We can define custom routes that are matched based on a route key as documented here and here. In practice this means that if API Gateway receives a JSON message it looks for the route name by default in a field called "action" and decides which Lambda to call based on that value. You can also create a $default route to catch any unhandled message if you prefer to do things that way as well.
Client Code
I implemented a basic WebSocket client in TypeScript using the standard WebSocket API. The only special thing it does is append your access token (managed with axios-jwt) to the WebSocket connection URL.
import { refreshTokenIfNeeded } from 'axios-jwt'
export const WEBSOCKET_EVENT = 'onwebsocketmessage'
export class WSEvent extends Event {
message: object
constructor(msg: object) {
super(WEBSOCKET_EVENT)
this.message = msg
}
}
export type WSEventHandler = (ev: WSEvent) => void
export default class WSClient extends EventTarget {
ws: WebSocket | undefined
public isConnected: boolean = false
reconnectTime: number = 1 // time in seconds before reconnect
// connect
public open = async () => {
if (this.ws) {
if (this.ws.readyState === WebSocket.CONNECTING || this.ws.readyState === WebSocket.OPEN)
// already open/opening
return
this.ws.close() // do reconnect
}
// config from create-react-app+dotenv
if (!process.env.REACT_APP_WS_URL) throw new Error('REACT_APP_WS_URL missing')
const host = new URL(process.env.REACT_APP_WS_URL)
// make sure auth token is fresh
// requestRefresh defined elsewhere - see axios-jwt documentation
const accessToken = await refreshTokenIfNeeded(requestRefresh)
// add auth token to URL
if (accessToken) host.searchParams.set('token', accessToken)
// create new websocket client
if (!this.ws) {
this.ws = new WebSocket(String(host))
this.ws.onopen = this.handleOpen
this.ws.onclose = this.handleClose
this.ws.onmessage = this.handleMessage
}
}
// disconnect
public close = () => {
if (this.ws) this.ws.close()
}
public reconnect() {
if (this.ws) this.ws.close()
this.open()
}
// CALLBACKS
protected handleOpen = (ev: Event) => {
this.isConnected = true
this.reconnectTime = 1 // reset reconnect timer
const ws = this.ws
if (!ws) return
}
protected handleClose = (ev: Event) => {
this.isConnected = false
// do reconnect
setTimeout(() => {
this.reconnectTime *= 2 // exponential backoff
this.open()
}, this.reconnectTime * 1000)
// reconnect?
this.open()
}
protected handleMessage = (ev: MessageEvent) => {
// handle message received on WS
const data = ev.data
if (!data) return
// try to parse as JSON
const msg = JSON.parse(data)
// create new websocket event and dispatch it to listeners
const msgEvt = new WSEvent(msg)
this.dispatchEvent(msgEvt)
}
}
And as a bonus here’s a React hook that lets you register an event handler for WebSocket messages:
import * as React from 'react'
import WSClient, { WEBSOCKET_EVENT, WSEvent } from './api'
// singleton
let client: WSClient
interface IUseWebSocketClientArgs {
onEvent?: (evt: WSEvent) => void
}
const useWebSocketClient = ({ onEvent }: IUseWebSocketClientArgs) => {
React.useEffect(() => {
if (!client) client = new WSClient()
// listen for events
if (onEvent) client.addEventListener(WEBSOCKET_EVENT, onEvent as EventListener)
// ensure client is connected
client.open()
// cleanup handler
return () => {
if (onEvent) client.removeEventListener(WEBSOCKET_EVENT, onEvent as EventListener)
}
})
return { client }
}
export default useWebSocketClient
Conclusion
Like many other serverless technologies this approach is certainly not practical for every use case but it is quite reasonable for a lot of common cases. While API Gateway WebSockets kind of support binary data payloads the serverless approach is probably best suited to your application if you’re passing occasional JSON messages around and dealing with relatively low throughput and volume.
At JetBridge we enjoy developing software applications with our clients that we can take pride in while expanding our areas of knowledge and expertise at the same time. Because we are frequently starting on new projects we have standardized on a harmonious and expressive set of tools and libraries and frameworks to help us rapidly lift off new applications and deliver as much value as we can with minimal repetition.
Our setup isn’t perfect or the end-all stack for every project, but it’s something we’ve evolved over years and it works quite well for us. We continue to learn about new tools and techniques and evolve our workflow so consider this more of a snapshot in time. If you aren’t reading this in July of 2019 then we have probably modified at least some parts of the stack.
Methodology
Our theory of software development is: don’t overcomplicate things.
Pragmatism and business value are the overriding concerns, not the latest and coolest and hippest frameworks or tech. We love playing with new cool stuff as much as any geek but we don’t believe in using something new just for the sake of being new or feeling unhip. Maturity and support should factor into deciding on a library or framework to base your application on, as should maintainability, community, available documentation and support, and of course what actual value it brings for us and our clients.
There is a tendency a lot of engineers have to make software more complex than it needs to be. To use non-standard tools when widely available and known tools exist that might already do the job. To try to shoehorn some neat piece of tech someone read about on Hacker News into something it isn’t really suited for. To depend on extra external services when there are already existing services that can be extended to perform the desired task. Using something too low-level when more abstraction would really simplify things, or using something too fancy and complicated when a simple system-level tool or language would accomplish things more expediently.
Simplicity is a strategy that when used wisely can greatly increase your code readability and maintainability, as well as result in easy to manage operational environments.
Frontend
By the time I am writing this all frameworks and libraries we use have likely been superseded by cool new hip JS jams and you will sneer at our unfashionable choices. Nevertheless, this is what is working well for us today:
React: Vue may have more stars on GitHub but React is still the standard and is used and supported actively by Facebook, among others. Writing apps with React hooks really feels like we are getting closer and closer to functional programming, adding a new level of composibility and code reuse that was clumsily achieved with HOCs before.
Material-UI for React is a toolkit that has almost every sort of widget and utility you might need, powerful theming and styling options, integrates CSS-in-JS very smoothly and looks solid out of the box. It is essentially an implementation of the UI paradigms promulgated by Google so working within its constraints and visual language gives you a reasonable starting point.
Create-React-App/react-scripts: This really does everything you need and configures your new React app with sane defaults. You never need to monkey around with Webpack or HMR again. We have extended CRA/r-s to spit out new frontend projects with extra ESlint and prettier options and Storybook.
Storybook: We prefer to build a component library of small and larger components implemented in isolation using mock data, rather than always coding and testing the layout and design inside the complete app. This allows UI devs to work without being blocked on completion of backend endpoints, helps to enforce the concept of reusable and self-contained components, and lets us preview the various interface states easily.
TypeScript: Everyone uses TypeScript now because it’s good and you should too. It does take some getting used to and learning how to use it properly with React and Redux requires some small amount of learning, but it’s entirely worth it. Remember: you should never need to use any. And when you think you need to use any – you probably just need to add a type argument (generic).
ESLint: ESlint works great with TypeScript now! Don’t forget to set extends: ['plugin:@typescript-eslint/recommended', 'plugin:react/recommended', 'react-app']
Prettier: Set up your editor to run Prettier on your code when you hit save. Not only does it enforce a consistent style, but it also means you can be way way lazier about formatting your code. Less typing but better formatting.
Redux: Redux is nice… I guess. You do need some central place to store your user authentication info and stuff like that, and redux-persist is super handy. In the spirit of keeping things simple though, really ask yourself if you need redux for what you’re doing. Maybe you do, or maybe you can just use a hook or state instead. Sure maybe you think at first that you want to cache some API response in redux, but if you start adding server-side filtering or search or sorting, then it really is better off just as a simple API request inside your component.
Async/await: Stop using the Promise API! Catch exceptions in your UI components where you can actually present an error to the user rather than in your API layer.
Axios: The HTTP client of choice. We use JWT for authentication and recommend our axios-jwt interceptor module for taking care of token storage, authorization headers, and refresh.
Cypress: A popular tool for writing end-to-end tests. Cypress makes it easy to mock API responses and fully test your application as an automated web browser, either headless or used interactively. Can record videos and screenshots of every state and step of your tests to review what your UI looks like and how it reacts even after automated test runs.
I don’t believe there’s anything crazy or unusual here and that’s sort of the point. Stick with what’s standard unless you have a good reason not to.
Backend
Our backend services are always designed around the 12-factor app principles and always built to be cloud-native and when appropriate, serverless.
Most projects involve setting up your typical REST API, talking to other services, and performing CRUD on a PostgreSQL DB. Our go-to stack is:
Python 3.7. Python is clean, readable, has an impressively massive repository of community modules on PyPI, active core development, and a pretty good balance of high-level dynamic features without getting too obtuse or distracting.
Type annotations and type linting with mypy. Python does have type annotations, but they are very limited, not well integrated, and not usually very useful for catching mistakes. I hope the situation improves because many errors have to be discovered at runtime in Python when compared with languages like TypeScript or Go. This is the biggest drawback to Python in my opinion, but we do our best with mypy.
Flask, a lightweight web application framework. Flask is very nicely suited to building REST APIs, providing just enough structure to your application for handling WSGI, configuration, database connections, reusable API handlers, tracing/debugging (with AWS X-Ray), logging, exception handling, authentication, and flexible URL routing. We don’t lean on Flask for much besides providing the glue to hold everything together in a coherent application without imposing too much overhead or boilerplate.
SQLAlchemy for declarative ORM. Has nice features for handling Postgres dialect features such as UPSERT and JSONB. Ability to compose mixins for model and query classes is very powerful and something we are using more and more for features like soft deletion. Polymorphic subtypes are one of the most interesting SQLAlchemy features, allowing you to define a type discriminator column and instantiate appropriate model subclasses based on its value.
Flask-REST-API with Marshmallow helps succinctly define REST endpoints and serialization and validation with a minimum of boilerplate, making heavy use of decorators for a declarative feel when appropriate. As a bonus it also generates OpenAPI spec documents and comes with Swagger-UI to automatically provide documentation of every API endpoint and its arguments and response shapes without any extra effort required.
We are currently developing Flask-CRUD to further reduce boilerplate in the common cases for CRUD APIs and mandating strict data model access control checks.
In projects that require it we can use Heroku or just EC2 for hosting but all of our recent projects have been straightforward enough to build as serverless applications. You can read about our setup and the benefits this brings us in more detail in this article.
We have built a starter kit that ties together all of our backend pieces together in a powerful template to bootstrap new serverless Flask projects called sls-flask. If you’re thinking of building a database-backed REST API in Python, give it a try! You get a lot of power and flexibility in a small bundle. There isn’t anything particularly special or exotic included in it, but we believe the foundation it provides adds up to an extremely streamlined and modern development toolkit.
All of our tooling and templates are open source, and we often contribute bug reports and fixes upstream to modules that we make use of. We encourage you to try out our stack or let us know what you’re using if you’re happy with what you’re doing. Share and enjoy!
Adding video encoding support to your application is relatively straightforward with Amazon’s Video On Demand encoding pipeline infrastructure template.
This CloudFormation template provides you with:
A S3 media source bucket where video files get uploaded, with an option to phase out media source files to long-term storage in Glacier.
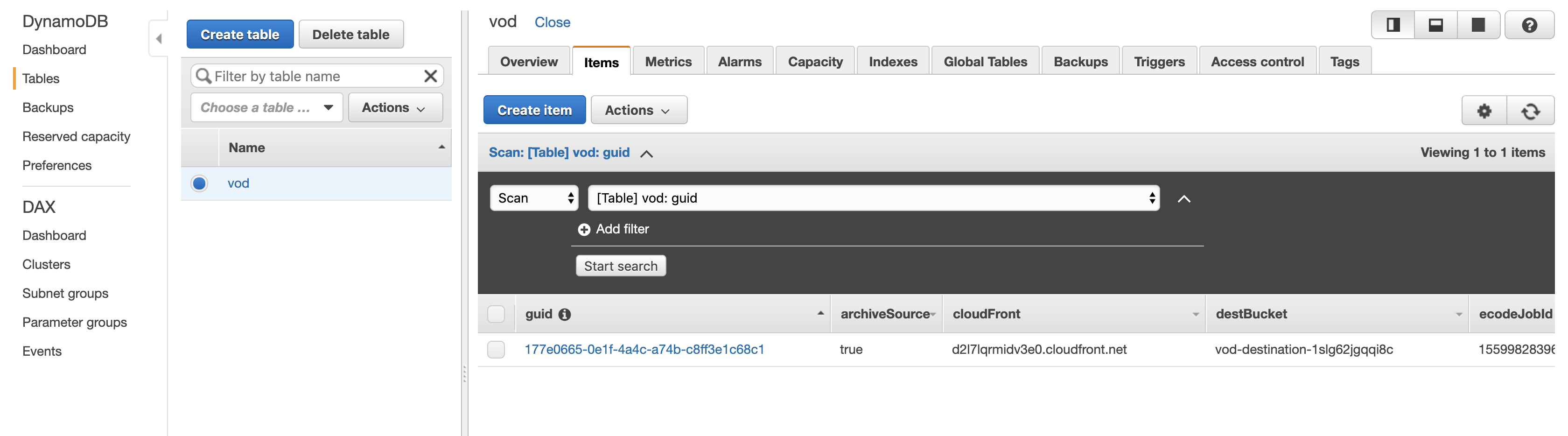
A DynamoDB table to track the status of the encoding and store all metadata about the source and output files.
A series of Step Functions (Lambda state machines) to manage the stages of the pipeline.
MediaConvert to do the actual video encoding work.
An output S3 bucket for the encoded files and playlists, with a CloudFront CDN distribution in front.
A SNS topic which publishes events to subscribers when media ingestion begins and when it completes, as well as if there is an error.
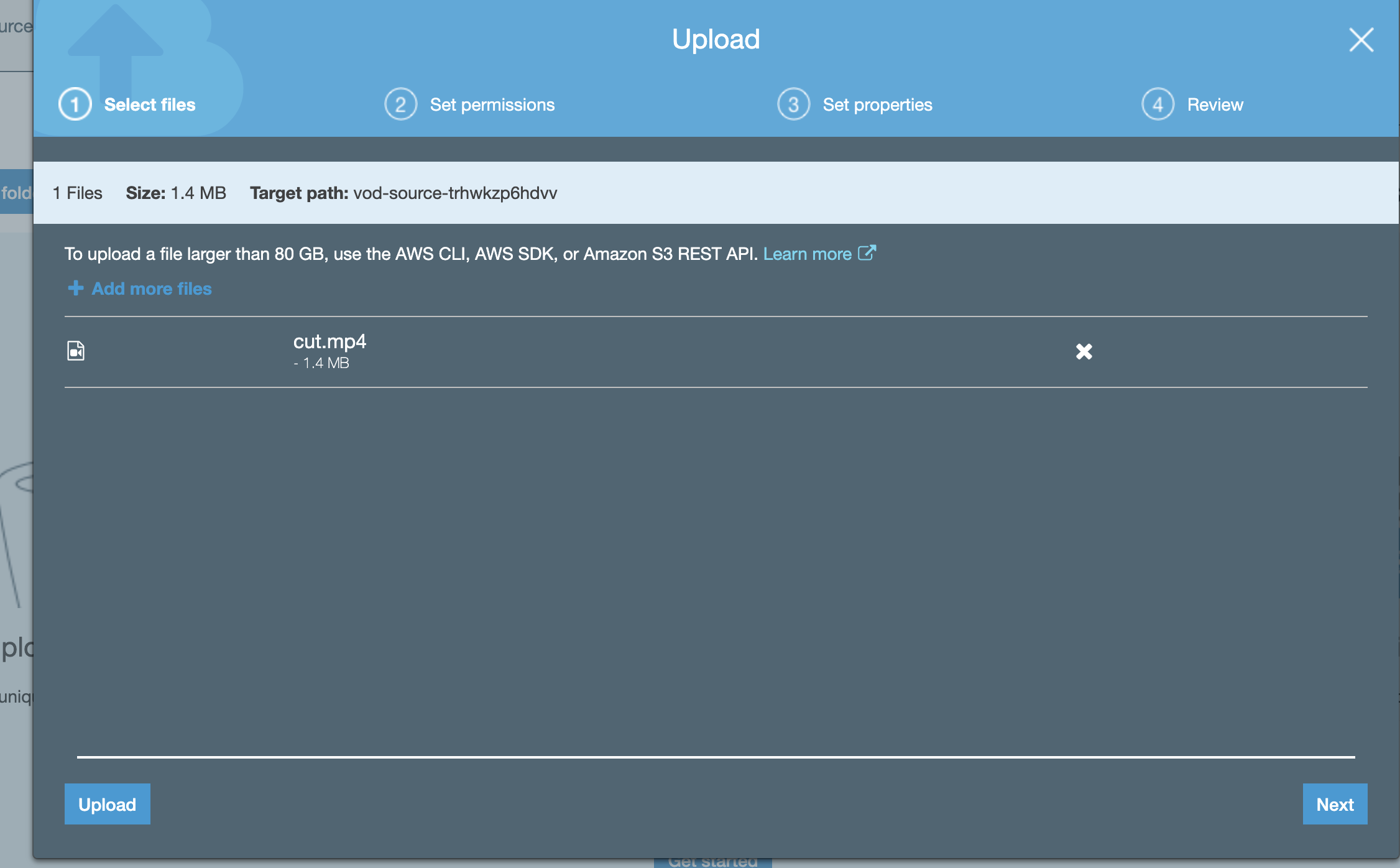
Once the stack has finished launching, you can try uploading a video file into the source S3 bucket.
When files are added to the bucket a Lambda is automatically triggered that begins the ingestion and kicks it over to MediaConvert after generating a GUID to track the progress of the encoding.
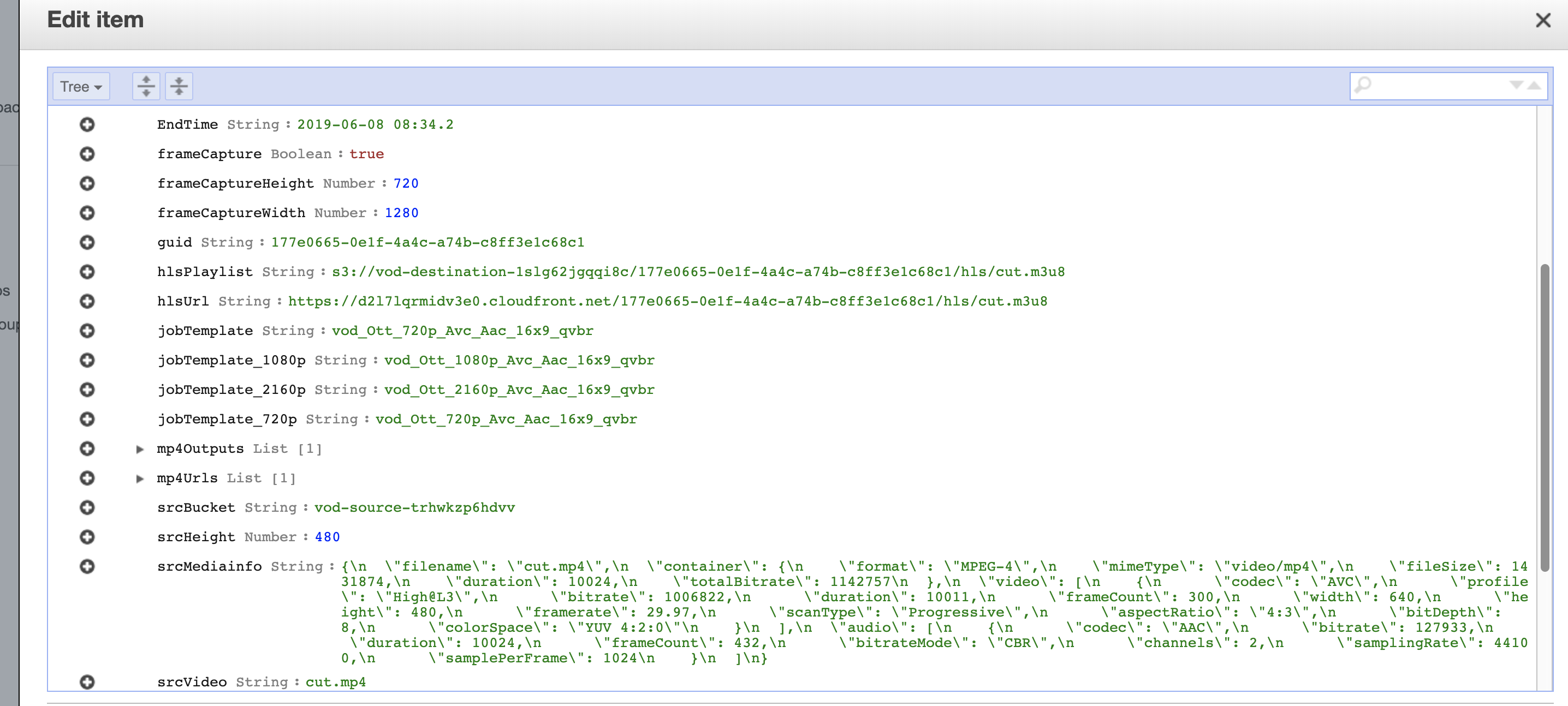
After the encoding is complete you will have an entry in the DynamoDB table with information about the media files and the outputs, including a HLS M3U8 (HTTP Live Streaming MP3 URL UTF-8 playlist) which can be used by any web or mobile client to stream your video at adaptable bitrates.
The resulting output.
Integrating To Your Application
The VOD encoder pipeline is a pretty nifty example of how to use ready-made stacks of infrastructure, but what if you want to integrate this pipeline into your application? Let’s look at one way you can accomplish this.
Say you are building a CMS where you want users to be able to upload videos that can be streamed by clients. You will need a user interface for performing the upload and then a way to associate the results with that object when the encoding process completes or errors.
The flow from the application’s perspective will look like this:
Register a Lambda for handling notifications from the VOD SNS topic.
Create an object in your database to store the uploaded video. A row in a video table would suffice just fine. Make up a S3 key for this row (based on the video’s ID or better, UUID) and store it in the video row as well.
Generate a pre-signed S3 PutObject request URL (Python docs) for the media source bucket.
On the browser side, upload the video file to the pre-signed S3 upload URL. Once the upload is complete the Lambda trigger will be automatically invoked, kicking off the encoding job.
Process ingestion notification received from the SNS topic. This notification includes the UUID generated by the pipeline to keep track of your job and the original S3 key of the video file that was just uploaded. Store the VOD task UUID in your video database row associated with the S3 key.
When you receive a completion or error notification from the SNS pipeline, update the video row appropriately. You now have either a HLS playlist URL associated with your video or an error message.
Registering For SNS Notifications
You can set up everything above by hand, but making reusable infrastructure is easier and more powerful. If you are using the Serverless toolkit you can use the SNS topic CloudFormation output (remember the one mentioned above that we had to add to the template?) to register a Lambda to listen for events:
This will invoke the function myapp.handler.vod_sns_update.handler whenever a new message is published on the SNS topic in the CloudFormation stack named vod (that’s what I called it, you can change it if you really want).
Other CloudFormation Stack Outputs
Your application will also need to know the name of the source media S3 bucket to generate the presigned upload request as well as the name of the DynamoDB table to fetch the results from. Again, this example is for Serverless:
This has the effect of passing the source S3 bucket and DynamoDB table names from the VOD stack outputs into your application as environment variables.
S3 Presigned Upload
You can create a URL that you can give to a client to permit it to upload a file to a designated S3 key:
This URL can then be returned to a web browser which can then do a PUT to the URL with the contents of the file as the body of the request.
I recommend generating a S3 key in the form of: f"/video/{video.uuid}/media.mp4"
Processing SNS Notifications
This should be a Lambda handler that looks up the associated video entry in your database and updates it with the status published by the VOD pipeline. Some rough sample code:
import boto3
import os
import json
from myapp.db import db
from myapp.model.video import Video
from enum import Enum, unique
from typing import Optional
import logging
log = logging.getLogger(__name__)
@unique
class EncodingStatus(Enum):
new = "new"
ingest = "Ingest"
complete = "Complete"
error = "Error"
table = os.environ["VOD_TABLE"]
dynamodb = boto3.resource("dynamodb")
table = dynamodb.Table(table)
def handler(event, context):
records = event.get("Records", [])
with app.app_context(): # if you use Flask-SQLAlchemy
for record in records:
log.debug(f"Processing VOD SNS event...")
process_event_record(record)
db.session.commit()
return "ok"
def process_event_record(record: dict):
assert "Sns" in record
assert "Message" in record["Sns"]
message = json.loads(record["Sns"]["Message"])
# look up asset by key/bucket
src_video = message.get("srcVideo")
status = EncodingStatus(message.get("status", message.get("workflowStatus")))
guid = message.get("guid")
log.debug(f"Video: {src_video}, status={status}, guid={guid}")
if not src_video:
# this is missing in case of error
if status == EncodingStatus.error:
video = db.session.query(Video).filter_by(vod_guid=guid).one_or_none()
if not video:
log.warning(f"Got video GUID for unknown video {record}")
else:
video.encoding_status = status
log.warning(f"Got video encoding without video src {record}")
return None
# look up video by S3 key
video = Video.query.filter_by(s3key=src_video).one_or_none()
if not video:
log.warning(f"Could not find video {src_video}")
return None
# update video
video.vod_guid = guid
video.encoding_status = status
video.vod_last_message = message
video.hls_url = message.get("hlsUrl") if message.get("hlsUrl") else video.hls_url
thumbnail_urls = message.get("thumbNailUrl", [])
video.placeholder_url = thumbnail_urls[0] if thumbnail_urls else None
video_data_info = get_video_data_info(guid)
if not video_data_info:
if status == EncodingStatus.complete:
log.warning(f"Could not find data about encoding {record}")
return asset
src_media_info = video_data_info.get("srcMediainfo")
encoding_details = json.loads(src_media_info) if src_media_info else None
if not encoding_details:
log.warning(f"Could not find encoding info {record} // {encoding_details}")
video.duration = encoding_details["container"]["duration"] # ms
print(f"Media info: {src_media_info}")
db.session.commit()
def get_video_data_info(guid: str) -> Optional[dict]:
result = table.get_item(Key={"guid": guid})
return result.get("Item")
Conclusion
And now you have a powerful media encoding pipeline integrated into your application. Some features to note are :
Thumbnail URLs are automatically generated.
Media info is output which contains everything from duration to dimensions to colorspace.
Some modern organizations and institutions including governments now incorporate electronic identities into their normal functions, permitting new forms of digital engagement and interaction.
The technology and concepts are not new but the increasing use of this technology in society is impactful and has much potential. Long-understood cryptographic applications for electronic identity are finally becoming deployed by important institutions and used for social and legal purposes. While not the most effortless and user friendly systems yet, apparent progress is being made and new programs are being invented around them.
What Is Signing?
The main component to this system is your identity which can be linked to the real world or can be purely digital. Your identity is connected to your electronic key which you alone possess. Your key can exist unconnected to anything else as a purely anonymous identity, or it can be “signed” and verified by other identity keys which are in some way recognized as authoritative.
The holder of the “secret” half of their digital identity can electronically sign anything that can be digitally encoded in a computer. The meaning of the signature varies depending on the item they are signing but can have the same legal force as a handwritten signature in some jurisdictions. In addition to signing documents one can use their key to authenticate to online services and encrypt documents only readable by specific people.
Any computer system can verify that the user’s signature corresponds to their public identity, which has been signed by their trusted institution key in turn. The “public” half of the trusted “root” certificate is distributed ahead of time and widely available for any humans or software to verify the validity of a user and confirm their identity as defined by the institution.
Examples Of Uses
A citizen of a government implementing e-ID can use their secret key to sign an electronic document confirming they want to vote for a particular candidate for office over the internet. Or they can sign into their bank account, government websites, private forums, or any other service as their government-verified identity. Participants in an organization can collaborate online using identities that the organization previously has verified to their satisfaction. Such services can be assured of the real-world identity of the user communicating with them over the internet.
None of this necessarily has to take place over the internet; the mechanisms of signing and verification can work offline. The real potential of these systems comes with the ability to participate electronically yet with a verified identity.
The deployment of SSL made it possible for people to trust entering their credit cards on websites, resulting in a massive transformation of the economy. So too is the potential of cryptographically secure identities issued by trusted parties.
Institutions, governments, political parties, cooperatives, and any other type of organization can allow its members to participate remotely with the same assurance of their identity as in person. Voting, citizen input, taxes, banking, document signing, secured websites, smart cities and more applications not yet thought up can all be implemented with e-identity. The possibilities for digital self-organization enabled with this technology are extraordinary.
Traditional ballot-based voting can only be done very infrequently by governments and organizations because of the enormous expense and overhead involved. With e-IDs, polls could be taken as often as desired to maximize representation and participation from the local community level to national or even international levels.
New types of online communities could exist where people would choose between totally anonymous identities or decide to be linked to their real-world identity. A continuum of anonymity would be possible as people could choose how much to use or conceal their verified identity, with other participants taking this into account to weigh the credibility of the speaker. Imagine how polite a web forum comprised of only Canadian citizens speaking with their real identity would be.
The prerequisites to adoption of electronic identity of are the existence of willing governments and institutions and a widespread layperson understanding of how such a system works and can be used.
e-ID In Practice: Estonia
The Estonian government is not only a pioneer in the area of digital identity but also in extending verified identities to non-Estonian residents. The Estonian parliament created law in the year 2000 to give digital signatures the same legal status and handwritten ones and to implement a nationwide public key infrastructure and digital signature program. Their e-ID system is now available to non-Estonians via their e-Residency program.
Anyone at all can apply to get an identity key verified by the Estonian Police and Border Guard for €100. The main idea of the e-Residency program is to make it really easy for foreigners to open businesses and bank accounts in the country, while also building institutional knowledge and proficiency in using electronic identities. It also doesn’t hurt the much-touted tech innovator image of the tiny Baltic country, noted so for developing Skype and more recently Taxify and Transferwise.
In practice this means anyone can obtain a key signed by the Estonian certification centre. After applying and having been approved, you must visit an Estonian embassy in any country and verify your passport and give your fingerprints to get your key. The key comes on a chipped card (it comes with a miniature USB smartcard reader) protected by a PIN code which you can set. There is a sheet of paper with your PINs and another card with a backup reset PIN in case you forget. This is the ideal form of authentication; a combination of something you have (the chip card) and something you know (your PIN). On the card, protected by your PIN, is the secret half of your key. The government-signed public half of your key can be used to register yourself with electronic services and declare your official identity, and the secret half is used to prove that you are who you say you are.
The Friendly Welcome Kit Using The Mini Card Reader
There is software for using your ID card with websites as well as signing and encrypting documents. There are browser extensions and standalone desktop software for macOS and Windows (and tools for Linux). The software is notable in that it is complete with extensive documentation online, is developer-friendly, has tools and services for testing, and is completely open source.
You can digitally sign legal documents as well as encrypt or decrypt files. If you have the personal, company, or registry number of a person or organization you can encrypt files that only they can decrypt without any pre-arranged encryption key. You can also use your card for authentication to websites and services that support it. Fraud is also made much harder compared to more traditional identity verification systems such as those in the US based on social security numbers and credit reports.
How Much Can e-IDs Be Trusted?
It’s up to every person and organization to decide how much trust to put in to the identity features of any given e-ID system. If you decide that you can trust the software you’re using and the root certification authority then you can decide to accept the asserted identity of people electronically.
Put another way, if you trust the verification process of the Estonian Police and Border Guard and you don’t find any issues in the software you’re using to verify identities, then you can be fairly confident that someone presenting an e-ID is exactly who they claim to be. Governments are in a fairly unique position to validate someone’s passport and fingerprints in a controlled environment (like an embassy) and can strongly attest to someone’s real world identity, to the extent that trust that government.
The danger of someone else using your identity card is roughly the same as someone stealing your bank card and withdrawing money from an ATM with it. Someone needs physical access to your card as well as a valid PIN code which can only be tried a few times. There is the possibility that an adversary could steal your backup piece of paper with the PIN reset code on it to defeat the PIN and then sign documents as you or log in to your bank account. However because of the physical access required, this is a vastly safer system than the standard email/password combination used for authentication these days.
The cryptography underlying the system is quite well-understood and has been employed for a long time in other domains. There is an extremely high degree of assurance that one can determine if another party owns the secret part of their identity, that only the recipient of a message encrypted for the recipient can decrypt it, and that the owner of the secret part of their key has signed something with their identity.
This security system like any other is not foolproof; you could get mugged for your ID card and PIN codes leaving the embassy, spyware on your computer or poorly-designed software can compromise the integrity of your ID. People will forget their PIN codes or write them on sticky notes stuck to their cards. People will lose their cards or sign something drunkenly late at night or under duress. Implementation problems can plague the system, as when a supplier of microchips left a theoretically exploitable fatal flaw in a vast quantity of identity documents:
An estimated minimum of 1 billion affected chips are used around the world in a variety of computing devices and on plastic cards. The Infineon chips that led to the vulnerability in the Estonian ID cards are used in driving licences, passports, access cards and elsewhere. The identity documents of at least 10 countries were affected.
Such problems are not altogether unsurprising for rollouts of complex new technology and we can hope that these early issues can be learned from. Many precautions are in place for other anticipated difficulties such as a key revocation process, expiration dates on keys, the backup PIN reset codes, and an open source architecture with reference implementation software that can be reviewed by researchers and the public.
Future Possibilities
e-ID and the underlying technology is something that can be harnessed to enhance the identification measures needed for trustworthy communication and interaction online. It can vastly expand the scope for self-organization and self-government amongst people by enabling digital participation with trusted identities. Completely anonymous yet verifiable interactions are also possible as one can ensure the other person they are communicating with is exactly the same person they have interacted with previously even without knowing any other details about their identity.
Better collaboration is possible for collectives and cooperatives, online communities, local and national governments, businesses, trade groups, and any other sort of organization which can benefit from the fluidity and ease of online interaction with strong form of identity authentication. Types of institutions which had previously been limited by geography can become more virtualized.
Stronger authentication and identity systems, new possibilities for self-organization, and increased easy of civic participation are made possible by architecturally sound, open source, and trustworthy e-ID systems.
Technical notes on interacting with the Estonian e-ID hardware and verifying signatures and identities can be found here.
See this gist to check out more advanced handling with loading the Twilio API key from Secrets Manager, doing lookups with Twilio Add-Ons to detect spam/robocalling, and detailed caller lookup info that is output to a slack channel every call.
One of the many new services re-invented at AWS’s re:invent conference was the storage of secrets for applications. Secrets in essence are generally things your application may need to run but you don’t really want to put in source control. Things like API keys, password salt, database connection strings and the like.
Current ways of providing secrets to applications are things like configuration files deployed separately, Heroku’s config which exposes them as environment variables, HashiCorp Vault, CloudFormation variables, and plenty of other solutions. AWS already had a dedicated mechanism for storing secrets and making them available via an API call in it’s SSM Parameter Store service, in which you could store values, with optional encryption.
AWS Secrets Manager is slightly but not very different from SSM Parameter Store; it adds secret rotation capabilities and isn’t as buried deep down inside the obliquely named “AWS Systems Manager” service. I think those are the main features. Oh it also lets you package a set of key/value pairs into one secret, whereas Param Store makes you create separate values that require individual API calls to retrieve.
Using Secrets With Serverless
To store encrypted secrets in the AWS Secrets Manager and make them available to your serverless application, you need to do the following:
Create a secret in Secrets Manager. Select “Other type of secrets” unless you are storing database connection info, in which case click one of those buttons instead.
Select an encryption key to use. Probably best to create a key per application/stage.
Create key/value pairs for your secrets.
After creating the secret, there will be sample code for different languages that shows you how to read it in in your application.
Encryption Key Access
To create encryption keys, look in IAM (click “Encryption Keys on the bottom left in IAM) and assign admins and users of the keys. I manually assign the lambda role that’s been created as a user of the encryption key it needs access to in the console. There may be a way to automate this but it feels like an appropriate step to have some small manual intervention.
Your lambda’s role will look like $service-$stage-$region-lambdaRole
IAM Role
In addition to granting your lambda role access to decrypt your secret, you also need to grant it the ability to access your secret.:
plugins:
- serverless-python-requirements
- serverless-pseudo-parameters
provider:
name: aws
runtime: python3.7
stage: ${opt:stage, 'dev'} # default to dev if not specified on command-line
iamRoleStatements:
- Effect: Allow
Action: secretsmanager:GetSecretValue
Resource: arn:aws:secretsmanager:#{AWS::Region}:#{AWS::AccountId}:secret:myapp/${self:provider.stage}/*
environment:
LOAD_SECRETS: true
This is taken from my serverless.yml file. Note the secret:myapp/dev/* bit – it’s a good idea to use prefixes in your key names so that you can restrict access to resources by stage (i.e. dev only has access to dev secrets, prod only has access to prod secrets). In general prefixing AWS resources with application/stage identifiers is a crude but readable and simple way to create IAM policies for access groups of related resources.
serverless-pseudo-parameters is a handy plugin that lets you interpolate things like AWS::Region in your configuration so that you don’t need to do an unwieldy CloudFormation Fn::Join array to generate the ARN.
Reading Secrets In Your Application
Now that your application has access to GetSecretValue and is a user of the encryption key used to encrypt your secrets, you need to access the secrets in your application.
Sample code is provided in the Secrets Manager console to read your secret. One thing to note is that if you store key/value pairs in your secret, which is most likely what you’ll want to do almost all the time, you get it back as JSON. The sample code provided doesn’t decode it. The general idea is something like:
And then you can do as you please with the secrets.
App Configuration
I like consuming secrets directly into my application’s configuration at startup. With Flask it looks something like this:
if os.getenv('LOAD_SECRETS'):
# fetch config secrets from Secrets Manager
secret_name = app.config['SECRET_NAME'] # dev, prod
secrets = get_secret(secret_name=secret_name)
if secrets:
log.debug(f"{len(secrets.keys())} secrets loaded")
app.config.update(secrets)
else:
log.debug("Failed to load secrets")
First, only try to load secrets if we’re executing under serverless/lambda. LOAD_SECRETS is defined as true in the serverless.yml snippet above. This should not be true when running tests, as you don’t want tests to access secrets and you don’t want to pay for all the additional accesses anyhow.
SECRET_NAME is in application config and can be different for dev and prod.
app.config.update(secrets) adds whatever you stored in Secrets Manager to your app config.
I should probably make a dumb PyPI module to do this automatically.
In a previous article I discussed how to interact with the serverless AWS Lambda platform using only tools provided by Amazon. This was a valuable experiment that I suggest applying to any new technology or interesting new system you’d like to learn. Start with the basics and try doing a project without too many extra tools or abstractions so that you can get an idea of how the underlying system works and what’s unpleasant or boilerplate-y or requires too much effort. Once you have an idea of how the pieces fit together you can have a much better appreciation for the abstractions that go on top because you understand how they work, what problems they are solving, and what pain they are saving you from.
AWS services are powerful but generally need to be put together in coherent ways to achieve your goals. They’re modules that provide the functionality you need but still require some glue to make a nice developer experience. Fortunately because the entire platform is scriptable, software tools and additional layers of abstraction are rapidly increasing the capabilities of software engineers on their own to manage configuration without the need for any hardware or humans in between. CloudFormation (CF) allows declaration of your infrastructure with JSON or YAML. CF templates like the Serverless and CodeStar transforms make it easier to write less CloudFormation code to describe a serverless configuration. And then tools like the Serverless toolkit add another layer of automation on top of CF and provide a really excellent developer experience. Not to be outdone, Amazon provides an even higher level toolkit called Amplify (subject of a future article) to further increase the leverage of effort to available hardware and software muscle.
Serverless Toolkit
After going through the process of building some toy applications using AWS SAM and the Serverless CF transform, I quickly saw some of the drawbacks of not using a more advanced system to automate things:
Viewing logs. Looking at CloudWatch logs in the AWS Console is not a great way to view the output of your application in real time, or in any time really.
It wasn’t clear to me how to save some pieces of a serverless application architecture for re-use in later projects. I posed a question to the Flask mailing list and IRC channel about how to make an extension based around it and didn’t get a useful response.
Defining stuff like API gateways, S3 buckets for code, and domains in CF is tedious. It can be automated further.
It would be nice to have some information readily available, such as what URL my application is deployed at.
Deployments, including to different stages.
Telling me when a deployment is finished, especially when using CodeStar.
Invoking functions for testing and via automation.
Managing dependencies.
And some other general stuff like keeping track of the correct AWS configuration profile and region.
As happens so often in the field of Computers, I’m not the first one to encounter these issues and some other people have already solved most of the problem for me.
To ensure a steady supply of confusion when discussing the relatively recent trend of serverless application architecture, there exists a collection of tools called Serverless, which resides on serverless.com. This should not be confused with serverless the adjective or the Serverless Application Model (SAM) or the AWS Serverless CF transform.
Every one of the issues mentioned above is simply handled by Serverless. I believe it’d be an unnecessary expenditure of time and effort to continue to develop serverless applications without it, based upon my recent experience trying to do so. Unless you’re just starting out and want to get a feel for the basics first, that is.
I won’t reiterate the Serverless quickstart here, go try it out yourself on their site. It takes very little effort, especially if you already have AWS credentials set up. I will instead talk about what advantages it gives you:
Logging
This is easy. You can view (and tail) the logs for any function with
sls logs -f myfunction -t
Reusability
# immediately create a Flask app based on my template sls install --url https://github.com/revmischa/serverless-flask --name myapp
Some of what people have been doing is going the same route as Create-React-App and creating templates for Serverless projects that can be accessed with “sls install.” On the one hand this does make it very easy to create and share reusable setups and allows for divergence as templates evolve, but it makes it much harder for projects started with older templates to incorporate new refinements. In the realm of Flask and Python, I don’t feel this problem is solved just by templates and some sort of python module that can co-evolve is needed. Something analogous to the react-scripts package that goes along with Create-React-App would likely be the way to go.
Nearly all of the boilerplate CF needed for serverless like a S3 bucket for code, IAM permissions for invoke and CloudWatch, API Gateway, etc are totally hidden from you and you never need to care about them. Only the minimum configuration and CF needed to describe what’s unique about your setup is required from you. On a scale of sendmail.conf to .emacs, serverless.yml is fairly high on the configuration file sublimity scale.
Info
This is easy. Where’d I park my domain again?
$ sls info Service Information service: myapp stage: dev region: eu-central-1 stack: myapp-dev api keys: None endpoints: ANY - https://di1baaanvc.execute-api.eu-central-1.amazonaws.com/dev ANY - https://di1baaanvc.execute-api.eu-central-1.amazonaws.com/dev/{proxy+} GET - https://di1baaanvc.execute-api.eu-central-1.amazonaws.com/dev/openapi functions: app: myapp-dev-app openapi: myapp-dev-openapi Serverless Domain Manager Summary Domain Name myappmyapp.net Distribution Domain Name dcwyw3gslhqw1.cloudfront.net
Deployment
This is easy too! Too easy!
$ sls deploy $ sls deploy -s prod # specify stage
This bundles requirements if needed, packages the service, uploads to S3, and kicks off a CloudFormation stack update.
Notice that sweet Serverless Domain Manager Summary section? That, my friend, is the serverless-domain-manager plugin. If you want your endpoints to be deployed under a domain name you already have in a Route53 zone (and hopefully have an ACM certificate in us-west-1 to go with it) you can have Serverless automatically fire up the domain or subdomain for you along with a CloudFront distribution and API Gateway domain mapping.
I discovered an issue with the domain manager plugin selecting the ACM certificate for your domain at random among a list of matching domain names. This was picking an expired previous certificate, so I fixed it to filter out any unusable certificates. My PR was quickly and politely merged. Always a positive sign.
Waiting / Notifications
The aforementioned deploy command tells you when it’s done. Then you can test it out right away. You can speed it by only deploying a specific function, or using the S3 accelerate option to speed up uploading of your artifacts. Don’t waste time deploying stuff you don’t need or watching the CodeStar web UI.
Invoking Functions
AWS SAM is pretty easy, and so is Serverless. If developing a python webapp with the serverless-wsgi plugin, you can also serve your app up locally.
Managing Dependencies
(This part is python-specific)
How to manage dependencies for your python lambda? Well, just stick them in requirements.txt. Duh, right? With Serverless, more or less right. Remember that any dependencies have to be bundled in your lambda’s zip file. Need to build binary dependencies and not on a linux amd64 platform? Just add “dockerizePip: true” to the serverless-python-requirements plugin configuration in serverless.yml and you’re good to go.
Note that if invoking functions locally or starting the WSGI server, you still need a local virtualenv. One wacky non-Serverless template I looked at used pipenv instead to manage both local and lambda dependencies, but I couldn’t advise it; it’s pretty weaksauce.
Extending Serverless
Mostly what I’ve been doing with AWS Lambda is making small web API services using Python and the Flask microframework. With serverless providing exactly the tooling I need, I also want to be able to start new projects with a minimum of effort and have some pieces already in place that I can build on for my application.
I forked a serverless-flask template I found and started building on top of it. I made it not ask if you want to use python 2 or 3 (why not ask if I want UTF-8 or EBCDIC while you’re at it?) and defaulted dockerizing pip to false.
If building an API server in Flask, your life can be made much nicer with the addition of marshmallow to handle serializing and deserializing requests, flask-apispec to integrate marshmallow with OpenAPI (“swagger”) and Flask, and CORS. My version of the template includes all of this to make it as easy as humanly possible to make a documented serverless python REST API with the absolute minimal amount of effort and typing. And as a bonus it generates client libraries for your API from the OpenAPI definition in any language you desire.
Instructions for using the template and getting started quickly can be found here.
Serverless? Why Not
This article is a marker in the path our journey so far has taken us. Improving how we build applications and services is an ongoing process. Our previous milestone was unassisted AWS services, this present adventure was improved tooling for those services, and the next level to up may be AWS Amplify and GraphQL. Or maybe not. Stay tuned.
This is the first part of a series on serverless development with Python. Next part.
Serverless applications are great from the perspective of a developer – no infrastructure to manage, automatically scaling to meet requests without ever having to think about it, pay by the RAM gigabyte/second, and the ability to deploy via code however you desire. Logging comes free. For DevOps folks it’s a nightmare, as it represents the rapidly approaching obsolescence of their skills involving setting up web servers, load balancing, monitoring, logging, hanging out in datacenters, and other such quaint aspects of deploying web applications. Making a traditional web application run on AWS Lambda is not quite trivial yet, but is well worth understanding and considering next time you need a web service somewhere and it will surely get smoother and easier with time.
Oh yeah, what’s serverless mean here? It means you don’t manage any servers or long-lived processes. You put code in the cloud, and you run it whenever you want, however much you want, and don’t have to worry about the scaling part, while paying for only the CPU, memory, network traffic, and other services you consume. It’s a completely different way of deploying an application compared to managing daemons and servers and infrastructure and load balancing and all fun stuff that has very little to do with the code you want to write and deploy.
Python And Flask
There’s no shortage of options for web frameworks, and you can do a lot worse than Python 3 with Flask. Flask is a nice mixture of being able to create a simple web service with very little boilerplate, but also can also be used as a component for building more complex web applications, with the caveat that it’s more suited to APIs rather than server-side rendered apps when compared with something like Django. You should probably be writing single-page apps these days anyway.
Python is a very well-supported, readable, maintainable language with a vast amount of libraries available on the python module index. If you take the time to set up lint with mypy and flake8 you can even have some up-front checking of types and common mistakes. And it’s supported by AWS Lambda.
What A Serverless Flask Application Looks Like
To build a serverless Lambda application you should have a CloudFormation configuration template that describes your architecture.
The Lambda itself is one piece of this architecture; it is a function that can be invoked and can return a result. To use it as a web service, there needs to be a way to reach it from the web. AWS provides the API Gateway service which can listen for HTTP(S) requests on an endpoint and do something when requested. APIGW can either have an entry for each endpoint you desire (POST /api/foo, GET /api/bar, etc…) or it can proxy any request at a given host and path prefix to a Lambda and then interpret the response as an HTTP response to send back to the requestor. In this way it works like CGI or WSGI, and as long as your web framework knows how to deserialize an API Gateway proxy request and then serialize the response back into the format the APIGW expects, it can appear as any other web application “container” to your app.
There is a very simple Flask extension for this – AWSGI. The example there shows everything you need to do to make a web application that runs as a serverless app:
The only thing that is really Lambda-specific is the lambda_handler, which gives Flask the WSGI request object it expects and then translates the response appropriately into the format AWSGI expects.
So between the Lambda hosting your application code and the API Gateway acting as its reverse proxy, your infrastructure is pretty clear at this point. There are some associated bits needed like IAM permissions and the like, and maybe a database or S3 bucket or whatever else your app requires. This can all be specified in the CloudFormation template.
AWS has CloudFormation “transforms” that simplify this configuration by providing templated resources for your template to use. Templates on templates is a truly auspicious way to declare configuration. You will harness more slack than you had previously dreamed possible.
Resources:
HelloWorldFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: hello_world/build/
Handler: app.lambda_handler
Runtime: python3.6
Events:
HelloWorld:
Type: Api
Properties:
Path: /hello
Method: get
This gives you a Lambda that runs code uploaded to a S3 bucket when invoked at /hello.
Deployment
Deployment is not yet quite as smooth as say, deploying your application to Heroku, but it is getting there. There do exist some popular tools for doing serverless orchestration like Serverless Framework but I’ve been trying to see how far I can get just using AWS’s native tooling.
AWS has a service that I think no one but myself has actually used called CodeStar. This sets up a serverless deployment pipeline for you automatically, configuring CodePipeline, CodeBuild, and CloudFormation to give you an entire CI/CD system. You can easily configure it to run a build every time you check something into a GitHub repo, and update a CloudFormation deployment automatically. In addition, it even has another level of template laziness in the form of the CodeStar CloudFormation transform.
The documentation on CodeStar and the transform is more or less non-existent, which makes it actually kind of a special challenge to use. However it does appear to take care of the step of uploading your code to an S3 bucket and providing some roles. Your CodeStar template.yml may look something like:
If you create a repository with the file myapp/index.py, with a lambda_handler function like the AWSGI handler previously shown, then you now have a serverless web application that will be updated every time you push to your GitHub repo and CodeBuild passes.
Note that CodeStar may have the potential to make developing serverless applications as easy as Heroku with the power of everything you get from AWS and CloudFormation, but it definitely feels today like something no one has actually tried to use. I attempted to add an IAM role to my Lambda function and I managed to stump AWS support. They finally admitted to me that there is no documented way to customize the IAM role:
“After some further testing and research into this I found that you cannot currently customize the serverless Lambda function’s IAM Role from the template.yml.
Instead, you will need to manually add the desired permissions to the IAM Role directly. As you pointed out though, the Lambda function’s role is created automatically and you do not have insight into how to identify the IAM Role being used.”
There is a workaround involving deducing how the role name is derived in the CodeStar transform (which is a rather opaque and mystical bit of machinery) and adding permissions to it, but as far as I’m aware none of this is really supported or documented. They said they plan to fix it though.
You absolutely do not have to use CodeStar for deploying Lambdas, but if you relish a little bit of a challenge with some of the more esoteric AWS services it can be a valuable tool depending on your needs. There’s always some satisfaction at watching unloved AWS services grow and mature over the years (CodeDeploy…) and you can tell war stories about arguing with AWS support reps for months on a single ticket.
Speaking of which, when I tried using CodeBuild for running tests for my project they didn’t have a python 3.6 image, making that tool completely useless. Looks like they have one now though, so maybe not useless anymore.
Other Deployment Options
If you really just want to whip up a quick Lambda, you really don’t need a whole CI/CD system or CloudFormation of course. If you just want to write some code and run it and then not worry about it anymore, you can set it all up manually as a one-off function. I do this for some things like Slack bots and random little web services. I use Sublime Text 3 with an AWS Lambda editor plugin that I made. It lets you edit a Lambda directly from within Sublime, and uploads a new version whenever you hit save. It lets you invoke it and view the output within Sublime, and it has a handy shortcut for adding dependencies via pip to your project. It’s incredibly simple and vastly superior to using the web-based function editor, or unzipping and rezipping your bundle every time you want to modify the code.
Dependencies
Your Lambda is actually just distributed as a zip file of a directory. Into this directory goes your application code as well as any data files or dependencies it needs, along with your hopes and dreams. If you depend on other libraries (besides boto3, which Lambda already has for your convenience), you need to include them.
For a simple deployment, you can copy in libraries installed into a virtualenv for your project. If the libraries include native code, you must compile it on a linux amd64 machine because that’s what Lambda runs on. Some tools automate this with docker.
If you want something a little more friendly to use, you can set up a directory to stuff things in.
For my project, I made a dumb little “local pip” script that I can use to install packages with pip into a directory (“vendor/”). It’s nothing special or fancy. Just runs “pip install -t …” and deletes some unnecessary files afterwards.
In my application’s __init__.py file at the top I add vendor and the root path to PYTHONPATH, sort of giving me a mini-venv where I can just use any module installed to vendor/:
And then any dependencies I package up can be imported easily.
Putting It Together
To experiment with CodeStar and serverless Flask I made a simple web application. It lets people ask a question or answer a question. It was created initially as a Slack app, although that didn’t quite go as I hoped.
An Aside: My goal was to allow anyone on Slack to receive the questions and answer them, but as I had it only hooked up to a Slack team full of trolls and degenerates the Slack app reviewer was extremely unimpressed with the quality and thoughtfulness of the responses he got when testing it. Which is entirely my fault, but whatever. It’s still available on the Slack app repository but since they wouldn’t permit it to work across teams (something about not being “appropriate for the workplace”?) the Slack interface is of limited usefulness.
Anywhoozlebee, the application is a simple one: allow users to ask questions, or respond to questions. It was implemented first as a web service compatible with the Slack webhooks and Slashcommand HTTP APIs, and then later as a REST API for the web.
If this was a serious project I would use PostgreSQL for a database, but in addition to trying to teach myself how to best design a serverless Flask application, I also wanted to spend as little money as possible hosting it. Unfortunately PostgreSQL is not exactly serverless at this point in time, and you can expect to spend at least tens of dollars a month on AWS if you want a PostgreSQL server on anything except a free tier micro EC2 instance. So I decided to try using AWS’s DynamoDB nosql… thing. It’s a pretty unpleasant key-value store and the boto3 documentation is written by a sadist, but it is cheap and can also scale a lot without having to care much. In theory anyway. Though apparently it sucks?
DynamoDB costs a few bucks a month for tables and indexes, although you can probably get by with one or two if you don’t try to do things like you would in a relational database. Between that and a million requests and 400,000 GB-seconds of compute time a month for free for Lambda, you can have some code run and a place to store data for peanuts. And it should scale horizontally without any effort or thought. I’m sure it’s not that simple in reality, but it’s nice to imagine. At least I never have to configure a webserver or administer a machine just to deploy a web application, and can do it on the (hella) cheap. One of the real values of serverless applications is the ability to just set something up once and then never worry about it again. If it works the first time, it’ll keep working. You don’t need to worry about disks dying or backups or dealing with traffic spikes or downtime. Sure AWS isn’t absolutely perfect but I sure trust them to keep my lambdas running day and night more than I trust most people, including myself. Especially including myself.
Secrets
With any application deployment, you will likely need to store some secrets. You don’t need to give your Lambda an AWS API key as it is invoked with an IAM role that you can grant access to the services it needs. For external services, you can use the AWS SSM Parameter Store. It just lets you store secrets and retrieve them if your role or user is granted permissions to read them. It’s a great place to store things like API keys and tokens.
Since we’re using Flask, we can easily integrate SSM Parameter Store with the Flask config.py:
import boto3
ssm = boto3.client('ssm')
def get_ssm_param(param_name: str, required: bool = True) -> str:
"""Get an encrypted AWS Systems Manger secret."""
response = ssm.get_parameters(
Names=[param_name],
WithDecryption=True,
)
if not response['Parameters'] or not response['Parameters'][0] or not response['Parameters'][0]['Value']:
if not required:
return None
raise Exception(
f"Configuration error: missing AWS SSM parameter: {param_name}")
return response['Parameters'][0]['Value']
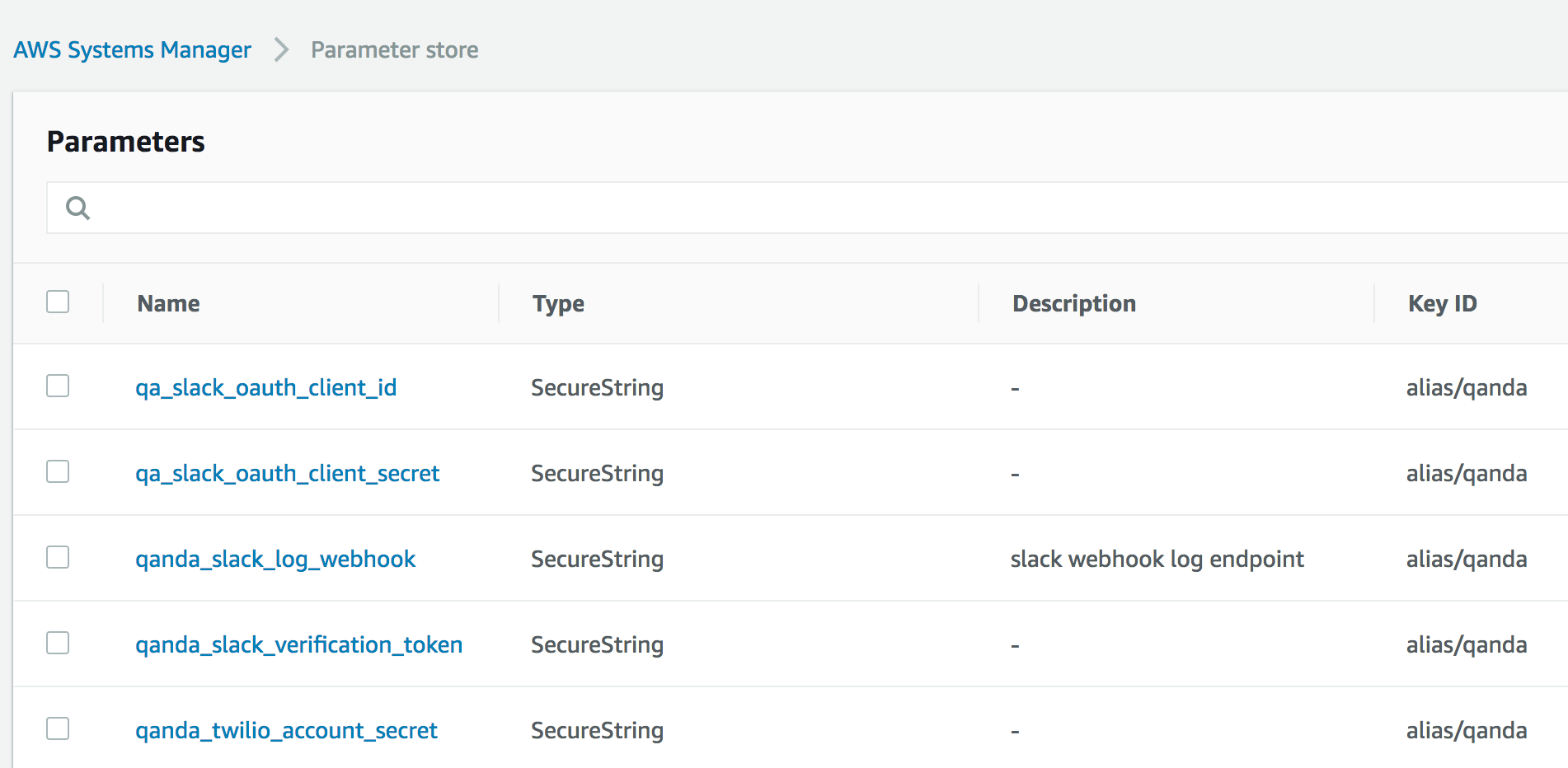
TWILIO_API_SID = get_ssm_param('qanda_twilio_account_sid')
TWILIO_API_SECRET = get_ssm_param('qanda_twilio_account_secret')
SLACK_OAUTH_CLIENT_ID = get_ssm_param('qa_slack_oauth_client_id')
SLACK_OAUTH_CLIENT_SECRET = get_ssm_param('qa_slack_oauth_client_secret')
SLACK_VERIFICATION_TOKEN = get_ssm_param('qanda_slack_verification_token')
SLACK_LOG_ENDPOINT = get_ssm_param('qanda_slack_log_webhook', required=False)
Secrets status: secreted.
Running Locally
Because Lambdas run inside of AWS, you might think that it would be very cumbersome to have to deploy and test every code change you make using AWS. And that would suck, if you actually had to do that. There’s an AWS project called SAM-CLI – Serverless Application Model Command Line Interface. Using docker Lambda images, you can invoke your application within the same environment it would be running under on Lambda. You can either feed it a JSON file describing a Lambda request and view the response, or you can start it up as a server that you can connect to like any other local development webserver. You do have to provide an AWS API key though if you want your app to make use of AWS services, as it’s running on your local machine and not under the auspices of an instance role in AWS.
Further Examples
In summary the above are considerations that are necessary for creating and deploying a serverless web application. I’m pretty pleased with the way everything fit together in my learning project QandA and I invite you to look at the project structure and source code for a complete working example. There are some more details I could go into about how I structured the Flask application, but they aren’t really Lambda- or serverless-specific and if you’re interested, really just check out the code.
Serverless API
Lambda is still in the early days and far from mature, and not yet as easy to work with as Heroku. But there is a high upside to being able to just have “code running in the cloud” without having to think about it or manage any server, and for basically free. Once you’ve taken the small amount of effort to set up a serverless application, you’re rewarded with an easy way to run code on the internet without having to worry about anything below the level of “request -> application code -> response”. I prefer worrying about code and configuration files over managing infrastructure and servers.
What kinds of professionals spend their days reading, writing, and editing rules? Two kinds: lawyers and computer programmers. Despite this fundamental similarity, however, they seem to live in different worlds. That’s probably because lawyers mistakenly think that programmers don’t have much to teach them (and, as a consequence, because programmers try to stay very, very far away from lawyers). In fact, though, lawyers could learn a lot from coders.
Computer code and legal code are similar in more than a few respects. Both declare operations to be performed under specific sets of conditions, attempt to create definitions that correspond to human activity, incorporate and revise previously-written code, and (hopefully) account for exceptional circumstances. While there are a great many differences as well, there may yet be an opportunity for cross-pollinating knowledge and experience from one field to the other.
Legal systems resemble pre-1970’s software in terms of portability and reusability. Much like how programs and operating systems were bespoke designed unique for each architecture, governance and codes of laws are currently crafted for each environment or government and unable to build upon each other, despite performing very similar functions.
Modern software developers are aware of the recent explosion of new ideas, experimentation, forms of organization and impressive decentralized projects that came with the introduction of suitable layers of abstraction and portability in the form of C and UNIX and later combined with the open source movement and the internet. By freeing programmers from having to rewrite operating systems that did more or less the same thing but with different interfaces, they could focus on actually writing programs, and even port those programs to different computer architectures without having to rewrite the entire application. Instead of writing code in an assembly language that was incompatible with all other platforms, the introduction of a higher-level language allowed programs to be transferred from one environment to another.
While some members of the software profession may take this wonderful state of affairs for granted in the digital realm, in the offline world they live under systems of laws and governance that are still waiting for a common framework, a standardized legal operating system, a basic foundation that hobbyists and experts from different countries and disciplines can openly collaborate on. Many of us may have vague desires and ideas of how to share the lessons learned from portable computer systems with the legal profession, though such ideas are likely worth their weight in gold Dunning-Krugerrands. Now however, a few in the legal profession have attempted to apply these concepts to law.
But first, an explanation of the problem: many people are unsatisfied with aspects of the governments and legal systems they live under, and most people have little agency to come up with their own improvements. There is a high exit cost to changing countries, citizenship, and governments. Improvements and refinements from one jurisdiction cannot always be easily taken and applied to another because of incompatible legal systems, different definitions, unintelligible languages, and jurisprudence. The overhead of experimentation can be great; each new government writes its constitution from scratch, comes up with court systems, has its own legislatures and judges, and so on. This limits the scope for the sort of healthy robust competition and innovation that has been seen in the world of software since the introduction of portable programs and operating systems, open-source development, reusable libraries, and collaboration on a global scale.
Perhaps you would like to create a new set of codes for yourself and like-minded individuals to live by. Maybe you believe laws or punishments are unfair or unjust, or you certain immoral or unsavory behavior should be curtailed. Taxes should go to fund socially useful schemes or taxes are too damn high. Freedom of movement is a basic human right or we need to keep the bad guys out. Whatever your vision, there are practical and theoretical ways of implementing it today, be it via homeowner associations, Special Economic Zones, setting up your own seasteading colony in international waters, founding a religion, or incorporating a new town. There exists a vast number of overlapping codes and laws that govern all people already, but they often lack a shared foundation of well-understood, time-tested common principles. Enter Ulex.
What is Ulex?
In a nutshell, Ulex provides a set of sane legal defaults including a simple system for resolving disputes closely modeled on the system commonly used to arbitrate international trading disputes. There are recommended basic modules for civil procedure, torts, contracts, and property that incorporate best practices as codified by organizations including the American Law Institute/International Institute for the Unification of Law’s (ALI/UNIDROIT’s) Principles of Transnational Civil Procedure, and selected volumes from The ALI’s Restatements of the Law.
Ulex 1.1 can be viewed as a template for creating a legal distribution. It references the contents of the legal packages from quality upstream maintainers, along with some system utilities in the form of meta-rules, optional modules for criminal law, procedural rules and substantive rules. This distribution should not be considered final, complete, or the best legal system for any new self-governing group of people, but rather a starting point for experimentation. Since not everyone who wishes to create a new society is well versed in legal history and modern best practices, having a jumping-off point with quality material curated by a law professor should be useful. Not everyone wanting to build applications may know how to design a working operating system, and they shouldn’t have to.
Creating legal systems by means of references other documents is a common and systematic practice, much in the way that software is rarely written from scratch but instead makes use of libraries of already packaged code. So too can legal distributions be created with a few well-thought references to systems that already work well and some legal wording glue to create a coherent system. Implementation is accomplished via contract law in the context of the host state, a necessary bootstrapping mechanism for now. Ulex version 1.1 includes an optional host sovereign integration module (section 5) if better compatibility is desired.
All that is needed for implementation is for parties to formally agree:
Only Ulex 1.1 shall govern any claim or question arising under or related to this agreement, including the proper forum for resolving disputes, all rules applied therein, and the form and effect of any judgment.
Ulex is not the final answer in self-organizing legal systems but a potential first organizing principle and base layer of abstraction upon which more varied and ambitious legal projects can be based. If a common template and minimum functioning system can be designed, the process and results can be embraced and extended around the world as people increasingly experiment with new forms and options for self-governance. With competing designs and implementations may come, eventually, more inspired and community-driven legal systems all developed in the finest tradition of open source development.